VoiceprintRecognition Pytorch
1.0.0
تبسيط الصينية | إنجليزي
هذا الفرع هو الإصدار 1.1. إذا كنت ترغب في استخدام الإصدار 1.0 السابق ، فيرجى استخدامه في الفرع 1.0. يستخدم هذا المشروع العديد من نماذج التعرف على الصوتية المتقدمة مثل ECAPATDNN و RESNETSE و ERES2NET و CAM ++. لا يستبعد أن يتم دعم المزيد من النماذج في المستقبل. في الوقت نفسه ، يدعم هذا المشروع أيضًا العديد من أساليب المعالجة المسبقة للبيانات مثل melspectrogram و Spectrogram و MFCC و Fbank. فقدان ARCFACE ، فقدان ARCFACE: فقدان الهامش الزاوي المضافة (وظيفة فقدان الزاوية الإضافية) ، المقابلة لـ AAMLOSS في المشروع ، تقوم بتطبيع أجهزة الإلكترونية والأوزان ، وتضيف الفاصل الزمني M إلى M. فاصل الزاوية له تأثير مباشر أكثر على الزاوية من فاصل جيب التمام. بالإضافة إلى ذلك ، فإنه يدعم أيضًا وظائف الخسارة المختلفة مثل Amloss و Armloss و Celoss.
إذا كان هذا المشروع مفيدًا لك ، فلا ترحب بتجنب عدم العثور عليه لاحقًا.
الجميع مرحب بهم لمسح الكود لإدخال كوكب المعرفة أو مجموعة QQ لمناقشة. يوفر Knowledge Planet ملفات طراز المشروع والمدونين المدونين الأخرى ملفات طرازات المشاريع ذات الصلة ، وكذلك الموارد الأخرى.
بيئة الاستخدام:
ورقة نموذج:
| نموذج | params (M) | مجموعة البيانات | متحدثين تدريب | عتبة | eer | Mindcf | تنزيل النموذج |
|---|---|---|---|---|---|---|---|
| ERES2NETV2 | 6.6 | CN-CELEB | 2796 | 0.20089 | 0.08071 | 0.45705 | انضم إلى كوكب المعرفة للحصول على |
| eres2net | 6.6 | CN-CELEB | 2796 | 0.20014 | 0.08132 | 0.45544 | انضم إلى كوكب المعرفة للحصول على |
| كام ++ | 6.8 | CN-CELEB | 2796 | 0.23323 | 0.08332 | 0.48536 | انضم إلى كوكب المعرفة للحصول على |
| Resnetse | 7.8 | CN-CELEB | 2796 | 0.19066 | 0.08544 | 0.49142 | انضم إلى كوكب المعرفة للحصول على |
| ecapatdnn | 6.1 | CN-CELEB | 2796 | 0.23646 | 0.09259 | 0.51378 | انضم إلى كوكب المعرفة للحصول على |
| tdnn | 2.6 | CN-CELEB | 2796 | 0.23858 | 0.10825 | 0.59545 | انضم إلى كوكب المعرفة للحصول على |
| res2net | 5.0 | CN-CELEB | 2796 | 0.19526 | 0.12436 | 0.65347 | انضم إلى كوكب المعرفة للحصول على |
| كام ++ | 6.8 | مجموعة بيانات أكبر | 2W+ | 0.33 | 0.07874 | 0.52524 | انضم إلى كوكب المعرفة للحصول على |
| eres2net | 55.1 | مجموعات بيانات أخرى | 20W+ | 0.36 | 0.02936 | 0.18355 | انضم إلى كوكب المعرفة للحصول على |
| ERES2NETV2 | 56.2 | مجموعات بيانات أخرى | 20W+ | 0.36 | 0.03847 | 0.24301 | انضم إلى كوكب المعرفة للحصول على |
| كام ++ | 6.8 | مجموعات بيانات أخرى | 20W+ | 0.29 | 0.04765 | 0.31436 | انضم إلى كوكب المعرفة للحصول على |
يوضح:
speed_perturb_3_class: True .Fbank ووظيفة الخسارة هي AAMLoss .| نموذج | params (M) | مجموعة البيانات | متحدثين تدريب | عتبة | eer | Mindcf | تنزيل النموذج |
|---|---|---|---|---|---|---|---|
| كام ++ | 6.8 | voxceleb1 و 2 | 7205 | 0.22504 | 0.02436 | 0.15543 | انضم إلى كوكب المعرفة للحصول على |
