VoiceprintRecognition Pytorch
1.0.0
Упрощенный китайский | Английский
Эта ветвь версия 1.1. Если вы хотите использовать предыдущую версию 1.0, используйте ее в филиале 1.0. В этом проекте используются различные модели распознавания голосовой отпечатки, такие как Ecapatdnn, Resnetse, ERES2Net и CAM ++. Не исключено, что в будущем будет поддержано больше моделей. В то же время этот проект также поддерживает различные методы предварительной обработки данных, такие как Melspectrogram, Spectrogram, MFCC и FBANK. Потеря дуги, потеря дуги: потери аддитивного углового края (функция потери интервала аддитивного угла), соответствующая AAMLOSS в проекте, нормализует собственные векторы и веса и добавляет угла интервала M -интервал M к θ. Угольный интервал оказывает более прямое влияние на угол, чем косинусное интервал. Кроме того, он также поддерживает различные функции потерь, такие как Amloss, Armloss и Celoss.
Если этот проект полезен для вас, добро пожаловать звезду, чтобы избежать его не найти позже.
Каждый приветствует, чтобы обсудить код, чтобы ввести планету знаний или QQ. Planet Planet предоставляет файлы моделей проекта и другие модели модели, связанные с проектами, а также другие ресурсы.
Среда использования:
Модель бумага:
| Модель | Params (m) | Набор данных | Поезда динамики | порог | Погасить | Mindcf | Модель скачать |
|---|---|---|---|---|---|---|---|
| ERES2NETV2 | 6.6 | CN-CELEB | 2796 | 0,20089 | 0,08071 | 0,45705 | Присоединиться к планете знаний, чтобы получить |
| ERES2NET | 6.6 | CN-CELEB | 2796 | 0,20014 | 0,08132 | 0,45544 | Присоединиться к планете знаний, чтобы получить |
| CAM ++ | 6.8 | CN-CELEB | 2796 | 0,23323 | 0,08332 | 0,48536 | Присоединиться к планете знаний, чтобы получить |
| Resnetse | 7,8 | CN-CELEB | 2796 | 0,19066 | 0,08544 | 0,49142 | Присоединиться к планете знаний, чтобы получить |
| Ecapatdnn | 6.1 | CN-CELEB | 2796 | 0,23646 | 0,09259 | 0,51378 | Присоединиться к планете знаний, чтобы получить |
| Tdnn | 2.6 | CN-CELEB | 2796 | 0,23858 | 0,10825 | 0,59545 | Присоединиться к планете знаний, чтобы получить |
| Res2net | 5.0 | CN-CELEB | 2796 | 0,19526 | 0,12436 | 0,65347 | Присоединиться к планете знаний, чтобы получить |
| CAM ++ | 6.8 | Большой набор данных | 2W+ | 0,33 | 0,07874 | 0,52524 | Присоединиться к планете знаний, чтобы получить |
| ERES2NET | 55,1 | Другие наборы данных | 20 Вт+ | 0,36 | 0,02936 | 0,18355 | Присоединиться к планете знаний, чтобы получить |
| ERES2NETV2 | 56.2 | Другие наборы данных | 20 Вт+ | 0,36 | 0,03847 | 0,24301 | Присоединиться к планете знаний, чтобы получить |
| CAM ++ | 6.8 | Другие наборы данных | 20 Вт+ | 0,29 | 0,04765 | 0,31436 | Присоединиться к планете знаний, чтобы получить |
иллюстрировать:
speed_perturb_3_class: True .Fbank , а функция потери - AAMLoss .| Модель | Params (m) | Набор данных | Поезда динамики | порог | Погасить | Mindcf | Модель скачать |
|---|---|---|---|---|---|---|---|
| CAM ++ | 6.8 | Voxceleb1 и 2 | 7205 | 0,22504 | 0,02436 | 0,15543 | Присоединиться к планете знаний, чтобы получить |
| Ecapatdnn | 6.1 | Voxceleb1 и 2 | 7205 | 0,24877 | 0,02480 | 0,16188 | Присоединиться к планете знаний, чтобы получить |
| ERES2NETV2 | 6.6 | Voxceleb1 и 2 | 7205 | 0,20710 | 0,02742 | 0,17709 | Присоединиться к планете знаний, чтобы получить |
| ERES2NET | 6.6 | Voxceleb1 и 2 | 7205 | 0,20233 | 0,02954 | 0,17377 | Присоединиться к планете знаний, чтобы получить |
| Resnetse | 7,8 | Voxceleb1 и 2 | 7205 | 0,22567 | 0,03189 | 0,23040 | Присоединиться к планете знаний, чтобы получить |
