VoiceprintRecognition Pytorch
1.0.0
ภาษาจีนง่ายๆ | ภาษาอังกฤษ
สาขานี้คือเวอร์ชัน 1.1 หากคุณต้องการใช้เวอร์ชันก่อนหน้า 1.0 โปรดใช้ในสาขา 1.0 โครงการนี้ใช้รูปแบบการจดจำเสียงขั้นสูงหลายแบบเช่น Ecapatdnn, Resnetse, ERES2NET และ CAM ++ มันไม่ได้ถูกตัดออกว่าจะได้รับการสนับสนุนแบบจำลองเพิ่มเติมในอนาคต ในขณะเดียวกันโครงการนี้ยังรองรับวิธีการประมวลผลข้อมูลล่วงหน้าเช่น Melspectrogram, Spectrogram, MFCC และ FBANK การสูญเสีย Arcface, การสูญเสีย Arcface: การสูญเสียส่วนต่างของเชิงมุม (ฟังก์ชั่นการสูญเสียช่วงเวลาของมุมเติม), สอดคล้องกับ aamloss ในโครงการทำให้ eigenvectors และน้ำหนักเป็นปกติและเพิ่มช่วงมุม M ถึงθ ช่วงเวลามุมมีผลกระทบโดยตรงต่อมุมมากกว่าช่วงเวลาของโคไซน์ นอกจากนี้ยังสนับสนุนฟังก์ชั่นการสูญเสียต่าง ๆ เช่น Amloss, Armloss และ Celoss
หากโครงการนี้เป็นประโยชน์กับคุณดาราต้อนรับเพื่อหลีกเลี่ยงการไม่พบในภายหลัง
ทุกคนยินดีที่จะสแกนรหัสเพื่อเข้าสู่ Planet หรือกลุ่ม QQ เพื่อหารือ ความรู้ Planet จัดเตรียมไฟล์โมเดลโครงการและโครงการอื่น ๆ ที่เกี่ยวข้องกับโครงการรวมถึงทรัพยากรอื่น ๆ
สภาพแวดล้อมการใช้งาน:
กระดาษรุ่น:
| แบบอย่าง | params (M) | ชุดข้อมูล | ลำโพงรถไฟ | เกณฑ์ | Eer | mindcf | ดาวน์โหลดรุ่น |
|---|---|---|---|---|---|---|---|
| ERES2NETV2 | 6.6 | CN-CELEB | 2796 | 0.20089 | 0.08071 | 0.45705 | เข้าร่วม Planet ความรู้เพื่อรับ |
| eres2net | 6.6 | CN-CELEB | 2796 | 0.20014 | 0.08132 | 0.45544 | เข้าร่วม Planet ความรู้เพื่อรับ |
| CAM ++ | 6.8 | CN-CELEB | 2796 | 0.23323 | 0.08332 | 0.48536 | เข้าร่วม Planet ความรู้เพื่อรับ |
| รม | 7.8 | CN-CELEB | 2796 | 0.19066 | 0.08544 | 0.49142 | เข้าร่วม Planet ความรู้เพื่อรับ |
| ecapatdnn | 6.1 | CN-CELEB | 2796 | 0.23646 | 0.09259 | 0.51378 | เข้าร่วม Planet ความรู้เพื่อรับ |
| tdnn | 2.6 | CN-CELEB | 2796 | 0.23858 | 0.10825 | 0.59545 | เข้าร่วม Planet ความรู้เพื่อรับ |