| ecapatdnn | 6.1 | voxceleb1 و 2 | 7205 | 0.24877 | 0.02480 | 0.16188 | انضم إلى كوكب المعرفة للحصول على |
| ERES2NETV2 | 6.6 | voxceleb1 و 2 | 7205 | 0.20710 | 0.02742 | 0.17709 | انضم إلى كوكب المعرفة للحصول على |
| eres2net | 6.6 | voxceleb1 و 2 | 7205 | 0.20233 | 0.02954 | 0.17377 | انضم إلى كوكب المعرفة للحصول على |
| Resnetse | 7.8 | voxceleb1 و 2 | 7205 | 0.22567 | 0.03189 | 0.23040 | انضم إلى كوكب المعرفة للحصول على |
| tdnn | 2.6 | voxceleb1 و 2 | 7205 | 0.23834 | 0.03486 | 0.26792 | انضم إلى كوكب المعرفة للحصول على |
| res2net | 5.0 | voxceleb1 و 2 | 7205 | 0.19472 | 0.04370 | 0.40072 | انضم إلى كوكب المعرفة للحصول على |
| كام ++ | 6.8 | مجموعة بيانات أكبر | 2W+ | 0.28 | 0.03182 | 0.23731 | انضم إلى كوكب المعرفة للحصول على |
| eres2net | 55.1 | مجموعات بيانات أخرى | 20W+ | 0.53 | 0.08904 | 0.62130 | انضم إلى كوكب المعرفة للحصول على |
| ERES2NETV2 | 56.2 | مجموعات بيانات أخرى | 20W+ | 0.52 | 0.08649 | 0.64193 | انضم إلى كوكب المعرفة للحصول على |
| كام ++ | 6.8 | مجموعات بيانات أخرى | 20W+ | 0.49 | 0.10334 | 0.71200 | انضم إلى كوكب المعرفة للحصول على |
يوضح:
speed_perturb_3_class: True .Fbank ووظيفة الخسارة هي AAMLoss .| طريقة المعالجة المسبقة | مجموعة البيانات | متحدثين تدريب | عتبة | eer | Mindcf | تنزيل النموذج |
|---|---|---|---|---|---|---|
| fbank | CN-CELEB | 2796 | 0.14574 | 0.10988 | 0.58955 | انضم إلى كوكب المعرفة للحصول على |
| MFCC | CN-CELEB | 2796 | 0.14868 | 0.11483 | 0.61275 | انضم إلى كوكب المعرفة للحصول على |
| الطيفية | CN-CELEB | 2796 | 0.14962 | 0.11613 | 0.60057 | انضم إلى كوكب المعرفة للحصول على |
| melspectrogram | CN-CELEB | 2796 | 0.13458 | 0.12498 | 0.60741 | انضم إلى كوكب المعرفة للحصول على |
| wavlm-base-plus | CN-CELEB | 2796 | 0.14166 | 0.13247 | 0.62451 | انضم إلى كوكب المعرفة للحصول على |
| W2V-Bert-2.0 | CN-CELEB | 2796 | انضم إلى كوكب المعرفة للحصول على | |||
| WAV2VEC2-LARGE-XLSR-53 | CN-CELEB | 2796 | انضم إلى كوكب المعرفة للحصول على | |||
| wavlm-large | CN-CELEB | 2796 | انضم إلى كوكب المعرفة للحصول على |
يوضح:
CAM++ ، ووظيفة الخسارة هي AAMLoss .extract_features.py لاستخراج الميزات مقدمًا ، مما يعني أنه لا يتم استخدام تحسين البيانات إلى الصوت أثناء التدريب.w2v-bert-2.0 ، wav2vec2-large-xlsr-53 من التدريب المسبق للبيانات متعددة اللغات. بيانات ما قبل التدريب من wavlm-base-plus و wavlm-large هي فقط باللغة الإنجليزية.| وظيفة الخسارة | مجموعة البيانات | متحدثين تدريب | عتبة | eer | Mindcf | تنزيل النموذج |
|---|---|---|---|---|---|---|
| Aamloss | CN-CELEB | 2796 | 0.14574 | 0.10988 | 0.58955 | انضم إلى كوكب المعرفة للحصول على |
| Sphereface2 | CN-CELEB | 2796 | 0.20377 | 0.11309 | 0.61536 | انضم إلى كوكب المعرفة للحصول على |
