VoiceprintRecognition Pytorch
1.0.0
Chino simplificado | Inglés
Esta rama es la versión 1.1. Si desea usar la versión 1.0 anterior, úsela en la sucursal 1.0. Este proyecto utiliza varios modelos avanzados de reconocimiento de huellas de voz como Ecapatdnn, ResNetse, ERES2Net y CAM ++. No se descarta que más modelos serán compatibles en el futuro. Al mismo tiempo, este proyecto también admite varios métodos de preprocesamiento de datos, como melspectrogram, espectrograma, MFCC y FBank. Pérdida de la cara de arco, pérdida de cara de arco: pérdida de margen angular aditivo (función de pérdida de intervalo de ángulo aditivo), correspondiente al AAMLOSS en el proyecto, normaliza los vectores propios y los pesos, y agrega el intervalo de ángulo M a θ. El intervalo de ángulo tiene un impacto más directo en el ángulo que el intervalo de coseno. Además, también admite varias funciones de pérdida como Amloss, Armloss y Celos.
Si este proyecto es útil para usted, bienvenido a Star para evitar que no se encuentre más tarde.
Todos son bienvenidos a escanear el código para ingresar al planeta de conocimiento o al grupo QQ para discutir. Knowledge Planet proporciona archivos de modelos de proyectos y los otros archivos de modelos de proyectos relacionados de los bloggers, así como otros recursos.
Entorno de uso:
Documento modelo:
| Modelo | Parámetros (m) | Conjunto de datos | altavoces de tren | límite | Misterioso | Mindcf | Descargar modelo |
|---|---|---|---|---|---|---|---|
| ERES2NETV2 | 6.6 | CN-CELEB | 2796 | 0.20089 | 0.08071 | 0.45705 | Únase al planeta de conocimiento para obtener |
| ERES2NET | 6.6 | CN-CELEB | 2796 | 0.20014 | 0.08132 | 0.45544 | Únase al planeta de conocimiento para obtener |
| Cam ++ | 6.8 | CN-CELEB | 2796 | 0.23323 | 0.08332 | 0.48536 | Únase al planeta de conocimiento para obtener |
| Resnetse | 7.8 | CN-CELEB | 2796 | 0.19066 | 0.08544 | 0.49142 | Únase al planeta de conocimiento para obtener |
| Ecapatdnn | 6.1 | CN-CELEB | 2796 | 0.23646 | 0.09259 | 0.51378 | Únase al planeta de conocimiento para obtener |
| Tdnn | 2.6 | CN-CELEB | 2796 | 0.23858 | 0.10825 | 0.59545 | Únase al planeta de conocimiento para obtener |
| Res2net | 5.0 | CN-CELEB | 2796 | 0.19526 | 0.12436 | 0.65347 | Únase al planeta de conocimiento para obtener |
| Cam ++ | 6.8 | Conjunto de datos más grande | 2W+ | 0.33 | 0.07874 | 0.52524 | Únase al planeta de conocimiento para obtener |
| ERES2NET | 55.1 | Otros conjuntos de datos | 20W+ | 0.36 | 0.02936 | 0.18355 | Únase al planeta de conocimiento para obtener |
| ERES2NETV2 | 56.2 | Otros conjuntos de datos | 20W+ | 0.36 | 0.03847 | 0.24301 | Únase al planeta de conocimiento para obtener |
| Cam ++ | 6.8 | Otros conjuntos de datos | 20W+ | 0.29 | 0.04765 | 0.31436 | Únase al planeta de conocimiento para obtener |
ilustrar:
speed_perturb_3_class: True .Fbank y la función de pérdida es AAMLoss .| Modelo | Parámetros (m) | Conjunto de datos | altavoces de tren | límite | Misterioso | Mindcf | Descargar modelo |
|---|---|---|---|---|---|---|---|
| Cam ++ | 6.8 | VoxCeleb1 y 2 | 7205 | 0.22504 | 0.02436 | 0.15543 | Únase al planeta de conocimiento para obtener |
| Ecapatdnn | 6.1 | VoxCeleb1 y 2 | 7205 | 0.24877 | 0.02480 | 0.16188 | Únase al planeta de conocimiento para obtener |
| ERES2NETV2 | 6.6 | VoxCeleb1 y 2 | 7205 | 0.20710 | 0.02742 | 0.17709 | Únase al planeta de conocimiento para obtener |
| ERES2NET | 6.6 | VoxCeleb1 y 2 | 7205 | 0.20233 | 0.02954 | 0.17377 | Únase al planeta de conocimiento para obtener |
| Resnetse | 7.8 | VoxCeleb1 y 2 | 7205 | 0.22567 | 0.03189 | 0.23040 | Únase al planeta de conocimiento para obtener |