| res2net | 5.0 | CN-CELEB | 2796 | 0.19526 | 0.12436 | 0.65347 | เข้าร่วม Planet ความรู้เพื่อรับ |
| CAM ++ | 6.8 | ชุดข้อมูลขนาดใหญ่ | 2w+ | 0.33 | 0.07874 | 0.52524 | เข้าร่วม Planet ความรู้เพื่อรับ |
| eres2net | 55.1 | ชุดข้อมูลอื่น ๆ | 20W+ | 0.36 | 0.02936 | 0.18355 | เข้าร่วม Planet ความรู้เพื่อรับ |
| ERES2NETV2 | 56.2 | ชุดข้อมูลอื่น ๆ | 20W+ | 0.36 | 0.03847 | 0.24301 | เข้าร่วม Planet ความรู้เพื่อรับ |
| CAM ++ | 6.8 | ชุดข้อมูลอื่น ๆ | 20W+ | 0.29 | 0.04765 | 0.31436 | เข้าร่วม Planet ความรู้เพื่อรับ |
ภาพประกอบ:
speed_perturb_3_class: TrueFbank และฟังก์ชั่นการสูญเสียคือ AAMLoss| แบบอย่าง | params (M) | ชุดข้อมูล | ลำโพงรถไฟ | เกณฑ์ | Eer | mindcf | ดาวน์โหลดรุ่น |
|---|---|---|---|---|---|---|---|
| CAM ++ | 6.8 | voxceleb1 & 2 | 7205 | 0.22504 | 0.02436 | 0.15543 | เข้าร่วม Planet ความรู้เพื่อรับ |
| ecapatdnn | 6.1 | voxceleb1 & 2 | 7205 | 0.24877 | 0.02480 | 0.16188 | เข้าร่วม Planet ความรู้เพื่อรับ |
| ERES2NETV2 | 6.6 | voxceleb1 & 2 | 7205 | 0.20710 | 0.02742 | 0.17709 | เข้าร่วม Planet ความรู้เพื่อรับ |
| eres2net | 6.6 | voxceleb1 & 2 | 7205 | 0.20233 | 0.02954 | 0.17377 | เข้าร่วม Planet ความรู้เพื่อรับ |
| รม | 7.8 | voxceleb1 & 2 | 7205 | 0.22567 | 0.03189 | 0.23040 | เข้าร่วม Planet ความรู้เพื่อรับ |
| tdnn | 2.6 | voxceleb1 & 2 | 7205 | 0.23834 | 0.03486 | 0.26792 | เข้าร่วม Planet ความรู้เพื่อรับ |
| res2net | 5.0 | voxceleb1 & 2 | 7205 | 0.19472 | 0.04370 | 0.40072 | เข้าร่วม Planet ความรู้เพื่อรับ |
| CAM ++ | 6.8 | ชุดข้อมูลขนาดใหญ่ | 2w+ | 0.28 | 0.03182 | 0.23731 | เข้าร่วม Planet ความรู้เพื่อรับ |
| eres2net | 55.1 | ชุดข้อมูลอื่น ๆ | 20W+ | 0.53 | 0.08904 | 0.62130 | เข้าร่วม Planet ความรู้เพื่อรับ |