| Tdnn | 2.6 | Voxceleb1 и 2 | 7205 | 0,23834 | 0,03486 | 0,26792 | Присоединиться к планете знаний, чтобы получить |
| Res2net | 5.0 | Voxceleb1 и 2 | 7205 | 0,19472 | 0,04370 | 0,40072 | Присоединиться к планете знаний, чтобы получить |
| CAM ++ | 6.8 | Большой набор данных | 2W+ | 0,28 | 0,03182 | 0,23731 | Присоединиться к планете знаний, чтобы получить |
| ERES2NET | 55,1 | Другие наборы данных | 20 Вт+ | 0,53 | 0,08904 | 0,62130 | Присоединиться к планете знаний, чтобы получить |
| ERES2NETV2 | 56.2 | Другие наборы данных | 20 Вт+ | 0,52 | 0,08649 | 0,64193 | Присоединиться к планете знаний, чтобы получить |
| CAM ++ | 6.8 | Другие наборы данных | 20 Вт+ | 0,49 | 0,10334 | 0,71200 | Присоединиться к планете знаний, чтобы получить |
иллюстрировать:
speed_perturb_3_class: True .Fbank , а функция потери - AAMLoss .| Метод предварительной обработки | Набор данных | Поезда динамики | порог | Погасить | Mindcf | Модель скачать |
|---|---|---|---|---|---|---|
| Фбанк | CN-CELEB | 2796 | 0,14574 | 0,10988 | 0,58955 | Присоединиться к планете знаний, чтобы получить |
| MFCC | CN-CELEB | 2796 | 0,14868 | 0,11483 | 0,61275 | Присоединиться к планете знаний, чтобы получить |
| Спектрограмма | CN-CELEB | 2796 | 0,14962 | 0,11613 | 0,60057 | Присоединиться к планете знаний, чтобы получить |
| Melspectrogram | CN-CELEB | 2796 | 0,13458 | 0,12498 | 0,60741 | Присоединиться к планете знаний, чтобы получить |
| Wavlm-Base-Plus | CN-CELEB | 2796 | 0,14166 | 0,13247 | 0,62451 | Присоединиться к планете знаний, чтобы получить |
| W2V-BERT-2.0 | CN-CELEB | 2796 | Присоединиться к планете знаний, чтобы получить | |||
| wav2vec2-large-xlsr-53 | CN-CELEB | 2796 | Присоединиться к планете знаний, чтобы получить | |||
| Wavlm-Large | CN-CELEB | 2796 | Присоединиться к планете знаний, чтобы получить |
иллюстрировать:
CAM++ , а функция потерь- AAMLoss .extract_features.py для заранее извлечения функций, что означает, что улучшение данных до аудио не используется во время обучения.w2v-bert-2.0 , wav2vec2-large-xlsr-53 получают из предварительного обучения многоязычных данных. Предварительные данные wavlm-base-plus и wavlm-large находятся только на английском языке.| Функция потерь | Набор данных | Поезда динамики | порог | Погасить | Mindcf | Модель скачать |
|---|---|---|---|---|---|---|
| Аамлосс | CN-CELEB | 2796 | 0,14574 | 0,10988 | 0,58955 | Присоединиться к планете знаний, чтобы получить |
| Sphereface2 | CN-CELEB | 2796 | 0,20377 | 0,11309 | 0,61536 | Присоединиться к планете знаний, чтобы получить |
| Tripletangularmarginloss | CN-CELEB | 2796 | 0,28940 | 0,11749 | 0,63735 | Присоединиться к планете знаний, чтобы получить |
| Субцентерлосс | CN-CELEB | 2796 | 0,13126 | 0,11775 | 0,56995 | Присоединиться к планете знаний, чтобы получить |
| Armlloss | CN-CELEB | 2796 | 0,14563 | 0,11805 | 0,57171 | Присоединиться к планете знаний, чтобы получить |
| Амлосс | CN-CELEB | 2796 | 0,12870 | 0,12301 | 0,63263 | Присоединиться к планете знаний, чтобы получить |
| Селосс | CN-CELEB | 2796 | 0,13607 | 0,12684 | 0,65176 | Присоединиться к планете знаний, чтобы получить |
иллюстрировать:
CAM++ , а метод предварительной обработки- Fbank .extract_features.py для заранее извлечения функций, что означает, что улучшение данных до аудио не используется во время обучения. conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaИспользуйте PIP для установки, команда заключается в следующем:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleРекомендуется установить исходный код , который может обеспечить использование последнего кода.