| Tripletangularmarginloss | CN-CELEB | 2796 | 0.28940 | 0.11749 | 0.63735 | انضم إلى كوكب المعرفة للحصول على |
| Subcenterloss | CN-CELEB | 2796 | 0.13126 | 0.11775 | 0.56995 | انضم إلى كوكب المعرفة للحصول على |
| Armlloss | CN-CELEB | 2796 | 0.14563 | 0.11805 | 0.57171 | انضم إلى كوكب المعرفة للحصول على |
| amloss | CN-CELEB | 2796 | 0.12870 | 0.12301 | 0.63263 | انضم إلى كوكب المعرفة للحصول على |
| Celoss | CN-CELEB | 2796 | 0.13607 | 0.12684 | 0.65176 | انضم إلى كوكب المعرفة للحصول على |
يوضح:
CAM++ ، وطريقة المعالجة المسبقة هي Fbank .extract_features.py لاستخراج الميزات مقدمًا ، مما يعني أنه لا يتم استخدام تحسين البيانات إلى الصوت أثناء التدريب. conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaاستخدم PIP للتثبيت ، الأمر كما يلي:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleيوصى بتثبيت الكود المصدري ، والذي يمكن أن يضمن استخدام أحدث التعليمات البرمجية.
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . يستخدم المؤلف CN-CELEB في هذا البرنامج التعليمي. تحتوي مجموعة البيانات هذه على ما مجموعه حوالي 3000 بيانات صوتية و 65 واط+ بيانات صوتية. بعد التنزيل ، تحتاج إلى فك ضغط مجموعة البيانات إلى دليل dataset . بالإضافة إلى ذلك ، إذا كنت ترغب في التقييم ، فأنت بحاجة أيضًا إلى تنزيل مجموعة اختبار CN-CELEB. إذا كان لدى القارئ مجموعات بيانات أفضل أخرى ، فيمكن خلطه معًا ، ولكن من الأفضل استخدام وحدة أدوات Python Aukit لمعالجة الصوت وتقليل الضوضاء والبكم.
الأول هو إنشاء قائمة بيانات. تنسيق قائمة البيانات هو <语音文件路径t语音分类标签> . إنشاء هذه القائمة هو أساسا لراحة القراءة اللاحقة وراحة القراءة باستخدام مجموعات البيانات الصوتية الأخرى. تشير علامات التصنيف الصوتي إلى معرف المتحدث الفريد. يمكن كتابة مجموعات بيانات الصوت المختلفة في قائمة البيانات نفسها عن طريق كتابة الوظائف المقابلة لإنشاء قوائم البيانات.
قم بتنفيذ برنامج create_data.py لإكمال إعداد البيانات.
python create_data.pyبعد تنفيذ البرنامج أعلاه ، سيتم إنشاء تنسيق البيانات التالي. إذا كنت ترغب في تخصيص البيانات ، راجع قائمة البيانات التالية. الجبهة هي المسار النسبي للصوت ، والظهر هو ملصق السماعة المقابلة للصوت ، وهو نفس التصنيف. لاحظ أن معرف قائمة بيانات الاختبار لا يلزم أن يكون هو نفسه معرف التدريب ، مما يعني أن متحدث بيانات الاختبار قد لا يحتاج إلى الظهور في مجموعة التدريب ، طالما أن الشخص نفسه في قائمة بيانات الاختبار يتم ضمان أن الشخص نفسه لديه نفس المعرف.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
يتم استخدام طريقة معالجة FBANK الافتراضية في ملف التكوين. إذا كنت ترغب في استخدام طرق المعالجة المسبقة الأخرى ، فيمكنك تعديل طريقة التثبيت في ملف التكوين. يمكن تعديل القيمة المحددة وفقًا لموقفك. إذا لم تكن متأكدًا من كيفية تعيين المعلمات ، فيمكنك حذف هذا الجزء مباشرة واستخدام القيمة الافتراضية مباشرة.