| ERES2NETV2 | 56.2 | ชุดข้อมูลอื่น ๆ | 20W+ | 0.52 | 0.08649 | 0.64193 | เข้าร่วม Planet ความรู้เพื่อรับ |
| CAM ++ | 6.8 | ชุดข้อมูลอื่น ๆ | 20W+ | 0.49 | 0.10334 | 0.71200 | เข้าร่วม Planet ความรู้เพื่อรับ |
ภาพประกอบ:
speed_perturb_3_class: TrueFbank และฟังก์ชั่นการสูญเสียคือ AAMLoss| วิธีการประมวลผลล่วงหน้า | ชุดข้อมูล | ลำโพงรถไฟ | เกณฑ์ | Eer | mindcf | ดาวน์โหลดรุ่น |
|---|---|---|---|---|---|---|
| ฟ็อกแบงก์ | CN-CELEB | 2796 | 0.14574 | 0.10988 | 0.58955 | เข้าร่วม Planet ความรู้เพื่อรับ |
| MFCC | CN-CELEB | 2796 | 0.14868 | 0.11483 | 0.61275 | เข้าร่วม Planet ความรู้เพื่อรับ |
| สเปคโตรรัม | CN-CELEB | 2796 | 0.14962 | 0.11613 | 0.60057 | เข้าร่วม Planet ความรู้เพื่อรับ |
| Melspectrogram | CN-CELEB | 2796 | 0.13458 | 0.12498 | 0.60741 | เข้าร่วม Planet ความรู้เพื่อรับ |
| wavlm-base-plus | CN-CELEB | 2796 | 0.14166 | 0.13247 | 0.62451 | เข้าร่วม Planet ความรู้เพื่อรับ |
| W2V-BERT-2.0 | CN-CELEB | 2796 | เข้าร่วม Planet ความรู้เพื่อรับ | |||
| WAV2VEC2-Large-XLSR-53 | CN-CELEB | 2796 | เข้าร่วม Planet ความรู้เพื่อรับ | |||
| มีขนาดใหญ่ | CN-CELEB | 2796 | เข้าร่วม Planet ความรู้เพื่อรับ |
ภาพประกอบ:
CAM++ และฟังก์ชั่นการสูญเสียคือ AAMLossextract_features.py เพื่อแยกคุณสมบัติล่วงหน้าซึ่งหมายความว่าไม่ได้ใช้การปรับปรุงข้อมูลไปยังเสียงในระหว่างการฝึกอบรมw2v-bert-2.0 , wav2vec2-large-xlsr-53 นั้นได้มาจากการฝึกอบรมก่อนการฝึกอบรมหลายภาษา ข้อมูลการฝึกอบรมล่วงหน้าของ wavlm-base-plus และ wavlm-large นั้นเป็นภาษาอังกฤษเท่านั้น| ฟังก์ชันการสูญเสีย | ชุดข้อมูล | ลำโพงรถไฟ | เกณฑ์ | Eer | mindcf | ดาวน์โหลดรุ่น |
|---|---|---|---|---|---|---|
| aamloss | CN-CELEB | 2796 | 0.14574 | 0.10988 | 0.58955 | เข้าร่วม Planet ความรู้เพื่อรับ |
| Sphereface2 | CN-CELEB | 2796 | 0.20377 | 0.11309 | 0.61536 | เข้าร่วม Planet ความรู้เพื่อรับ |
