VoiceprintRecognition Pytorch
1.0.0
単純化された中国人|英語
このブランチはバージョン1.1です。以前のバージョン1.0を使用する場合は、1.0ブランチで使用してください。このプロジェクトでは、Ecapatdnn、Resnetse、ERES2NET、CAM ++などのさまざまな高度なVoicePrint認識モデルを使用しています。将来、より多くのモデルがサポートされることは除外されていません。同時に、このプロジェクトは、Melspectrogram、Spectrogram、MFCC、FBANKなどのさまざまなデータ前処理方法もサポートしています。 ARCFACEの損失、アークフェイス損失:プロジェクトのAamlossに対応するARCFACE角マージン損失(添加角角間隔損失関数)は、固有ベクトルと重みを正規化し、角度間隔mをθに追加します。角度間隔は、コサイン間隔よりも角度に直接影響を与えます。さらに、Amloss、Armloss、Celossなどのさまざまな損失関数もサポートしています。
このプロジェクトが役立つ場合は、後で発見されないことを避けるためにスターを歓迎してください。
誰もがコードをスキャンして知識惑星またはQQグループを入力して議論することを歓迎します。 Knowledge Planetは、プロジェクトモデルファイルとブロガーの他の関連プロジェクトモデルファイル、およびその他のリソースを提供します。
使用環境:
モデルペーパー:
| モデル | パラメーション(m) | データセット | トレーニングスピーカー | しきい値 | ええ | mindcf | モデルダウンロード |
|---|---|---|---|---|---|---|---|
| eres2netv2 | 6.6 | CN-Celeb | 2796 | 0.20089 | 0.08071 | 0.45705 | 知識惑星に参加して入手してください |
| eres2net | 6.6 | CN-Celeb | 2796 | 0.20014 | 0.08132 | 0.45544 | 知識惑星に参加して入手してください |
| CAM ++ | 6.8 | CN-Celeb | 2796 | 0.23323 | 0.08332 | 0.48536 | 知識惑星に参加して入手してください |
| Resnetse | 7.8 | CN-Celeb | 2796 | 0.19066 | 0.08544 | 0.49142 | 知識惑星に参加して入手してください |
| ecapatdnn | 6.1 | CN-Celeb | 2796 | 0.23646 | 0.09259 | 0.51378 | 知識惑星に参加して入手してください |
| tdnn | 2.6 | CN-Celeb | 2796 | 0.23858 | 0.10825 | 0.59545 | 知識惑星に参加して入手してください |
| RES2NET | 5.0 | CN-Celeb | 2796 | 0.19526 | 0.12436 | 0.65347 | 知識惑星に参加して入手してください |
| CAM ++ | 6.8 | より大きなデータセット | 2W+ | 0.33 | 0.07874 | 0.52524 | 知識惑星に参加して入手してください |
| eres2net | 55.1 | 他のデータセット | 20W+ | 0.36 | 0.02936 | 0.18355 | 知識惑星に参加して入手してください |
| eres2netv2 | 56.2 | 他のデータセット | 20W+ | 0.36 | 0.03847 | 0.24301 | 知識惑星に参加して入手してください |
| CAM ++ | 6.8 | 他のデータセット | 20W+ | 0.29 | 0.04765 | 0.31436 | 知識惑星に参加して入手してください |