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80أثناء عملية التدريب ، أول شيء هو قراءة بيانات الصوت ، ثم استخراج الميزات ، وأخيراً تنفيذ التدريب. من بينها ، فإن قراءة بيانات الصوت وميزات الاستخراج تستغرق وقتًا طويلاً ، حتى نتمكن من اختيار استخراج الميزات مقدمًا. إذا قمنا بتدريب النموذج ، فيمكننا تحميل الميزات واستخراجها مباشرة ، بحيث تكون سرعة التدريب أسرع. هذه الميزة المستخرجة اختيارية. إذا لم يتم استخراج ميزات جيدة ، فسيبدأ نموذج التدريب من خلال قراءة بيانات الصوت ثم استخراج الميزات. خطوات استخراج الميزات هي كما يلي:
extract_features.py لاستخراج الميزات. سيتم حفظ الميزات في دليل dataset/features وإنشاء قائمة بيانات جديدة train_list_features.txt ، enroll_list_features.txt و trials_list_features.txt . python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list ، و dataset_conf.enroll_list ، و dataset_conf.trials_list to train_list_features.txt ، enroll_list_features.txt ، و trials_list_features.txt . باستخدام train.py لتدريب النموذج ، يدعم هذا المشروع طرق المعالجة المسبقة الصوتية المتعددة. يمكن تحديد المعلمات preprocess_conf.feature_method من ملف التكوين configs/ecapa_tdnn.yml . MelSpectrogram هو طيف MEL ، Spectrogram هو الرسم البياني الطيف ، ومعامل MFCC MELPERIM augment_conf_path ، إلخ. أثناء عملية التدريب ، سيتم استخدام VisualDL لحفظ سجل التدريب. من خلال بدء VisualDL ، يمكنك عرض نتائج التدريب في أي وقت. أمر بدء التشغيل visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyسجل إخراج التدريب:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
ابدأ VisualDL: visualdl --logdir=log --host 0.0.0.0 ، صفحة VisualDL كما يلي:
