VoiceprintRecognition Pytorch
1.0.0
단순화 된 중국어 | 영어
이 지점은 버전 1.1입니다. 이전 버전 1.0을 사용하려면 1.0 지점에서 사용하십시오. 이 프로젝트는 ECAPATDNN, RESNETSE, ERES2NET 및 CAM ++와 같은 다양한 고급 VoicePrint 인식 모델을 사용합니다. 앞으로 더 많은 모델이 지원 될 것이라는 것은 배제되지 않습니다. 동시에이 프로젝트는 Melspectrogram, Spectrogram, MFCC 및 FBank와 같은 다양한 데이터 전처리 방법을 지원합니다. Arcface 손실, Arcface 손실 : 프로젝트의 Aamloss에 해당하는 추가 각도 마진 손실 (부가 각도 간격 손실 함수), 고유 벡터 및 가중치를 정규화하고 각도 간격 M을 θ에 추가합니다. 각도 간격은 코사인 간격보다 각도에 더 직접적인 영향을 미칩니다. 또한 Amloss, Armloss 및 Celoss와 같은 다양한 손실 기능도 지원합니다.
이 프로젝트가 도움이된다면 나중에 찾을 수 없도록 Welcome Star.
모든 사람은 코드를 스캔하여 지식 행성 또는 QQ 그룹에 들어가서 논의 할 수 있습니다. Knowledge Planet은 프로젝트 모델 파일 및 블로거의 기타 관련 프로젝트 모델 파일 및 기타 리소스를 제공합니다.
사용 환경 :
모델 논문 :
| 모델 | 매개 변수 (m) | 데이터 세트 | 스피커를 훈련시킵니다 | 한계점 | eer | Mindcf | 모델 다운로드 |
|---|---|---|---|---|---|---|---|
| eres2netv2 | 6.6 | CN-CELEB | 2796 | 0.20089 | 0.08071 | 0.45705 | 지식 행성에 합류하여 얻습니다 |
| eres2net | 6.6 | CN-CELEB | 2796 | 0.20014 | 0.08132 | 0.45544 | 지식 행성에 합류하여 얻습니다 |
| 캠 ++ | 6.8 | CN-CELEB | 2796 | 0.23323 | 0.08332 | 0.48536 | 지식 행성에 합류하여 얻습니다 |
| resnetse | 7.8 | CN-CELEB | 2796 | 0.19066 | 0.08544 | 0.49142 | 지식 행성에 합류하여 얻습니다 |
| Ecapatdnn | 6.1 | CN-CELEB | 2796 | 0.23646 | 0.09259 | 0.51378 | 지식 행성에 합류하여 얻습니다 |
| tdnn | 2.6 | CN-CELEB | 2796 | 0.23858 | 0.10825 | 0.59545 | 지식 행성에 합류하여 얻습니다 |
| res2net | 5.0 | CN-CELEB | 2796 | 0.19526 | 0.12436 | 0.65347 | 지식 행성에 합류하여 얻습니다 |
| 캠 ++ | 6.8 | 더 큰 데이터 세트 | 2W+ | 0.33 | 0.07874 | 0.52524 | 지식 행성에 합류하여 얻습니다 |
| eres2net | 55.1 | 다른 데이터 세트 | 20W+ | 0.36 | 0.02936 | 0.18355 | 지식 행성에 합류하여 얻습니다 |
| eres2netv2 | 56.2 | 다른 데이터 세트 | 20W+ | 0.36 | 0.03847 | 0.24301 | 지식 행성에 합류하여 얻습니다 |
| 캠 ++ | 6.8 | 다른 데이터 세트 | 20W+ | 0.29 | 0.04765 | 0.31436 | 지식 행성에 합류하여 얻습니다 |
설명 :
speed_perturb_3_class: True 사용하여 분류 크기를 트리플하십시오.Fbank 이고 손실 함수는 AAMLoss 입니다.| 모델 | 매개 변수 (m) | 데이터 세트 | 스피커를 훈련시킵니다 | 한계점 | eer | Mindcf | 모델 다운로드 |
|---|---|---|---|---|---|---|---|
| 캠 ++ | 6.8 | Voxceleb1 & 2 | 7205 | 0.22504 | 0.02436 | 0.15543 | 지식 행성에 합류하여 얻습니다 |
| Ecapatdnn | 6.1 | Voxceleb1 & 2 | 7205 | 0.24877 | 0.02480 | 0.16188 | 지식 행성에 합류하여 얻습니다 |
| eres2netv2 | 6.6 | Voxceleb1 & 2 | 7205 | 0.20710 | 0.02742 | 0.17709 | 지식 행성에 합류하여 얻습니다 |
| eres2net | 6.6 | Voxceleb1 & 2 | 7205 | 0.20233 | 0.02954 | 0.17377 | 지식 행성에 합류하여 얻습니다 |
| resnetse | 7.8 | Voxceleb1 & 2 | 7205 | 0.22567 | 0.03189 | 0.23040 | 지식 행성에 합류하여 얻습니다 |