| Tdnn | 2.6 | VoxCeleb1 y 2 | 7205 | 0.23834 | 0.03486 | 0.26792 | Únase al planeta de conocimiento para obtener |
| Res2net | 5.0 | VoxCeleb1 y 2 | 7205 | 0.19472 | 0.04370 | 0.40072 | Únase al planeta de conocimiento para obtener |
| Cam ++ | 6.8 | Conjunto de datos más grande | 2W+ | 0.28 | 0.03182 | 0.23731 | Únase al planeta de conocimiento para obtener |
| ERES2NET | 55.1 | Otros conjuntos de datos | 20W+ | 0.53 | 0.08904 | 0.62130 | Únase al planeta de conocimiento para obtener |
| ERES2NETV2 | 56.2 | Otros conjuntos de datos | 20W+ | 0.52 | 0.08649 | 0.64193 | Únase al planeta de conocimiento para obtener |
| Cam ++ | 6.8 | Otros conjuntos de datos | 20W+ | 0.49 | 0.10334 | 0.71200 | Únase al planeta de conocimiento para obtener |
ilustrar:
speed_perturb_3_class: True .Fbank y la función de pérdida es AAMLoss .| Método de preprocesamiento | Conjunto de datos | altavoces de tren | límite | Misterioso | Mindcf | Descargar modelo |
|---|---|---|---|---|---|---|
| FBANK | CN-CELEB | 2796 | 0.14574 | 0.10988 | 0.58955 | Únase al planeta de conocimiento para obtener |
| MFCC | CN-CELEB | 2796 | 0.14868 | 0.11483 | 0.61275 | Únase al planeta de conocimiento para obtener |
| Espectrograma | CN-CELEB | 2796 | 0.14962 | 0.11613 | 0.60057 | Únase al planeta de conocimiento para obtener |
| Melspectrograma | CN-CELEB | 2796 | 0.13458 | 0.12498 | 0.60741 | Únase al planeta de conocimiento para obtener |
| wavlm-base-plus | CN-CELEB | 2796 | 0.14166 | 0.13247 | 0.62451 | Únase al planeta de conocimiento para obtener |
| W2V-Bert-2.0 | CN-CELEB | 2796 | Únase al planeta de conocimiento para obtener | |||
| WAV2VEC2-LARGE-XLSR-53 | CN-CELEB | 2796 | Únase al planeta de conocimiento para obtener | |||
| wavlm-large | CN-CELEB | 2796 | Únase al planeta de conocimiento para obtener |
ilustrar:
CAM++ y la función de pérdida es AAMLoss .extract_features.py para extraer funciones por adelantado, lo que significa que la mejora de los datos para el audio no se usa durante el entrenamiento.w2v-bert-2.0 , wav2vec2-large-xlsr-53 se obtienen de la capacitación previa de datos multilingües. Los datos previos al entrenamiento de wavlm-base-plus y wavlm-large son solo en inglés.| Función de pérdida | Conjunto de datos | altavoces de tren | límite | Misterioso | Mindcf | Descargar modelo |
|---|---|---|---|---|---|---|
| Aamloss | CN-CELEB | 2796 | 0.14574 | 0.10988 | 0.58955 | Únase al planeta de conocimiento para obtener |
| Sphereface2 | CN-CELEB | 2796 | 0.20377 | 0.11309 | 0.61536 | Únase al planeta de conocimiento para obtener |
| TripletangularMarginloss | CN-CELEB | 2796 | 0.28940 | 0.11749 | 0.63735 | Únase al planeta de conocimiento para obtener |
| Subcenterloss | CN-CELEB | 2796 | 0.13126 | 0.11775 | 0.56995 | Únase al planeta de conocimiento para obtener |
| Brazo | CN-CELEB | 2796 | 0.14563 | 0.11805 | 0.57171 | Únase al planeta de conocimiento para obtener |
| Amlosada | CN-CELEB | 2796 | 0.12870 | 0.12301 | 0.63263 | Únase al planeta de conocimiento para obtener |
| Celos | CN-CELEB | 2796 | 0.13607 | 0.12684 | 0.65176 | Únase al planeta de conocimiento para obtener |
ilustrar:
CAM++ y el método de preprocesamiento es Fbank .extract_features.py para extraer funciones por adelantado, lo que significa que la mejora de los datos para el audio no se usa durante el entrenamiento. conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaUse PIP para instalar, el comando es el siguiente:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleSe recomienda instalar el código fuente , que puede garantizar el uso del último código.