説明:
speed_perturb_3_class: True 。Fbankで、損失関数はAAMLossです。| モデル | パラメーション(m) | データセット | トレーニングスピーカー | しきい値 | ええ | mindcf | モデルダウンロード |
|---|---|---|---|---|---|---|---|
| CAM ++ | 6.8 | voxceleb1&2 | 7205 | 0.22504 | 0.02436 | 0.15543 | 知識惑星に参加して入手してください |
| ecapatdnn | 6.1 | voxceleb1&2 | 7205 | 0.24877 | 0.02480 | 0.16188 | 知識惑星に参加して入手してください |
| eres2netv2 | 6.6 | voxceleb1&2 | 7205 | 0.20710 | 0.02742 | 0.17709 | 知識惑星に参加して入手してください |
| eres2net | 6.6 | voxceleb1&2 | 7205 | 0.20233 | 0.02954 | 0.17377 | 知識惑星に参加して入手してください |
| Resnetse | 7.8 | voxceleb1&2 | 7205 | 0.22567 | 0.03189 | 0.23040 | 知識惑星に参加して入手してください |
| tdnn | 2.6 | voxceleb1&2 | 7205 | 0.23834 | 0.03486 | 0.26792 | 知識惑星に参加して入手してください |
| RES2NET | 5.0 | voxceleb1&2 | 7205 | 0.19472 | 0.04370 | 0.40072 | 知識惑星に参加して入手してください |
| CAM ++ | 6.8 | より大きなデータセット | 2W+ | 0.28 | 0.03182 | 0.23731 | 知識惑星に参加して入手してください |
| eres2net | 55.1 | 他のデータセット | 20W+ | 0.53 | 0.08904 | 0.62130 | 知識惑星に参加して入手してください |
| eres2netv2 | 56.2 | 他のデータセット | 20W+ | 0.52 | 0.08649 | 0.64193 | 知識惑星に参加して入手してください |
| CAM ++ | 6.8 | 他のデータセット | 20W+ | 0.49 | 0.10334 | 0.71200 | 知識惑星に参加して入手してください |
説明:
speed_perturb_3_class: True 。Fbankで、損失関数はAAMLossです。| 前処理方法 | データセット | トレーニングスピーカー | しきい値 | ええ | mindcf | モデルダウンロード |
|---|---|---|---|---|---|---|
| fbank | CN-Celeb | 2796 | 0.14574 | 0.10988 | 0.58955 | 知識惑星に参加して入手してください |
| MFCC | CN-Celeb | 2796 | 0.14868 | 0.11483 | 0.61275 | 知識惑星に参加して入手してください |
| スペクトログラム | CN-Celeb | 2796 | 0.14962 | 0.11613 | 0.60057 | 知識惑星に参加して入手してください |
| melspectrogram | CN-Celeb | 2796 | 0.13458 | 0.12498 | 0.60741 | 知識惑星に参加して入手してください |
| wavlm-base-plus | CN-Celeb | 2796 | 0.14166 | 0.13247 | 0.62451 | 知識惑星に参加して入手してください |