| tdnn | 2.6 | Voxceleb1 & 2 | 7205 | 0.23834 | 0.03486 | 0.26792 | 지식 행성에 합류하여 얻습니다 |
| res2net | 5.0 | Voxceleb1 & 2 | 7205 | 0.19472 | 0.04370 | 0.40072 | 지식 행성에 합류하여 얻습니다 |
| 캠 ++ | 6.8 | 더 큰 데이터 세트 | 2W+ | 0.28 | 0.03182 | 0.23731 | 지식 행성에 합류하여 얻습니다 |
| eres2net | 55.1 | 다른 데이터 세트 | 20W+ | 0.53 | 0.08904 | 0.62130 | 지식 행성에 합류하여 얻습니다 |
| eres2netv2 | 56.2 | 다른 데이터 세트 | 20W+ | 0.52 | 0.08649 | 0.64193 | 지식 행성에 합류하여 얻습니다 |
| 캠 ++ | 6.8 | 다른 데이터 세트 | 20W+ | 0.49 | 0.10334 | 0.71200 | 지식 행성에 합류하여 얻습니다 |
설명 :
speed_perturb_3_class: True 사용하여 분류 크기를 트리플하십시오.Fbank 이고 손실 함수는 AAMLoss 입니다.| 전처리 방법 | 데이터 세트 | 스피커를 훈련시킵니다 | 한계점 | eer | Mindcf | 모델 다운로드 |
|---|---|---|---|---|---|---|
| F- 뱅크 | CN-CELEB | 2796 | 0.14574 | 0.10988 | 0.58955 | 지식 행성에 합류하여 얻습니다 |
| MFCC | CN-CELEB | 2796 | 0.14868 | 0.11483 | 0.61275 | 지식 행성에 합류하여 얻습니다 |
| 스펙트로 그램 | CN-CELEB | 2796 | 0.14962 | 0.11613 | 0.60057 | 지식 행성에 합류하여 얻습니다 |
| melspectrogram | CN-CELEB | 2796 | 0.13458 | 0.12498 | 0.60741 | 지식 행성에 합류하여 얻습니다 |
| Wavlm-base-plus | CN-CELEB | 2796 | 0.14166 | 0.13247 | 0.62451 | 지식 행성에 합류하여 얻습니다 |
| W2V-Bert-2.0 | CN-CELEB | 2796 | 지식 행성에 합류하여 얻습니다 | |||
| WAV2VEC2-LARGE-XLSR-53 | CN-CELEB | 2796 | 지식 행성에 합류하여 얻습니다 | |||
| Wavlm-Large | CN-CELEB | 2796 | 지식 행성에 합류하여 얻습니다 |
설명 :
CAM++ 이고 손실 함수는 AAMLoss 입니다.extract_features.py 사용하여 미리 기능을 추출하므로 교육 중에 오디오에 대한 데이터 향상이 사용되지 않습니다.w2v-bert-2.0 , wav2vec2-large-xlsr-53 은 다국어 데이터의 사전 훈련으로부터 얻어진다. wavlm-base-plus 및 wavlm-large 의 사전 훈련 데이터는 영어로 만 있습니다.| 손실 기능 | 데이터 세트 | 스피커를 훈련시킵니다 | 한계점 | eer | Mindcf | 모델 다운로드 |
|---|---|---|---|---|---|---|
| Aamloss | CN-CELEB | 2796 | 0.14574 | 0.10988 | 0.58955 | 지식 행성에 합류하여 얻습니다 |
| sphereface2 | CN-CELEB | 2796 | 0.20377 | 0.11309 | 0.61536 | 지식 행성에 합류하여 얻습니다 |
| 트리플 탕 큘러 마르진 로스 | CN-CELEB | 2796 | 0.28940 | 0.11749 | 0.63735 | 지식 행성에 합류하여 얻습니다 |
| 하위 센터 로스 | CN-CELEB | 2796 | 0.13126 | 0.11775 | 0.56995 | 지식 행성에 합류하여 얻습니다 |
| armlloss | CN-CELEB | 2796 | 0.14563 | 0.11805 | 0.57171 | 지식 행성에 합류하여 얻습니다 |
| Amloss | CN-CELEB | 2796 | 0.12870 | 0.12301 | 0.63263 | 지식 행성에 합류하여 얻습니다 |
| Celoss | CN-CELEB | 2796 | 0.13607 | 0.12684 | 0.65176 | 지식 행성에 합류하여 얻습니다 |
설명 :
CAM++ 이고, 사전 처리 방법은 Fbank 입니다.extract_features.py 사용하여 미리 기능을 추출하므로 교육 중에 오디오에 대한 데이터 향상이 사용되지 않습니다. conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaPIP를 사용하여 설치하고 명령은 다음과 같습니다.