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . El autor usa CN-Celeb en este tutorial. Este conjunto de datos tiene un total de aproximadamente 3.000 datos de voz y datos de voz 65W+. Después de descargar, debe descomprimir el conjunto de datos en el directorio dataset . Además, si desea evaluar, también debe descargar el conjunto de pruebas CN-Celeb. Si el lector tiene otros mejores conjuntos de datos, se puede mezclar, pero es mejor usar el módulo de herramienta de Python Aukit para procesar audio, reducción de ruido y silencio.
El primero es crear una lista de datos. El formato de la lista de datos es <语音文件路径t语音分类标签> . La creación de esta lista es principalmente para la conveniencia de la lectura posterior y la conveniencia de la lectura utilizando otros conjuntos de datos de voz. Las etiquetas de clasificación de voz se refieren a la identificación única del altavoz. Se pueden escribir diferentes conjuntos de datos de voz en la misma lista de datos escribiendo las funciones correspondientes para generar listas de datos.
Ejecute el programa create_data.py para completar la preparación de datos.
python create_data.pyDespués de ejecutar el programa anterior, se generará el siguiente formato de datos. Si desea personalizar los datos, consulte la siguiente lista de datos. El frente es la ruta relativa del audio, y la parte posterior es la etiqueta del altavoz correspondiente al audio, que es la misma que la clasificación. Tenga en cuenta que la ID de la lista de datos de prueba no necesita ser la misma que la ID de capacitación, lo que significa que el orador de los datos de prueba puede no necesitar aparecer en el conjunto de capacitación, siempre que la misma persona en la lista de datos de prueba esté asegurado que la misma persona tenga la misma ID.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
El método predeterminado de preprocesamiento de FBank se utiliza en el archivo de configuración. Si desea utilizar otros métodos de preprocesamiento, puede modificar el método de instalación en el archivo de configuración. El valor específico se puede modificar de acuerdo con su propia situación. Si no está seguro de cómo establecer parámetros, puede eliminar esta parte directamente y usar el valor predeterminado directamente.