| Tripletangularmarginloss | CN-CELEB | 2796 | 0.28940 | 0.11749 | 0.63735 | เข้าร่วม Planet ความรู้เพื่อรับ |
| ส่วนย่อย | CN-CELEB | 2796 | 0.13126 | 0.11775 | 0.56995 | เข้าร่วม Planet ความรู้เพื่อรับ |
| armlloss | CN-CELEB | 2796 | 0.14563 | 0.11805 | 0.57171 | เข้าร่วม Planet ความรู้เพื่อรับ |
| อมตะ | CN-CELEB | 2796 | 0.12870 | 0.12301 | 0.63263 | เข้าร่วม Planet ความรู้เพื่อรับ |
| celoss | CN-CELEB | 2796 | 0.13607 | 0.12684 | 0.65176 | เข้าร่วม Planet ความรู้เพื่อรับ |
ภาพประกอบ:
CAM++ และวิธีการประมวลผลล่วงหน้าคือ Fbankextract_features.py เพื่อแยกคุณสมบัติล่วงหน้าซึ่งหมายความว่าไม่ได้ใช้การปรับปรุงข้อมูลไปยังเสียงในระหว่างการฝึกอบรม conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaใช้ PIP เพื่อติดตั้งคำสั่งมีดังนี้:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleขอแนะนำให้ติดตั้งซอร์สโค้ด ซึ่งสามารถมั่นใจได้ว่าการใช้รหัสล่าสุด
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . ผู้เขียนใช้ CN-CELEB ในบทช่วยสอนนี้ ชุดข้อมูลนี้มีข้อมูลเสียงทั้งหมดประมาณ 3,000 ข้อมูลและข้อมูลเสียง 65W+ หลังจากดาวน์โหลดคุณจะต้องคลายข้อมูลชุดข้อมูลไปยังไดเรกทอรี dataset นอกจากนี้หากคุณต้องการประเมินคุณต้องดาวน์โหลดชุดทดสอบ CN-CELEB หากผู้อ่านมีชุดข้อมูลที่ดีกว่าอื่น ๆ ก็สามารถผสมเข้าด้วยกันได้ แต่เป็นการดีที่สุดที่จะใช้โมดูลเครื่องมือของ Python Aukit เพื่อประมวลผลเสียงการลดเสียงรบกวนและการปิดเสียง
อย่างแรกคือการสร้างรายการข้อมูล รูปแบบของรายการข้อมูลคือ <语音文件路径t语音分类标签> การสร้างรายการนี้เป็นหลักเพื่อความสะดวกในการอ่านในภายหลังและความสะดวกในการอ่านโดยใช้ชุดข้อมูลเสียงอื่น ๆ แท็กการจำแนกประเภทเสียงอ้างถึงรหัสที่ไม่ซ้ำกันของลำโพง ชุดข้อมูลเสียงที่แตกต่างกันสามารถเขียนในรายการข้อมูลเดียวกันโดยการเขียนฟังก์ชั่นที่สอดคล้องกันเพื่อสร้างรายการข้อมูล
ดำเนินการโปรแกรม create_data.py เพื่อเตรียมข้อมูลให้เสร็จสมบูรณ์