| W2V-BERT-2.0 | CN-Celeb | 2796 | 知識惑星に参加して入手してください | |||
| WAV2VEC2-LARGE-XLSR-53 | CN-Celeb | 2796 | 知識惑星に参加して入手してください | |||
| wavlm-large | CN-Celeb | 2796 | 知識惑星に参加して入手してください |
説明:
CAM++であり、損失関数はAAMLossです。extract_features.py使用して機能を事前に抽出します。つまり、トレーニング中にオーディオのデータ強化は使用されません。w2v-bert-2.0 、 wav2vec2-large-xlsr-53は、多言語データの事前トレーニングから取得されます。 wavlm-base-plusおよびwavlm-largeのトレーニング前のデータは英語のみです。| 損失関数 | データセット | トレーニングスピーカー | しきい値 | ええ | mindcf | モデルダウンロード |
|---|---|---|---|---|---|---|
| aamloss | CN-Celeb | 2796 | 0.14574 | 0.10988 | 0.58955 | 知識惑星に参加して入手してください |
| Sphereface2 | CN-Celeb | 2796 | 0.20377 | 0.11309 | 0.61536 | 知識惑星に参加して入手してください |
| TRIPLETANGULARMARGINLOSS | CN-Celeb | 2796 | 0.28940 | 0.11749 | 0.63735 | 知識惑星に参加して入手してください |
| subcenterloss | CN-Celeb | 2796 | 0.13126 | 0.11775 | 0.56995 | 知識惑星に参加して入手してください |
| Armlloss | CN-Celeb | 2796 | 0.14563 | 0.11805 | 0.57171 | 知識惑星に参加して入手してください |
| アムロス | CN-Celeb | 2796 | 0.12870 | 0.12301 | 0.63263 | 知識惑星に参加して入手してください |
| セロス | CN-Celeb | 2796 | 0.13607 | 0.12684 | 0.65176 | 知識惑星に参加して入手してください |
説明:
CAM++であり、前処理方法はFbankです。extract_features.py使用して機能を事前に抽出します。つまり、トレーニング中にオーディオのデータ強化は使用されません。 conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaPIPを使用してインストールします。コマンドは次のとおりです。
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleソースコードをインストールすることをお勧めします。ソースコードは、最新のコードの使用を保証できます。
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install .著者は、このチュートリアルでCN-Celebを使用しています。このデータセットには、合計約3,000の音声データと65W+の音声データがあります。ダウンロード後、データセットをdatasetディレクトリに減圧する必要があります。さらに、評価したい場合は、CN-CELEBテストセットもダウンロードする必要があります。読者が他のより良いデータセットを持っている場合、それは混合することができますが、PythonのツールモジュールAukitを使用してオーディオ、ノイズリダクション、ミュートを処理することをお勧めします。