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80Durante el proceso de capacitación, lo primero es leer los datos de audio, luego extraer las características y finalmente realizar capacitación. Entre ellos, la lectura de datos de audio y las características de extracción también lleva mucho tiempo, por lo que podemos elegir extraer funciones con anticipación. Si entrenamos el modelo, podemos cargar y extraer directamente las características, para que la velocidad de entrenamiento sea más rápida. Esta característica extraída es opcional. Si no se extraen buenas características, el modelo de entrenamiento comenzará leyendo los datos de audio y luego extrayendo las características. Los pasos para extraer características son los siguientes:
extract_features.py para extraer características. Las características se guardarán en el directorio dataset/features y generarán una nueva lista de datos train_list_features.txt , enroll_list_features.txt y trials_list_features.txt . python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list , dataset_conf.enroll_list , y dataset_conf.trials_list a train_list_features.txt , enroll_list_features.txt y trials_list_features.txt . Usando train.py para entrenar el modelo, este proyecto admite múltiples métodos de preprocesamiento de audio. Se puede especificar los parámetros preprocess_conf.feature_method del archivo de configuración configs/ecapa_tdnn.yml . MelSpectrogram es el espectro MEL, Spectrogram es el gráfico de espectro, el coeficiente de espectro CEP Cepectral MFCC MEL, etc. El método de mejora de datos se puede especificar mediante el parámetro augment_conf_path . Durante el proceso de capacitación, VisualDL se utilizará para guardar el registro de capacitación. Al comenzar VisualDL, puede ver los resultados de la capacitación en cualquier momento. El comando de inicio visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyRegistro de salida de entrenamiento:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
Inicio VisualDL: visualdl --logdir=log --host 0.0.0.0 , la página VisualDL es la siguiente:
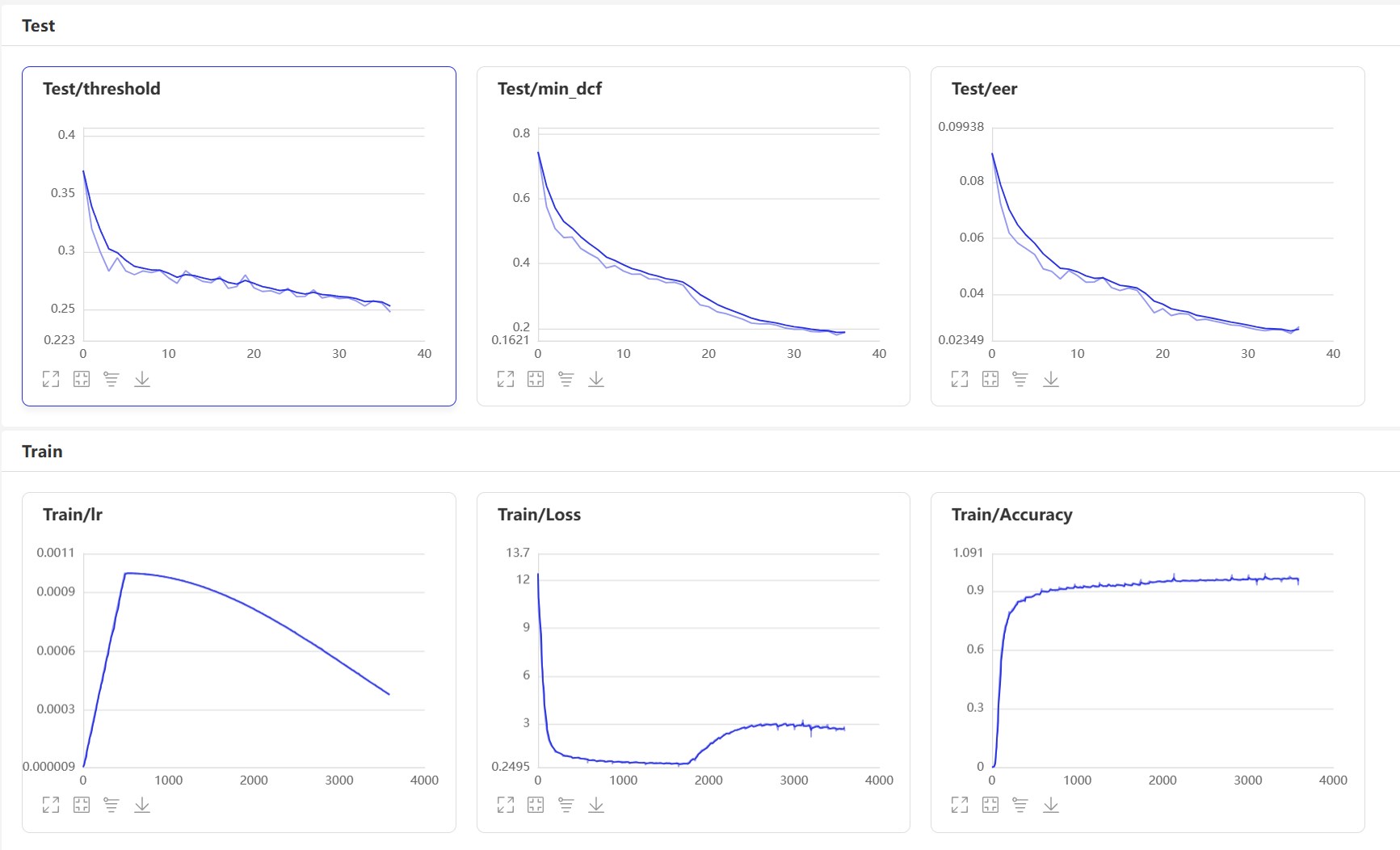
Después del entrenamiento, se guardará el modelo de predicción. Utilizamos el modelo de predicción para predecir las funciones de audio en el conjunto de pruebas, y luego usamos las funciones de audio para compararlas en pares para calcular EER y MINDCF.
python eval.pyLa salida es similar a la siguiente:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
Aquí hay varias interfaces de uso común. Para obtener más interfaces, consulte mvector/predict.py . También puede ver los ejemplos de声纹对比声纹识别.