python create_data.pyหลังจากดำเนินการโปรแกรมข้างต้นรูปแบบข้อมูลต่อไปนี้จะถูกสร้างขึ้น หากคุณต้องการปรับแต่งข้อมูลโปรดดูรายการข้อมูลต่อไปนี้ ด้านหน้าเป็นเส้นทางสัมพัทธ์ของเสียงและด้านหลังเป็นฉลากของลำโพงที่สอดคล้องกับเสียงซึ่งเหมือนกับการจำแนกประเภท โปรดทราบว่า ID ของรายการข้อมูลการทดสอบไม่จำเป็นต้องเป็นเช่นเดียวกับ ID การฝึกอบรมซึ่งหมายความว่าผู้พูดข้อมูลการทดสอบอาจไม่จำเป็นต้องปรากฏในชุดการฝึกอบรมตราบใดที่บุคคลเดียวกันในรายการข้อมูลทดสอบมั่นใจว่าบุคคลเดียวกันมี ID เดียวกัน
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
วิธีการประมวลผลล่วงหน้า FBANK เริ่มต้นใช้ในไฟล์การกำหนดค่า หากคุณต้องการใช้วิธีการประมวลผลล่วงหน้าอื่น ๆ คุณสามารถแก้ไขวิธีการติดตั้งในไฟล์การกำหนดค่า ค่าเฉพาะสามารถแก้ไขได้ตามสถานการณ์ของคุณเอง หากคุณไม่แน่ใจว่าจะตั้งค่าพารามิเตอร์อย่างไรคุณสามารถลบส่วนนี้ได้โดยตรงและใช้ค่าเริ่มต้นโดยตรง
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80ในระหว่างกระบวนการฝึกอบรมสิ่งแรกคือการอ่านข้อมูลเสียงจากนั้นดึงคุณสมบัติและในที่สุดก็ทำการฝึกอบรม ในหมู่พวกเขาการอ่านข้อมูลเสียงและคุณสมบัติการแยกก็ใช้เวลานานดังนั้นเราจึงสามารถเลือกที่จะดึงคุณสมบัติล่วงหน้า หากเราฝึกอบรมแบบจำลองเราสามารถโหลดและแยกคุณสมบัติโดยตรงเพื่อให้ความเร็วในการฝึกอบรมจะเร็วขึ้น คุณลักษณะที่แยกออกมานี้เป็นตัวเลือก หากไม่มีการสกัดคุณสมบัติที่ดีรูปแบบการฝึกอบรมจะเริ่มต้นด้วยการอ่านข้อมูลเสียงแล้วแยกคุณสมบัติ ขั้นตอนในการแยกคุณสมบัติมีดังนี้:
extract_features.py เพื่อแยกคุณสมบัติ คุณสมบัติจะถูกบันทึกไว้ในไดเรกทอรี dataset/features และสร้างรายการข้อมูลใหม่ train_list_features.txt , enroll_list_features.txt และ trials_list_features.txt python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list , dataset_conf.enroll_list และ dataset_conf.trials_list ถึง train_list_features.txt , enroll_list_features.txt และ trials_list_features.txt การใช้ train.py เพื่อฝึกอบรมโมเดลโครงการนี้รองรับวิธีการประมวลผลเสียงหลายวิธี พารามิเตอร์ preprocess_conf.feature_method ของไฟล์กำหนด configs/ecapa_tdnn.yml สามารถระบุไฟล์การกำหนดค่าได้ MelSpectrogram เป็นสเปกตรัม MEL, Spectrogram เป็นกราฟสเปกตรัม, MFCC MEL สเปกตรัม CEPSpectral สัมประสิทธิ์ ฯลฯ วิธีการเพิ่มประสิทธิภาพข้อมูลสามารถระบุได้โดยพารามิเตอร์ augment_conf_path ในระหว่างกระบวนการฝึกอบรม VisualDL จะถูกใช้เพื่อบันทึกบันทึกการฝึกอบรม โดยการเริ่มต้น VisualDL คุณสามารถดูผลการฝึกอบรมได้ตลอดเวลา คำสั่ง startup visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyบันทึกเอาท์พุทการฝึกอบรม:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
เริ่ม VisualDl: visualdl --logdir=log --host 0.0.0.0 หน้า VisualDl มีดังนี้:
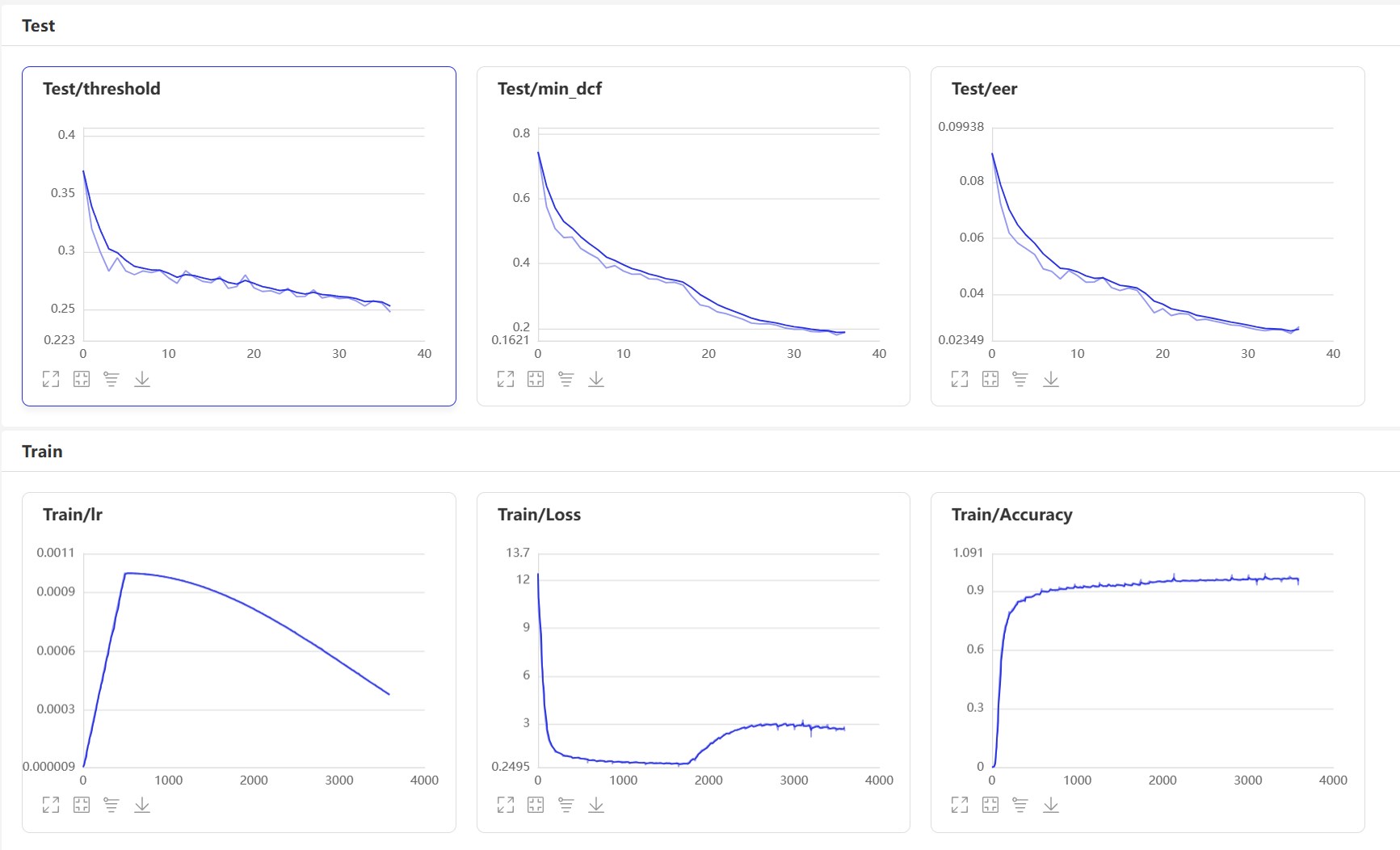
หลังจากการฝึกอบรมรูปแบบการทำนายจะถูกบันทึกไว้ เราใช้แบบจำลองการทำนายเพื่อทำนายคุณสมบัติเสียงในชุดทดสอบจากนั้นใช้คุณสมบัติเสียงเพื่อเปรียบเทียบเป็นคู่เพื่อคำนวณ EER และ MONDCF
python eval.pyเอาต์พุตคล้ายกับต่อไปนี้:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
นี่คืออินเทอร์เฟซที่ใช้กันทั่วไปหลายประการ สำหรับอินเทอร์เฟซเพิ่มเติมโปรดดูที่ mvector/predict.py นอกจากนี้คุณยังสามารถดูตัวอย่างของ声纹对比声纹识别
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) มาเริ่มการเปรียบเทียบ VoicePrint และสร้างโปรแกรม infer_contrast.py ก่อนอื่นเราแนะนำฟังก์ชั่นสำคัญหลายประการ ฟังก์ predict() สามารถรับคุณสมบัติ VoicePrint ได้ predict_batch() สามารถรับคุณสมบัติของ VoicePrint ได้ฟังก์ชั่น contrast() remove_user() เปรียบเทียบความคล้ายคลึงกันระหว่างสองเสียงฟังก์ชั่น recognition() register() ลงทะเบียนเสียงลงในห้องสมุดเสียง ลงทะเบียนในไลบรารี VoicePrint เราป้อนสองสุนทรพจน์และรับข้อมูลคุณสมบัติของพวกเขาผ่านฟังก์ชั่นการทำนาย การใช้ข้อมูลคุณสมบัตินี้เราสามารถค้นหาค่าโคไซน์แนวทแยงมุมและผลลัพธ์สามารถใช้เป็นความคุ้นเคย สำหรับ threshold การรับรู้นี้ผู้อ่านสามารถปรับเปลี่ยนได้ตามข้อกำหนดความถูกต้องของโครงการของพวกเขา