1つ目は、データリストを作成することです。データリストの形式は<语音文件路径t语音分类标签>です。このリストの作成は、主に後の読み取りの利便性と、他の音声データセットを使用して読むことの利便性のためです。音声分類タグは、スピーカーの一意のIDを指します。さまざまな音声データセットを同じデータリストに、対応する関数を作成してデータリストを生成することで記述できます。
create_data.pyプログラムを実行して、データの準備を完了します。
python create_data.py上記のプログラムを実行した後、次のデータ形式が生成されます。データをカスタマイズする場合は、次のデータリストを参照してください。前面はオーディオの相対パスであり、背面はオーディオに対応するスピーカーのラベルであり、分類と同じです。テストデータリストのIDはトレーニングIDと同じである必要はないことに注意してください。つまり、テストデータリストの同じ人が同じIDを持っていることを保証している限り、テストデータのスピーカーがトレーニングセットに表示する必要がない場合があります。
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
デフォルトのFBANKプリプロセッシング方法は、構成ファイルで使用されます。他の前処理方法を使用する場合は、構成ファイルのインストール方法を変更できます。特定の値は、あなた自身の状況に応じて変更できます。パラメーターを設定する方法がわからない場合は、このパートを直接削除してデフォルト値を直接使用できます。
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80トレーニングプロセス中に、最初のことはオーディオデータを読み取り、機能を抽出し、最後にトレーニングを実行することです。その中でも、オーディオデータを読むことと機能の抽出も時間がかかるため、事前に機能を抽出することを選択できます。モデルをトレーニングすると、トレーニング速度が高速になるように、機能を直接ロードおよび抽出できます。この抽出された機能はオプションです。適切な機能が抽出されない場合、トレーニングモデルはオーディオデータを読み取り、機能を抽出することから始めます。機能を抽出する手順は次のとおりです。
extract_features.pyを実行して、機能を抽出します。機能はdataset/featuresディレクトリに保存され、新しいデータリストtrain_list_features.txt 、 enroll_list_features.txt 、 trials_list_features.txtを生成します。 python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list 、 dataset_conf.enroll_list 、およびdataset_conf.trials_listをtrain_list_features.txtに変更し、 enroll_list_features.txt 、およびtrials_list_features.txt変更します。train.pyを使用してモデルをトレーニングすると、このプロジェクトは複数のオーディオ前処理方法をサポートしています。 configs/ecapa_tdnn.yml構成ファイルのpreprocess_conf.feature_methodを指定できます。 MelSpectrogramはMELスペクトル、 Spectrogramはスペクトルグラフ、 MFCC MELスペクトル係数係数などです。データ強化方法は、パラメーターaugment_conf_pathで指定できます。トレーニングプロセス中、VisualDLを使用してトレーニングログを保存します。 VisualDLを開始することにより、トレーニング結果をいつでも表示できます。 Startup Command visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyトレーニング出力ログ:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