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . Автор использует CN-CELEB в этом уроке. Этот набор данных имеет в общей сложности около 3000 голосовых данных и голосовых данных 65 Вт+. После загрузки вам необходимо распаковать набор данных в каталог dataset . Кроме того, если вы хотите оценить, вам также необходимо загрузить тестовый набор CN-CELEB. Если у читателя есть другие лучшие наборы данных, его можно смешать вместе, но лучше всего использовать модуль инструмента Python для обработки звука, шумоподавления и отключения.
Первый - создать список данных. Форматом списка данных является <语音文件路径t语音分类标签> . Создание этого списка в основном для удобства последующего чтения и удобства чтения с использованием других наборов голосовых данных. Теги классификации голоса относятся к уникальному идентификатору динамика. Различные наборы голосовых данных могут быть записаны в одном и том же списке данных, написав соответствующие функции для генерации списков данных.
Выполните программу create_data.py для завершения подготовки данных.
python create_data.pyПосле выполнения вышеуказанной программы будет сгенерирован следующий формат данных. Если вы хотите настроить данные, обратитесь к следующему списку данных. Фронт является относительным путем аудио, а задница - это этикетка динамика, соответствующего звуку, который такой же, как и классификация. Обратите внимание, что идентификатор списка данных тестовых данных не должен быть таким же, как и идентификатор обучения, что означает, что говорящий на тестовых данных, возможно, не нужно появляться в учебном наборе, если одно и то же лицо в списке тестовых данных будет гарантировать, что один и тот же человек имеет тот же идентификатор.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
Метод предварительной обработки FBANK по умолчанию используется в файле конфигурации. Если вы хотите использовать другие методы предварительной обработки, вы можете изменить метод установки в файле конфигурации. Конкретное значение может быть изменено в соответствии с вашей собственной ситуацией. Если вы не уверены, как установить параметры, вы можете напрямую удалить эту часть и напрямую использовать значение по умолчанию.