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavเอาต์พุตคล้ายกับต่อไปนี้:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
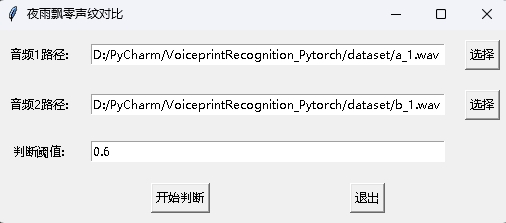
ในขณะเดียวกันก็มีโปรแกรมเปรียบเทียบเสียงที่มีอินเตอร์เฟส GUI ดำเนินการ infer_contrast_gui.py เพื่อเริ่มโปรแกรม อินเทอร์เฟซมีดังนี้ เลือกสองเสียงตามลำดับ คลิกเพื่อเริ่มตัดสินเพื่อพิจารณาว่าพวกเขาเป็นคนเดียวกันหรือไม่
ในการรับรู้ข่าวฟังก์ชั่น register() และฟังก์ชั่น recognition() ส่วนใหญ่จะใช้ ขั้นแรกให้ใช้ฟังก์ชั่น register() เพื่อลงทะเบียนเสียงลงในไลบรารี VoicePrint นอกจากนี้คุณยังสามารถเพิ่มไฟล์ลงในโฟลเดอร์ audio_db โดยตรง เมื่อใช้งานคุณสามารถเริ่มการจดจำผ่านฟังก์ชั่น recognition() ป้อนเสียงและคุณสามารถระบุลำโพงที่จำเป็นจากไลบรารี VoicePrint
ด้วยฟังก์ชั่นการจดจำเสียงข้างต้นผู้อ่านสามารถรับรู้การรับรู้ด้วยเสียงตามความต้องการของโครงการของตนเอง ตัวอย่างเช่นสิ่งที่ฉันให้ไว้ด้านล่างคือการจดจำเสียงผ่านการบันทึก ก่อนอื่นต้องโหลดเสียงในไลบรารีเสียง โฟลเดอร์ Voice Library เป็น audio_db จากนั้นผู้ใช้จะบันทึกเสียงเป็นเวลา 3 วินาทีหลังจากกดรถ จากนั้นโปรแกรมจะบันทึกเสียงโดยอัตโนมัติและใช้เสียงที่บันทึกไว้สำหรับการจดจำเสียงพากย์เพื่อให้ตรงกับเสียงในไลบรารีเสียงและรับข้อมูลผู้ใช้ ด้วยวิธีนี้ผู้อ่านยังสามารถปรับเปลี่ยนเพื่อให้การจดจำเสียงพากย์เสร็จสมบูรณ์ผ่านคำขอบริการเช่นให้ API สำหรับแอปโทร เมื่อผู้ใช้เข้าสู่ระบบผ่าน VoicePrint บนแอพเขาจะส่งเสียงที่บันทึกไปยังแบ็กเอนด์เพื่อรับการจดจำเสียงพากย์เสียงแล้วส่งคืนผลลัพธ์ไปยังแอพโดยที่ผู้ใช้ได้ลงทะเบียนกับ VoicePrint และเก็บข้อมูลเสียงในโฟลเดอร์ audio_db ได้สำเร็จ