VisualDlを開始: visualdl --logdir=log --host 0.0.0.0 、VisualDLページは次のとおりです。
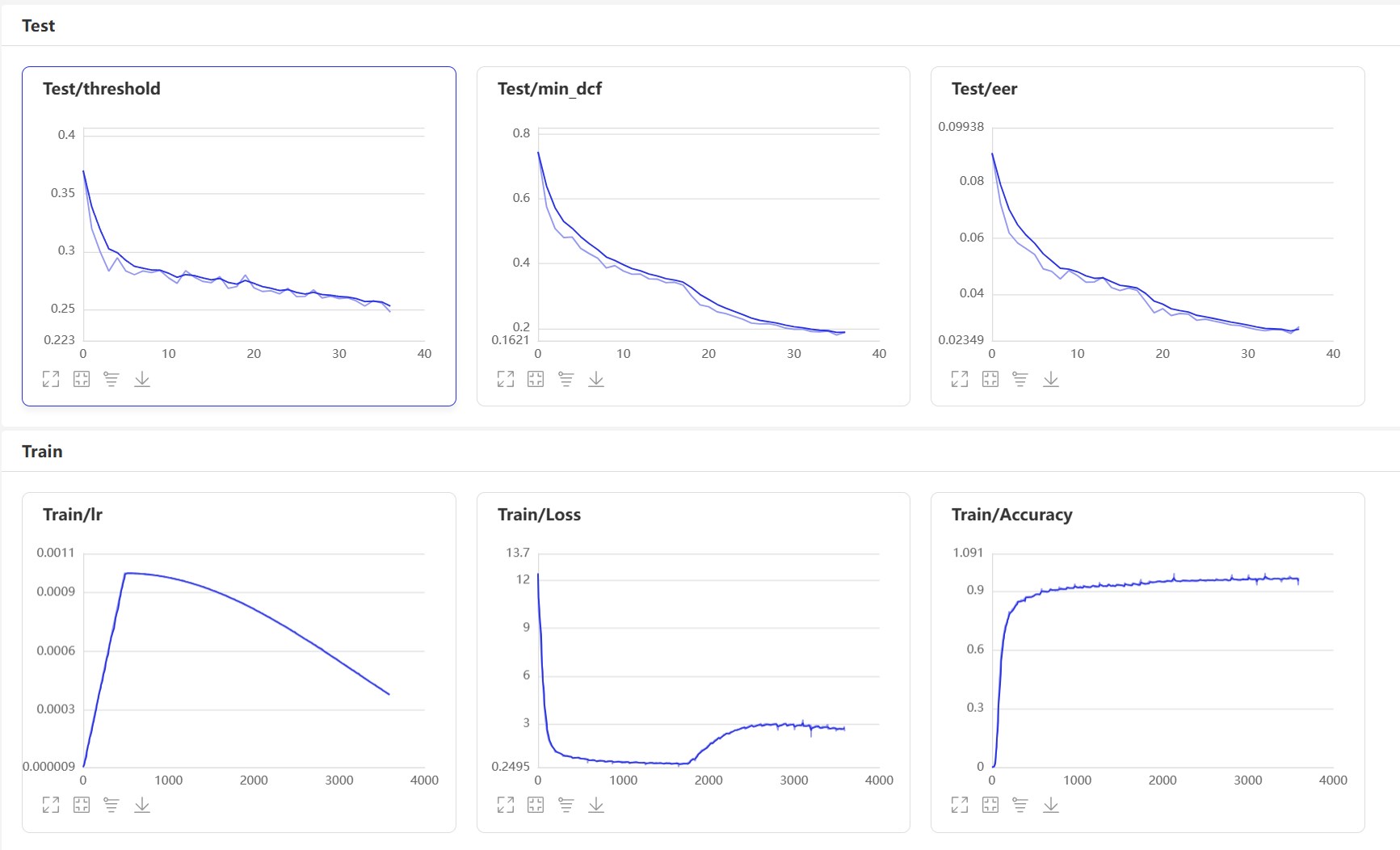
トレーニング後、予測モデルが保存されます。予測モデルを使用してテストセットのオーディオ機能を予測し、オーディオ機能を使用してペアで比較してEERとMINDCFを計算します。
python eval.py出力は以下に似ています。
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
一般的に使用されるいくつかのインターフェイスがあります。その他のインターフェイスについては、 mvector/predict.pyを参照してください。また、声纹对比声纹识别の例を見ることもできます。
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' )VoicePrintの比較を実装し、 infer_contrast.pyプログラムを作成しましょう。まず、いくつかの重要な機能を紹介します。 predict()関数はVoicePrint機能を取得でき、 predict_batch()関数はVoicePrint機能のバッチを取得できます。Contrast contrast()関数は2つのオーディオ間の類似性を比較できます。 register()関数はAudioをVoicePrint Libraryに登録し、 recognition()関数からオーディオを入力し、VoicePrint Libraryからremove_user()て削除します。 VoicePrintライブラリに登録します。 2つのスピーチを入力し、予測関数を介して機能データを取得します。この機能データを使用して、それらの対角線のコサイン値を見つけることができ、結果は知り合いとして使用できます。この認識のthresholdのために、読者はプロジェクトの正確な要件に従ってそれを変更できます。
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wav出力は以下に似ています。
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
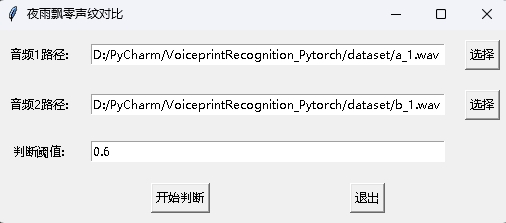
同時に、GUIインターフェイスを使用したVoicePrint比較プログラムも提供されます。 PROGRAMを開始するにはinfer_contrast_gui.pyを実行します。インターフェイスは次のとおりです。それぞれ2つのオーディオを選択します。クリックして判断して、彼らが同じ人であるかどうかを判断します。
ニュース認識では、 register()関数とrecognition()関数が主に使用されます。まず、 register()関数を使用して、オーディオをVoicePrintライブラリに登録します。また、 audio_dbフォルダーにファイルを直接追加することもできます。それを使用すると、 recognition()関数を介して認識を開始できます。オーディオを入力すると、VoicePrintライブラリから必要なスピーカーを識別できます。