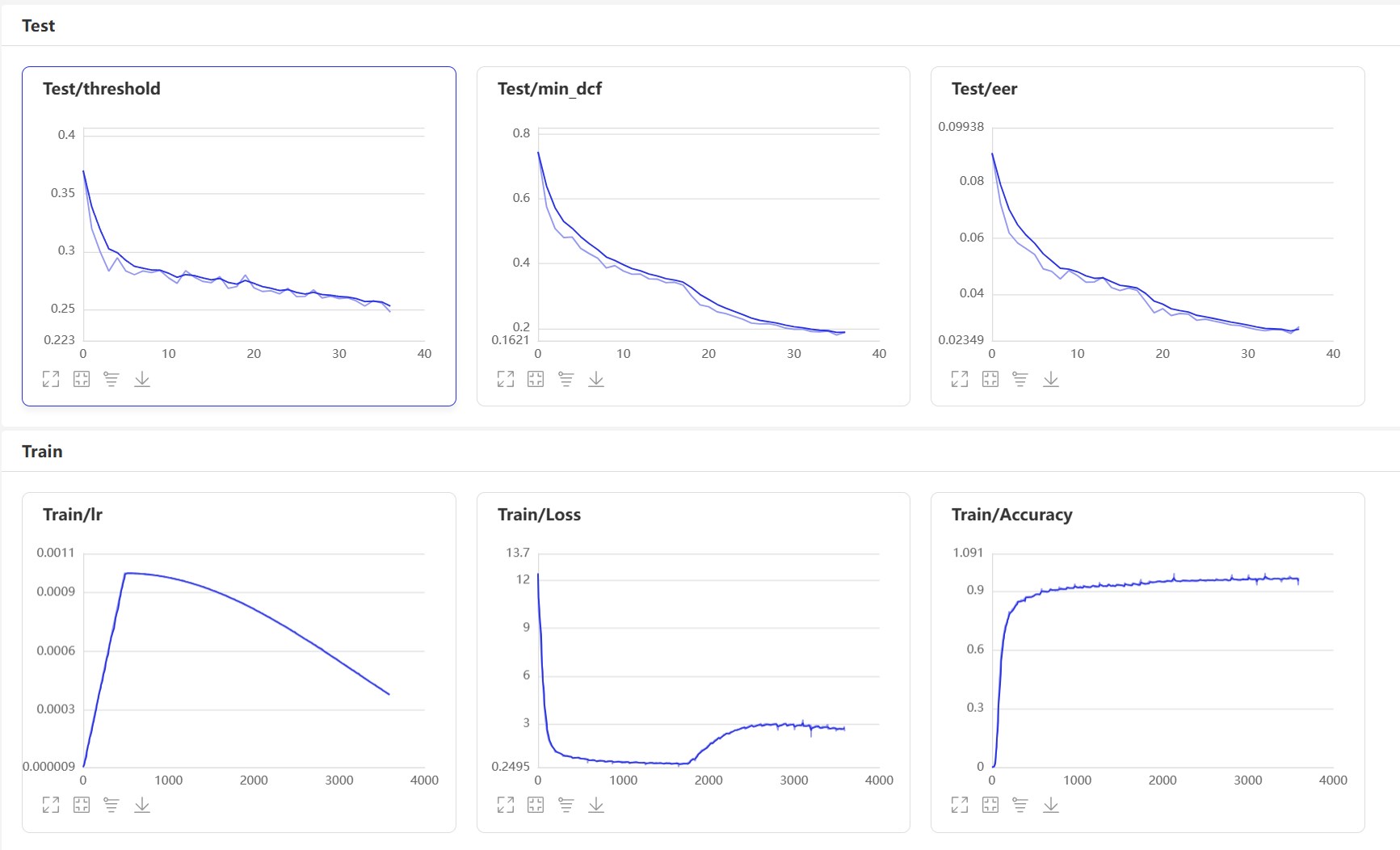
بعد التدريب ، سيتم حفظ نموذج التنبؤ. نستخدم نموذج التنبؤ للتنبؤ بميزات الصوت في مجموعة الاختبار ، ثم نستخدم ميزات الصوت لمقارنتها في أزواج لحساب EER و MINDCF.
python eval.pyالإخراج مشابه لما يلي:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
فيما يلي عدة واجهات شائعة الاستخدام. لمزيد من الواجهات ، يرجى الرجوع إلى mvector/predict.py . يمكنك أيضًا إلقاء نظرة على أمثلة声纹对比声纹识别.
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) دعنا نبدأ في تنفيذ مقارنة VoicePrint وإنشاء برنامج infer_contrast.py . أولاً ، نقدم العديد من الوظائف المهمة. يمكن أن تحصل وظيفة predict() على ميزات VoicePrint ، يمكن أن تحصل وظيفة predict_batch() على مجموعة من ميزات VoicePrint ، يمكن أن تقارن وظيفة contrast() التشابه بين اثنين من الصوت ، وتسجيل دالة recognition() register() صوتيًا في مكتبة الصوت ، remove_user() . سجل في مكتبة VoicePrint. ندخل خطابين ونحصل على بيانات الميزة الخاصة بهم من خلال وظيفة التنبؤ. باستخدام بيانات الميزة هذه ، يمكننا العثور على قيمة جيب التمام المائل ، ويمكن استخدام النتيجة كتعرف عليها. لهذا threshold من الاعتراف ، يمكن للقراء تعديله وفقًا لمتطلبات دقة مشاريعهم.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavالإخراج مشابه لما يلي:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
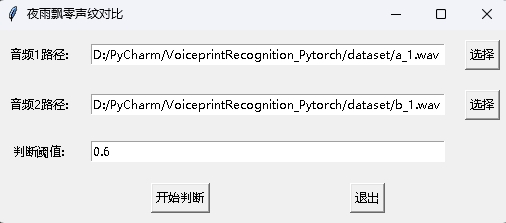
في الوقت نفسه ، يتم أيضًا توفير برنامج مقارنة لـ VoicePrint مع واجهة واجهة المستخدم الرسومية. قم بتنفيذ infer_contrast_gui.py لبدء البرنامج. الواجهة كما يلي. حدد اثنين من الصوت على التوالي. انقر للبدء في الحكم لتحديد ما إذا كان نفس الشخص.