python infer_recognition.pyเอาต์พุตคล้ายกับต่อไปนี้:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
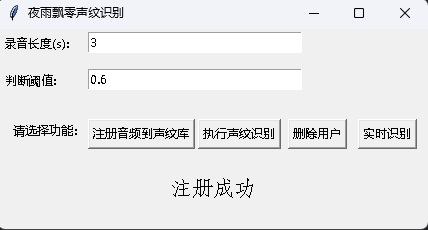
ในขณะเดียวกันก็มีโปรแกรมการจดจำเสียงที่มีอินเทอร์เฟซ GUI ดำเนินการ infer_recognition_gui.py เพื่อเริ่มคลิก注册音频到声纹库เข้าใจและเริ่มพูดบันทึกเป็นเวลา 3 วินาทีจากนั้นป้อนชื่อของผู้ลงทะเบียน หลังจากนั้นคุณสามารถ执行声纹识别แล้วพูดได้ทันที หลังจากบันทึกเป็นเวลา 3 วินาทีรอผลการรับรู้ ปุ่ม删除用户สามารถลบผู้ใช้ได้ ปุ่ม实时识别สามารถรับรู้ได้แบบเรียลไทม์และสามารถบันทึกและรับรู้ได้ตามเวลาจริง
ดำเนินการโปรแกรม infer_speaker_diarization.py ป้อนเส้นทางเสียงและคุณสามารถแยกลำโพงและแสดงผลลัพธ์ ขอแนะนำให้ความยาวเสียงไม่ควรน้อยกว่า 10 วินาที สำหรับฟังก์ชั่นเพิ่มเติมคุณสามารถดูพารามิเตอร์ของโปรแกรม
python infer_speaker_diarization.py --audio_path=dataset/test_long.wavเอาต์พุตคล้ายกับต่อไปนี้:
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
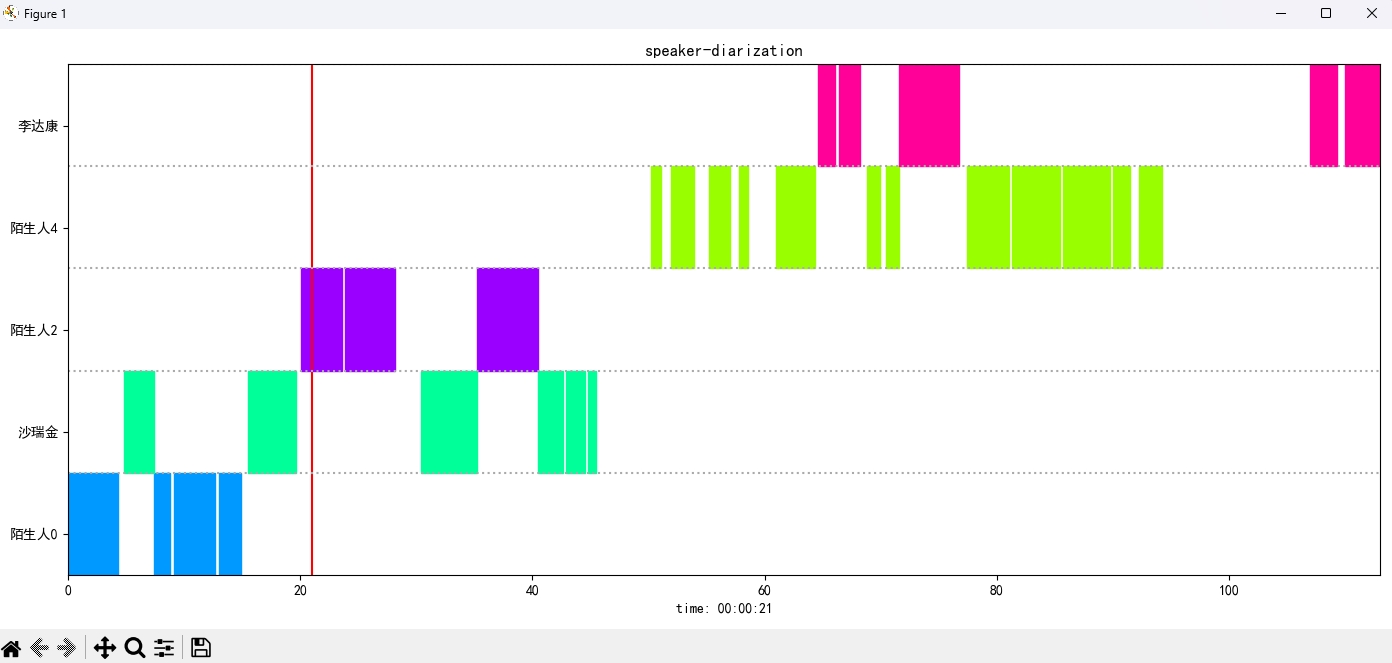
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
ภาพผลลัพธ์จะปรากฏขึ้นดังนี้ คุณสามารถควบคุมการเล่นเสียงผ่านแถบ空格คลิกตำแหน่งเพื่อข้ามไปยังตำแหน่งที่ระบุ:
โครงการยังมีโปรแกรมที่มีอินเทอร์เฟซ GUI โดยดำเนินการโปรแกรม infer_speaker_diarization_gui.py สำหรับฟังก์ชั่นเพิ่มเติมคุณสามารถดูพารามิเตอร์ของโปรแกรม
python infer_speaker_diarization_gui.pyคุณสามารถเปิดหน้าดังกล่าวเพื่อระบุลำโพง:
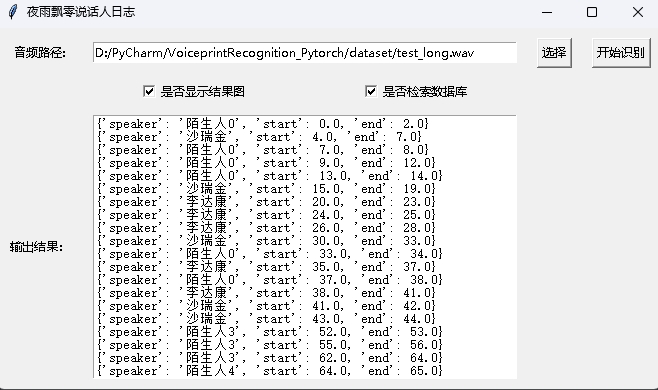
หมายเหตุ: หากชื่อของลำโพงเป็นภาษาจีนคุณจะต้องตั้งค่าฟอนต์การติดตั้งเพื่อแสดงตามปกติ โดยทั่วไปแล้ว Windows ไม่จำเป็นต้องติดตั้ง แต่จำเป็นต้องติดตั้ง Ubuntu หาก Windows หายไปอย่างแท้จริงคุณจะต้องดาวน์โหลดไฟล์รูปแบบ .ttf ที่นี่และคัดลอกไปยัง C:WindowsFonts การดำเนินการระบบ Ubuntu มีดังนี้
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )ให้รางวัลหนึ่งดอลลาร์เพื่อสนับสนุนผู้เขียน