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) Comencemos a implementar la comparación de VoicePrint y crear un programa infer_contrast.py . Primero, presentamos varias funciones importantes. predict() puede obtener características de VoicePrint, predict_batch() puede obtener un lote de características de VoicePrint, contrast() puede comparar la similitud entre dos audios audios, register() registra una biblioteca de Audio VoicePrint, entra en una función de Audio de recognition() y lo compara y lo reconoce de la biblioteca de voz de la biblioteca de voz, remove_user() function ()?) Regístrese en la biblioteca VoicePrint. Ingresamos dos discursos y obtenemos sus datos de características a través de la función de predicción. Usando estos datos de características, podemos encontrar su valor de coseno diagonal, y el resultado puede usarse como conocido. Para este threshold de reconocimiento, los lectores pueden modificarlo de acuerdo con los requisitos de precisión de sus proyectos.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavLa salida es similar a la siguiente:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
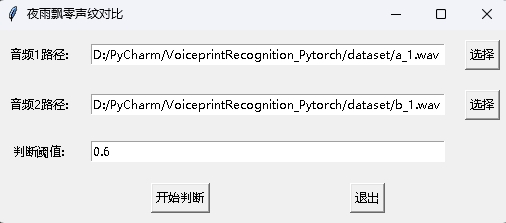
Al mismo tiempo, también se proporciona un programa de comparación de huellas de voz con una interfaz GUI. Ejecute infer_contrast_gui.py para iniciar el programa. La interfaz es la siguiente. Seleccione dos audios respectivamente. Haga clic para comenzar a juzgar para determinar si son la misma persona.
En el reconocimiento de noticias, la función register() y recognition() se utilizan principalmente. Primero, use register() para registrar el audio en la biblioteca VoicePrint. También puede agregar directamente el archivo a la carpeta audio_db . Al usarlo, puede iniciar el reconocimiento a través de la función recognition() . Ingrese un audio y puede identificar el altavoz requerido desde la biblioteca VoicePrint.
Con la función de reconocimiento de huella de voz anterior, los lectores pueden completar el reconocimiento de huellas de voz de acuerdo con sus propias necesidades de proyecto. Por ejemplo, lo que proporciono a continuación es completar el reconocimiento de Voiceprint a través de la grabación. Primero, la voz en la biblioteca de voz debe cargarse. La carpeta de la biblioteca de voz es audio_db , y luego el usuario grabará el sonido durante 3 segundos después de presionar el automóvil. Luego, el programa grabará automáticamente el sonido y usará el audio grabado para el reconocimiento de VoicePrint para que coincida con la voz en la biblioteca de voz y obtenga información del usuario. De esta manera, los lectores también pueden modificarlo para completar el reconocimiento de VoicePrint a través de solicitudes de servicio, por ejemplo, proporcionar una API para que la aplicación llame. Cuando el usuario inicia sesión a través de VoicePrint en la aplicación, envía la voz grabada al backend para completar el reconocimiento de VoicePrint, y luego devuelve el resultado a la aplicación, siempre que el usuario se haya registrado con VoicePrint y almacene con éxito los datos de voz en la carpeta audio_db .
python infer_recognition.pyLa salida es similar a la siguiente:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
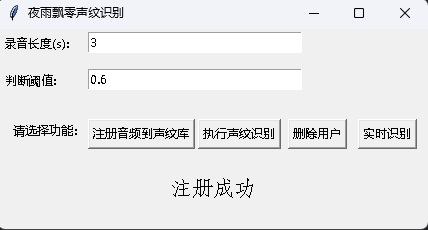
Al mismo tiempo, también se proporciona un programa de reconocimiento de huellas de voz con una interfaz GUI. Ejecute infer_recognition_gui.py para iniciar, haga clic en注册音频到声纹库, comprenda y comience a hablar, grabe durante 3 segundos y luego ingrese el nombre del registrante. Después de eso, puede执行声纹识别y luego hablar de inmediato. Después de grabar durante 3 segundos, espere el resultado de reconocimiento. El botón删除用户puede eliminar al usuario. El botón实时识别se puede reconocer en tiempo real y se puede registrar y reconocer en tiempo real.
Ejecute el programa infer_speaker_diarization.py , ingrese la ruta de audio y puede separar el altavoz y mostrar los resultados. Se recomienda que la longitud de audio no sea inferior a 10 segundos. Para más funciones, puede ver los parámetros del programa.