في التعرف على الأخبار ، يتم استخدام وظيفة register() ووظيفة recognition() بشكل أساسي. أولاً ، استخدم وظيفة register() لتسجيل الصوت في مكتبة VoicePrint. يمكنك أيضًا إضافة الملف مباشرة إلى مجلد audio_db . عند استخدامه ، يمكنك بدء التعرف من خلال وظيفة recognition() . أدخل صوتًا ويمكنك تحديد مكبر الصوت المطلوب من مكتبة VoicePrint.
مع وظيفة التعرف على VoicePrint أعلاه ، يمكن للقراء إكمال التعرف على صوتي وفقًا لاحتياجات المشروع الخاصة بهم. على سبيل المثال ، ما أقدمه أدناه هو إكمال التعرف على صوتي من خلال التسجيل. أولاً ، يجب تحميل الصوت في المكتبة الصوتية. مجلد المكتبة الصوتية هو audio_db ، وبعد ذلك سيقوم المستخدم بتسجيل الصوت لمدة 3 ثوان بعد الضغط على السيارة. بعد ذلك ، سيقوم البرنامج تلقائيًا بتسجيل الصوت واستخدام الصوت المسجل للتعرف على VoicePrint لمطابقة الصوت في المكتبة الصوتية والحصول على معلومات المستخدم. وبهذه الطريقة ، يمكن للقراء أيضًا تعديله لإكمال التعرف على VoicePrint من خلال طلبات الخدمة ، على سبيل المثال ، توفير واجهة برمجة تطبيقات للاتصال. عندما يقوم المستخدم بتسجيل الدخول من خلال VoicePrint على التطبيق ، يرسل الصوت المسجل إلى الواجهة الخلفية لإكمال التعرف على VoicePrint ، ثم يقوم بإرجاع النتيجة إلى التطبيق ، شريطة أن يكون المستخدم قد سجل مع VoicePrint ويخزن البيانات الصوتية بنجاح في مجلد audio_db .
python infer_recognition.pyالإخراج مشابه لما يلي:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
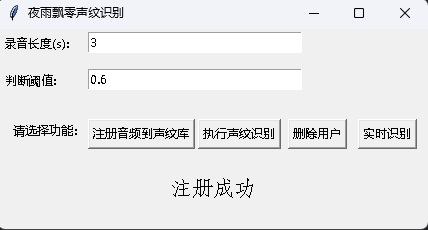
في الوقت نفسه ، يتم أيضًا توفير برنامج التعرف على VoicePrint مع واجهة واجهة المستخدم الرسومية. قم بتنفيذ infer_recognition_gui.py للبدء ، انقر فوق الزر注册音频到声纹库، وفهم وبدء التحدث ، وتسجيله لمدة 3 ثوان ، ثم أدخل اسم المسجل. بعد ذلك ، يمكنك执行声纹识别، ثم التحدث على الفور. بعد التسجيل لمدة 3 ثوان ، انتظر نتيجة الاعتراف. يمكن لزر删除用户حذف المستخدم. يمكن التعرف على زر实时识别في الوقت الفعلي ، ويمكن تسجيله والتعرف عليه في الوقت الفعلي.
قم بتنفيذ برنامج infer_speaker_diarization.py ، وأدخل مسار الصوت ، ويمكنك فصل السماعة وعرض النتائج. يوصى بأن لا يقل طول الصوت عن 10 ثوانٍ. لمزيد من الوظائف ، يمكنك عرض معلمات البرنامج.