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simple최신 코드를 사용할 수있는 소스 코드를 설치하는 것이 좋습니다 .
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . 저자는이 튜토리얼에서 CN-CELEB를 사용합니다. 이 데이터 세트에는 총 약 3,000 개의 음성 데이터와 65W+ 음성 데이터가 있습니다. 다운로드 후 데이터 세트를 dataset 디렉토리로 압축해야합니다. 또한 평가하려면 CN-CELEB 테스트 세트도 다운로드해야합니다. 독자에게 다른 더 나은 데이터 세트가있는 경우 함께 혼합 될 수 있지만 Python의 도구 모듈 Aukit을 사용하여 오디오, 노이즈 감소 및 음소거를 처리하는 것이 가장 좋습니다.
첫 번째는 데이터 목록을 만드는 것입니다. 데이터 목록의 형식은 <语音文件路径t语音分类标签> 입니다. 이 목록을 작성하는 것은 주로 나중에 읽는 편의성과 다른 음성 데이터 세트를 사용하여 읽는 편의를위한 것입니다. 음성 분류 태그는 스피커의 고유 ID를 나타냅니다. 다른 음성 데이터 세트는 해당 기능을 작성하여 데이터 목록을 생성하여 동일한 데이터 목록에 작성할 수 있습니다.
데이터 준비를 완료하려면 create_data.py 프로그램을 실행하십시오.
python create_data.py위 프로그램을 실행하면 다음 데이터 형식이 생성됩니다. 데이터를 사용자 정의하려면 다음 데이터 목록을 참조하십시오. 전면은 오디오의 상대 경로이며, 뒷면은 오디오에 해당하는 스피커의 레이블이며, 이는 분류와 동일합니다. 테스트 데이터 목록의 ID는 교육 ID와 동일 할 필요 가 없으며, 이는 테스트 데이터 목록의 동일한 사람이 동일한 사람이 동일한 ID를 갖도록하는 한 테스트 데이터의 스피커가 교육 세트에 나타날 필요가 없음을 의미합니다.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
기본 FBANK 전처리 방법은 구성 파일에 사용됩니다. 다른 전처리 방법을 사용하려면 구성 파일에서 설치 방법을 수정할 수 있습니다. 특정 값은 자신의 상황에 따라 수정 될 수 있습니다. 매개 변수를 설정하는 방법이 확실하지 않은 경우이 부분을 직접 삭제하고 기본값을 직접 사용할 수 있습니다.
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80교육 과정에서 첫 번째는 오디오 데이터를 읽고 기능을 추출한 다음 최종적으로 교육을 수행하는 것입니다. 그중에서도 오디오 데이터를 읽고 기능을 추출하는 것도 시간이 소요되므로 사전에 기능을 추출하도록 선택할 수 있습니다. 모델을 훈련 시키면 기능을 직접로드하고 추출하여 교육 속도가 더 빨라질 수 있습니다. 이 추출 된 기능은 선택 사항입니다. 좋은 기능이 추출되지 않으면 오디오 데이터를 읽은 다음 기능을 추출하여 교육 모델이 시작됩니다. 기능을 추출하는 단계는 다음과 같습니다.