python infer_speaker_diarization.py --audio_path=dataset/test_long.wavLa salida es similar a la siguiente:
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
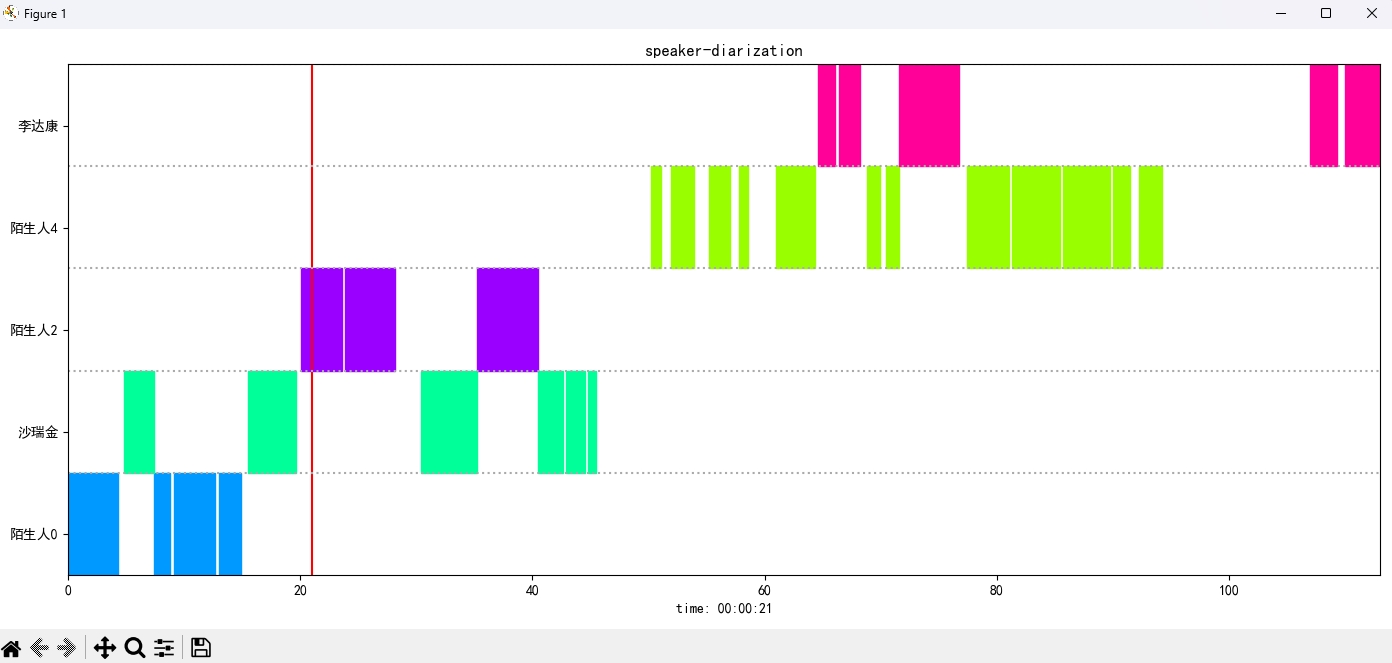
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
La imagen del resultado se muestra de la siguiente manera. Puedes controlar la reproducción de audio a través de空格. Haga clic en la posición para saltar a la posición especificada:
El proyecto también proporciona un programa con la interfaz GUI, ejecutando el programa infer_speaker_diarization_gui.py . Para más funciones, puede ver los parámetros del programa.
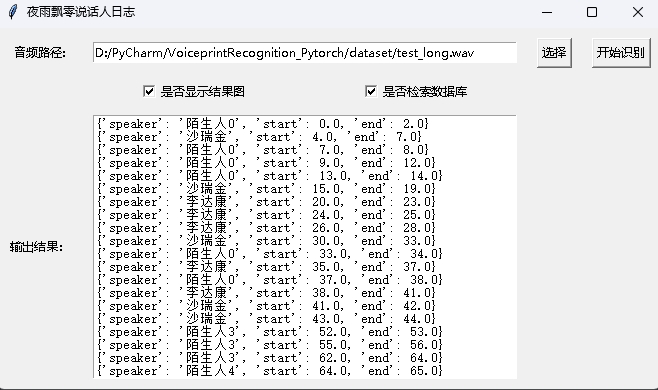
python infer_speaker_diarization_gui.pyPuede abrir una página de este tipo para identificar el altavoz:
Nota: Si el nombre del altavoz está en chino, debe configurar la fuente de instalación para mostrarla normalmente. En términos generales, Windows no es necesario instalar, pero Ubuntu debe instalarse. Si Windows está realmente faltando fuentes, solo necesita descargar el archivo de formato .ttf aquí y copiarlo a C:WindowsFonts . La operación del sistema Ubuntu es la siguiente.
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )Recompensa un dólar para apoyar al autor