上記のVoicePrint認識関数を使用すると、読者は自分のプロジェクトのニーズに応じてVoicePrint認識を完了できます。たとえば、以下で提供するのは、録音を通じてVoicePrint認識を完了することです。まず、音声ライブラリの音声をロードする必要があります。 Voice Libraryフォルダーはaudio_dbであり、ユーザーは車を押した後、3秒間サウンドを録音します。その後、プログラムは自動的にサウンドを記録し、録音されたオーディオを使用してVoicePrint認識を使用して、音声ライブラリの音声に合わせてユーザー情報を取得します。このようにして、読者はそれを変更してサービスリクエストを介してVoicePrint認識を完了することもできます。たとえば、アプリのAPIを提供することもできます。ユーザーがアプリ上のVoicePrintを介してログインすると、録音された音声をaudio_dbエンドに送信してVoicePrint認識を完了し、結果をアプリに返します。
python infer_recognition.py出力は以下に似ています。
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
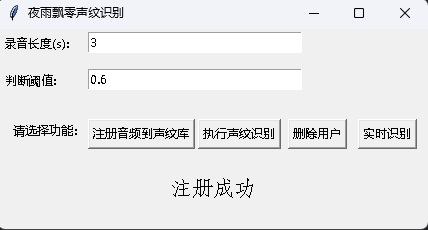
同時に、GUIインターフェイスを備えたVoicePrint認識プログラムも提供されます。 infer_recognition_gui.pyを実行して開始するには、注册音频到声纹库ボタンをクリックし、スピーキングを理解して開始し、3秒間録音し、登録者の名前を入力します。その後、执行声纹识别からすぐに話すことができます。 3秒間録音した後、認識結果を待ちます。删除用户ユーザーを削除できます。实时识别ボタンはリアルタイムで認識でき、リアルタイムで記録および認識できます。
infer_speaker_diarization.pyプログラムを実行し、オーディオパスを入力すると、スピーカーを分離して結果を表示できます。オーディオの長さを10秒以内にしてはならないことをお勧めします。その他の機能については、プログラムパラメーターを表示できます。
python infer_speaker_diarization.py --audio_path=dataset/test_long.wav出力は以下に似ています。
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
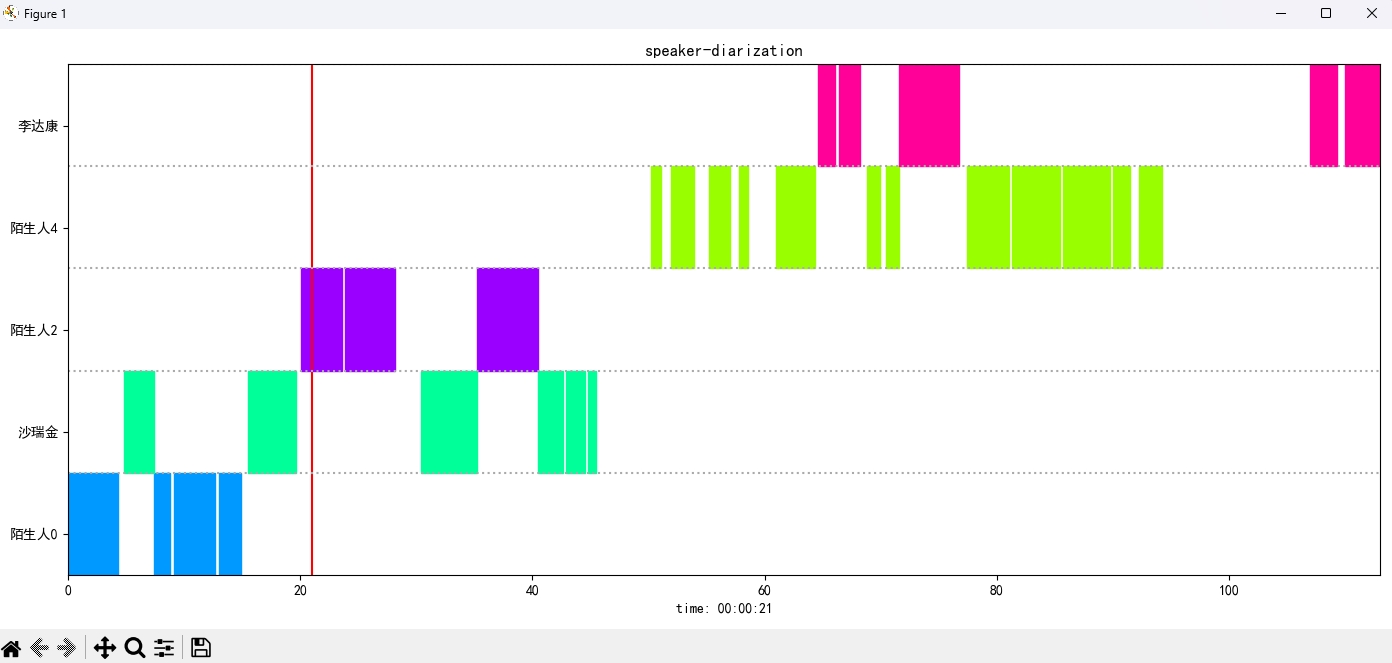
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
結果画像は次のように表示されます。空格バーを介してオーディオの再生を制御できます。位置をクリックして、指定された位置にジャンプします。
また、このプロジェクトは、GUIインターフェイスを備えたプログラムを提供し、 infer_speaker_diarization_gui.pyプログラムを実行します。その他の機能については、プログラムパラメーターを表示できます。
python infer_speaker_diarization_gui.pyこのようなページを開いて、スピーカーを識別できます。
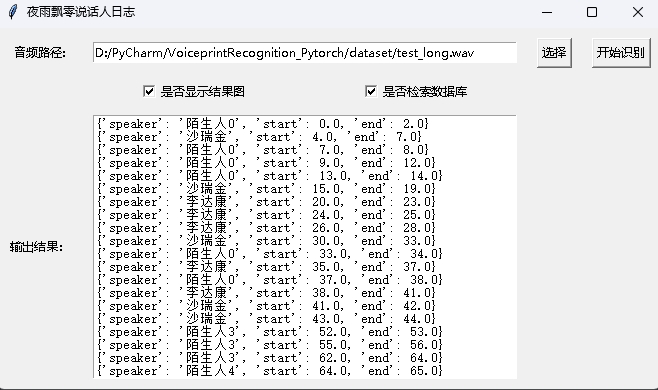
注:スピーカーの名前が中国語である場合、正常に表示するにはインストールフォントを設定する必要があります。一般的に、Windowsをインストールする必要はありませんが、Ubuntuをインストールする必要があります。 Windowsに実際にフォントがない場合は、ここから.ttfフォーマットファイルをダウンロードしてC:WindowsFontsにコピーするだけです。 Ubuntuシステムの操作は次のとおりです。
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )著者をサポートするために1ドルに報いる