extract_features.py 실행하십시오. 이 기능은 dataset/features 디렉토리에 저장되고 새 데이터 목록을 생성하고 train_list_features.txt , enroll_list_features.txt 및 trials_list_features.txt 생성합니다. python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list , dataset_conf.enroll_list 및 dataset_conf.trials_list to train_list_features.txt , enroll_list_features.txt 및 trials_list_features.txt 수정하십시오. train.py 사용하여 모델을 훈련시키는이 프로젝트는 여러 오디오 전처리 방법을 지원합니다. configs/ecapa_tdnn.yml 구성 파일의 매개 변수 preprocess_conf.feature_method 지정할 수 있습니다. MelSpectrogram 은 MEL 스펙트럼이며, Spectrogram 은 스펙트럼 그래프, MFCC MEL 스펙트럼 CEPSPECTRAL 계수 등입니다. 데이터 향상 방법은 매개 변수 augment_conf_path 에 의해 지정 될 수 있습니다. 훈련 과정에서 VisualDL은 교육 로그를 저장하는 데 사용됩니다. VisualDL을 시작하면 언제든지 교육 결과를 볼 수 있습니다. 시작 명령 visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.py교육 출력 로그 :
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
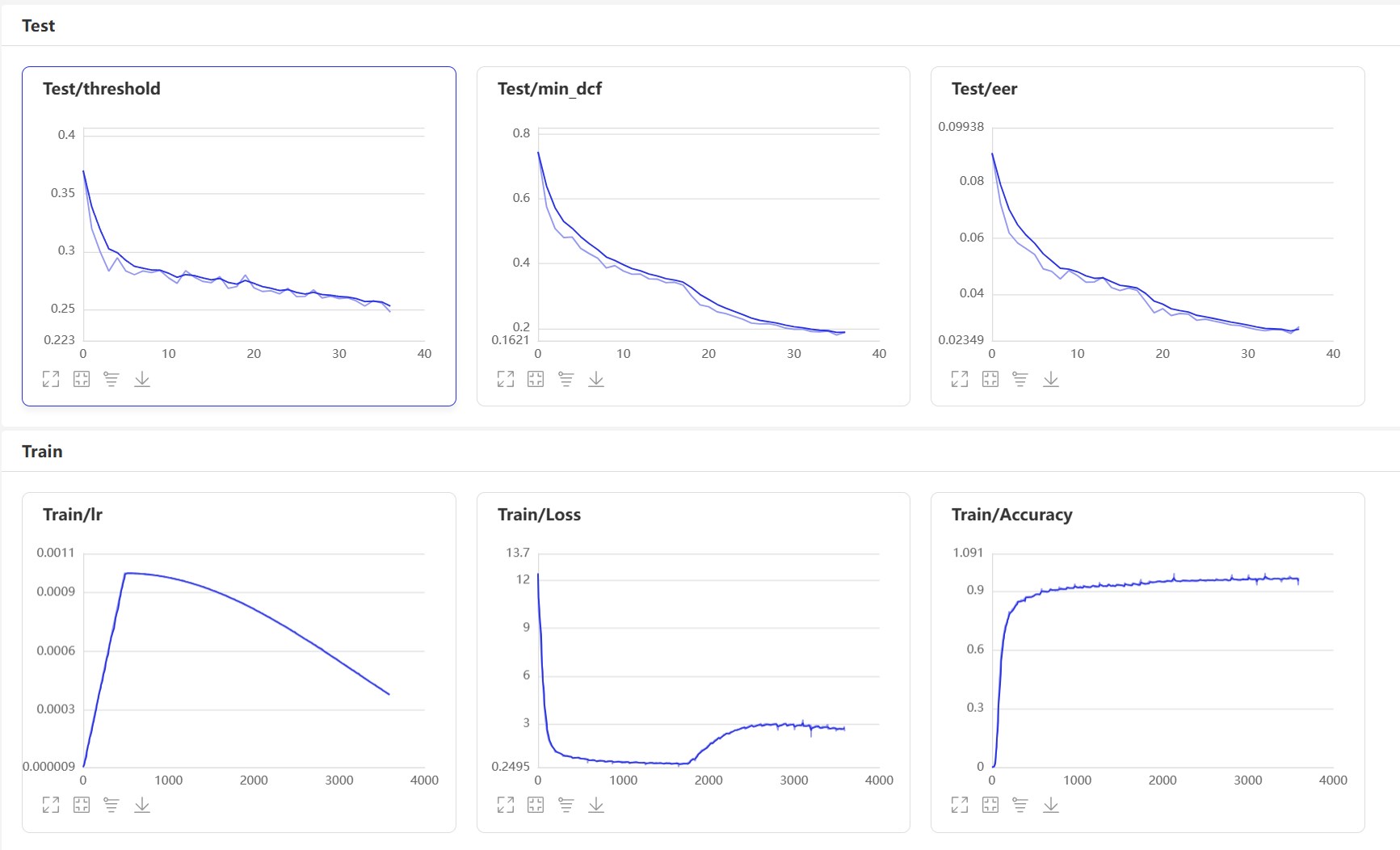
start visualDl : visualdl --logdir=log --host 0.0.0.0 , visualdl 페이지는 다음과 같습니다.