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80Во время учебного процесса первое, что нужно прочитать аудиоданные, затем извлечь функции и, наконец, пройти обучение. Среди них чтение аудиоданных и извлечение функций также требует много времени, поэтому мы можем заранее извлечь функции. Если мы тренируем модель, мы сможем напрямую загружать и извлечь функции, чтобы скорость обучения была быстрее. Эта извлеченная функция является необязательной. Если нет хороших функций, обучающая модель начнется с чтения аудиоданных, а затем извлечения функций. Шаги по извлечению функций следующие:
extract_features.py для извлечения функций. Функции будут сохранены в каталоге dataset/features и генерируют новый список данных train_list_features.txt , enroll_list_features.txt и trials_list_features.txt . python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list , dataset_conf.enroll_list и dataset_conf.trials_list в train_list_features.txt , enroll_list_features.txt и trials_list_features.txt . Используя train.py для обучения модели, этот проект поддерживает несколько методов предварительной обработки звука. Параметры preprocess_conf.feature_method из файла конфигурации configs/ecapa_tdnn.yml . MelSpectrogram - это спектр MEL, Spectrogram - это спектр график, коэффициент спектра MFCC MEL CEPPECTRAL и т. Д. Метод улучшения данных может быть указан с помощью параметра augment_conf_path . Во время учебного процесса VisualDL будет использоваться для сохранения журнала обучения. Запустив VisualDL, вы можете просмотреть результаты обучения в любое время. Команда Startup visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyЖурнал вывода обучения:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
Start VisualDl: visualdl --logdir=log --host 0.0.0.0 , страница VisualDl выглядит следующим образом:
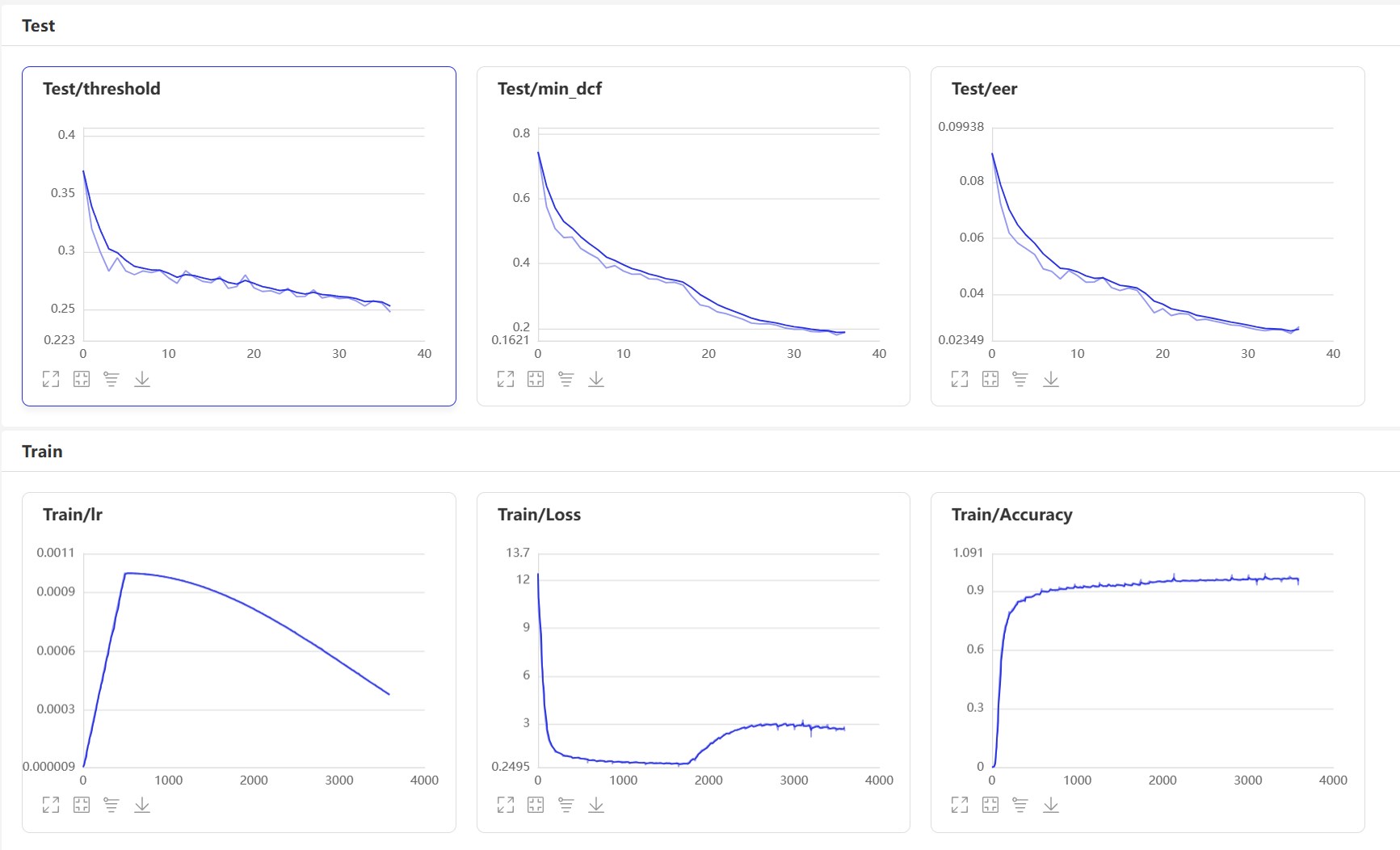
После обучения модель прогнозирования будет сохранена. Мы используем модель прогнозирования для прогнозирования аудио -функций в тестовом наборе, а затем используем аудио функции, чтобы сравнить их в парах для расчета EER и MindCF.
python eval.pyВывод аналогичен следующему:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
Вот несколько часто используемых интерфейсов. Для получения дополнительной информации, пожалуйста, обратитесь к mvector/predict.py . Вы также можете посмотреть на примеры声纹对比声纹识别.