python infer_speaker_diarization.py --audio_path=dataset/test_long.wavالإخراج مشابه لما يلي:
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
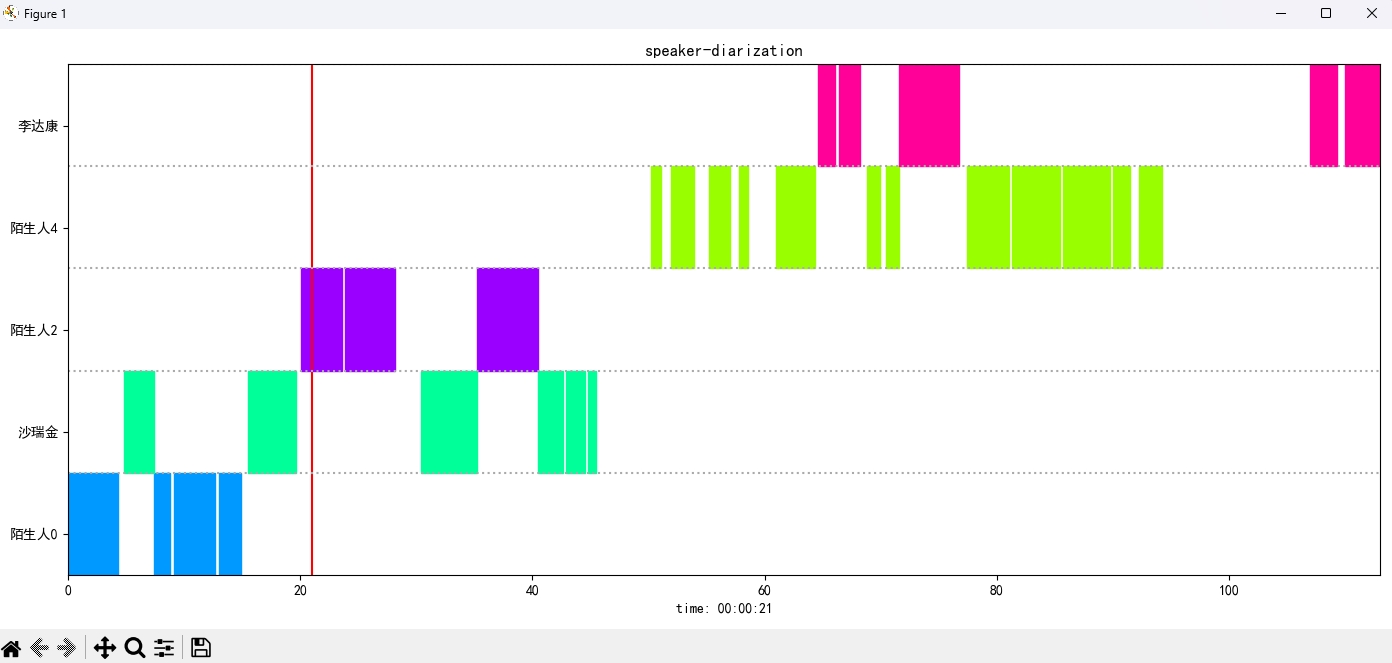
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
يتم عرض صورة النتيجة على النحو التالي. يمكنك التحكم في تشغيل الصوت من خلال شريط空格. انقر على الموضع للقفز إلى الموضع المحدد:
يوفر المشروع أيضًا برنامجًا لواجهة واجهة المستخدم الرسومية ، حيث يقوم بتنفيذ برنامج infer_speaker_diarization_gui.py . لمزيد من الوظائف ، يمكنك عرض معلمات البرنامج.
python infer_speaker_diarization_gui.pyيمكنك فتح مثل هذه الصفحة لتحديد المتحدث:
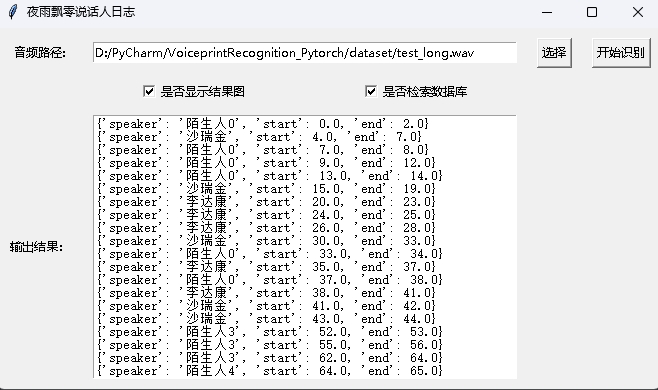
ملاحظة: إذا كان اسم السماعة باللغة الصينية ، فأنت بحاجة إلى تعيين خط التثبيت لعرضه بشكل طبيعي. بشكل عام ، لا تحتاج Windows إلى تثبيت ، ولكن يجب تثبيت Ubuntu. إذا كان Windows مفقودًا بالفعل ، فأنت بحاجة فقط إلى تنزيل ملف تنسيق .ttf هنا ونسخه إلى C:WindowsFonts . عملية نظام Ubuntu كما يلي.
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )مكافأة دولار واحد لدعم المؤلف