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) Давайте начнем реализовать сравнение голосовых отпечатков и создать программу infer_contrast.py . Во -первых, мы вводим несколько важных функций. Функция predict() может получить функции голосовой отпечатки, функция predict_batch() может получить партию функций голосовой отпечатки, функция contrast() может сравнивать сходство между двумя звуками, функция register() регистрирует аудио в библиотеку голосового отпечатка, вводит аудио функцию recognition() и распознает его в библиотеке VoicePrint, remove_user() . Зарегистрируйтесь в библиотеке Voiceprint. Мы вводим две речи и получаем данные их функции через функцию прогнозирования. Используя эти данные, мы можем найти их диагональное значение косинуса, и результат можно использовать в качестве знакомства. Для этого threshold распознавания читатели могут изменить его в соответствии с требованиями точности своих проектов.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavВывод аналогичен следующему:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
В то же время также предоставляется программа сравнения голосовых отпечатков с интерфейсом GUI. Выполните infer_contrast_gui.py , чтобы начать программу. Интерфейс выглядит следующим образом. Выберите два звука соответственно. Нажмите, чтобы начать судить, чтобы определить, являются ли они одним и тем же человеком.
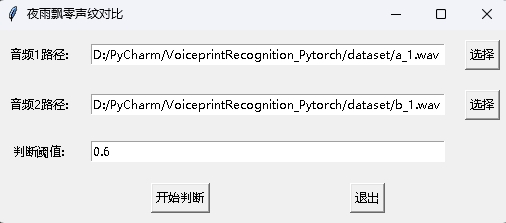
В признании новостей функция register() и функция recognition() в основном используются. Во -первых, используйте функцию register() , чтобы зарегистрировать аудио в библиотеку голосового отпечатка. Вы также можете напрямую добавить файл в папку audio_db . При его использовании вы можете инициировать распознавание с помощью функции recognition() . Введите звук, и вы можете определить необходимый динамик из библиотеки голосового отпечатка.
С помощью функции распознавания голосовой отпечатки читатели могут завершить распознавание голосовой отпечатки в соответствии с их собственными потребностями проекта. Например, то, что я предоставляю ниже, так это завершить распознавание голосовой отпечатки посредством записи. Во -первых, голос в библиотеке голоса должен быть загружен. Папка голосовой библиотеки - audio_db , а затем пользователь будет записывать звук в течение 3 секунд после нажатия автомобиля. Затем программа автоматически записывает звук и использует записанный звук для распознавания голосовой отпечатки, чтобы соответствовать голосу в библиотеке голоса и получить информацию пользователя. Таким образом, читатели также могут изменить его для завершения распознавания голосовой отпечатки через запросы на обслуживание, например, предоставить API для приложения для вызова. Когда пользователь входит в систему через Voiceprint в приложении, он отправляет записанный голос в бэкэнд, чтобы завершить распознавание голосовой отпечатки, а затем возвращает результат в приложение, при условии, что пользователь зарегистрировался с Voiceprint и успешно хранит голосовые данные в папке audio_db .
python infer_recognition.pyВывод аналогичен следующему:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
В то же время также предоставлена программа распознавания голосовых отверстий с интерфейсом графического интерфейса. Выполните infer_recognition_gui.py , чтобы запустить, нажмите кнопку注册音频到声纹库, понять и начать говорить, записать в течение 3 секунд, а затем введите имя регистратора. После этого вы можете执行声纹识别, а затем немедленно говорить. После записи в течение 3 секунд дождитесь результата распознавания. Кнопка删除用户может удалить пользователя. Кнопка实时识别может быть распознана в режиме реального времени и может быть записана и распознана в режиме реального времени.
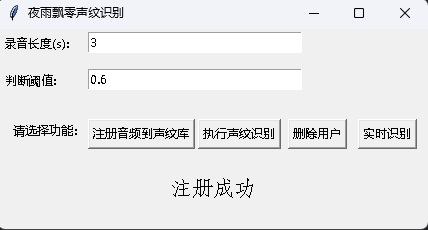
Выполните программу infer_speaker_diarization.py , введите путь аудио, и вы можете разделить динамик и отобразить результаты. Рекомендуется, чтобы длина звука не была менее 10 секунд. Для получения дополнительных функций вы можете просмотреть параметры программы.
python infer_speaker_diarization.py --audio_path=dataset/test_long.wavВывод аналогичен следующему:
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
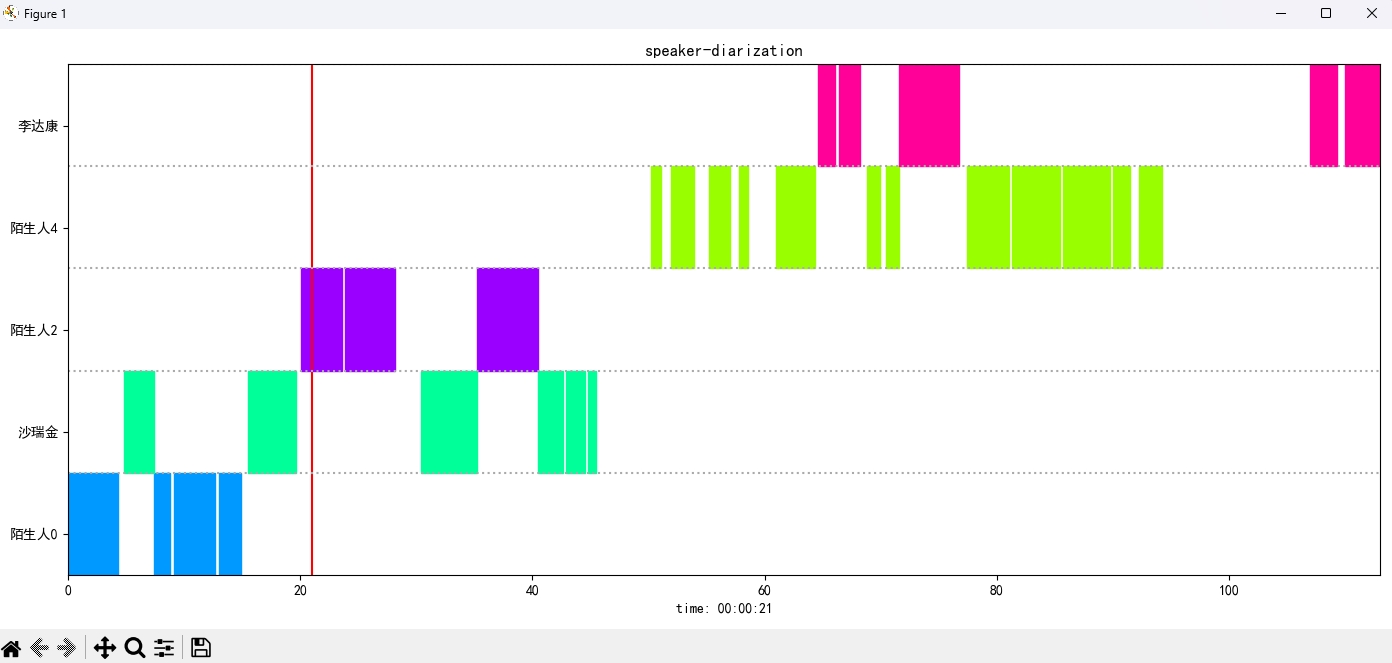
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
Изображение результата отображается следующим образом. Вы можете контролировать воспроизведение аудио через空格планку. Нажмите по позиции, чтобы перейти к указанной позиции:
Проект также предоставляет программу с интерфейсом GUI, выполняя программу infer_speaker_diarization_gui.py . Для получения дополнительных функций вы можете просмотреть параметры программы.
python infer_speaker_diarization_gui.pyВы можете открыть такую страницу, чтобы идентифицировать динамик:
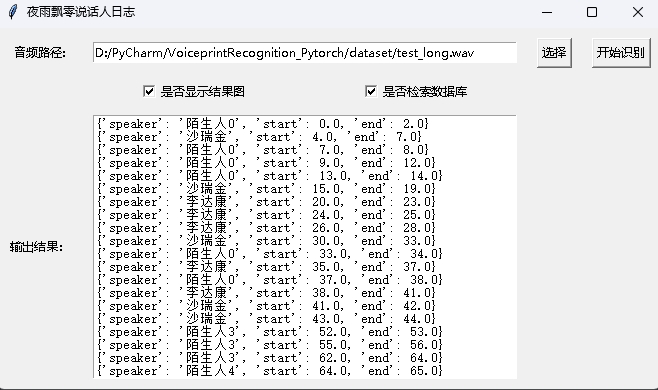
ПРИМЕЧАНИЕ. Если имя динамика на китайском языке, вам необходимо установить шрифт установки, чтобы отобразить его обычно. Вообще говоря, Windows не нужно устанавливать, но Ubuntu нужно установить. Если Windows действительно не хватает шрифтов, вам нужно только загрузить здесь файл .ttf Format и скопировать его на C:WindowsFonts . Работа системы Ubuntu заключается в следующем.
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )Вознаградите один доллар, чтобы поддержать автора