훈련 후 예측 모델이 저장됩니다. 예측 모델을 사용하여 테스트 세트의 오디오 기능을 예측 한 다음 오디오 기능을 사용하여 EER 및 MINDCF를 계산하기 위해 쌍으로 비교합니다.
python eval.py출력은 다음과 유사합니다.
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
다음은 일반적으로 사용되는 몇 가지 인터페이스입니다. 더 많은 인터페이스는 mvector/predict.py 를 참조하십시오.声纹对比声纹识别의 예를 볼 수도 있습니다.
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) VoicePrint 비교를 구현하고 infer_contrast.py 프로그램을 만들어 봅시다. 먼저 몇 가지 중요한 기능을 소개합니다. predict() 함수는 음성 사업 기능을 얻을 수 있으며 predict_batch() 함수는 VoicePrint 기능의 배치를 얻을 수 있으며, contrast() 함수는 두 오디오 간의 유사성을 비교할 수 있으며 register() 함수는 오디오를 recognition() 라이브러리에 등록하고, 기능을 비교하고 VoicePrint 라이브러리에서 유입되어 remove_user() 기능을 비교하고 인식합니다. VoicePrint 라이브러리에 등록하십시오. 우리는 두 개의 연설을 입력하고 예측 기능을 통해 기능 데이터를 얻습니다. 이 기능 데이터를 사용하면 대각선 코사인 값을 찾을 수 있으며 결과는 지인으로 사용할 수 있습니다. 이 인식의 threshold 위해 독자는 프로젝트의 정확도 요구 사항에 따라이를 수정할 수 있습니다.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wav출력은 다음과 유사합니다.
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
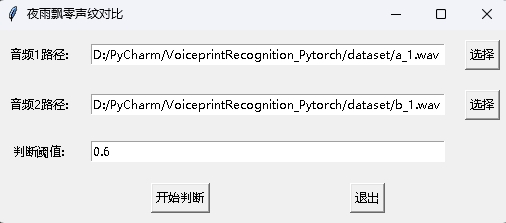
동시에 GUI 인터페이스가있는 VoicePrint 비교 프로그램도 제공됩니다. 프로그램을 시작하려면 infer_contrast_gui.py 실행하십시오. 인터페이스는 다음과 같습니다. 각각 두 개의 오디오를 선택하십시오. 클릭하여 판단하기 시작하여 동일한 사람인지 판단하십시오.
뉴스 인식에서 register() 함수 및 recognition() 함수가 주로 사용됩니다. 먼저 register() 함수를 사용하여 오디오를 VoicePrint 라이브러리에 등록하십시오. 파일을 audio_db 폴더에 직접 추가 할 수도 있습니다. 그것을 사용할 때는 recognition() 함수를 통해 인식을 시작할 수 있습니다. 오디오를 입력하면 VoicePrint 라이브러리에서 필요한 스피커를 식별 할 수 있습니다.
위의 VoicePrint 인식 기능을 통해 독자는 자체 프로젝트 요구에 따라 VoicePrint 인식을 완료 할 수 있습니다. 예를 들어, 아래에서 제공하는 것은 녹음을 통해 VoicePrint 인식을 완료하는 것입니다. 첫째, 음성 라이브러리의 음성을로드해야합니다. 음성 라이브러리 폴더는 audio_db 이며 사용자는 자동차를 누른 후 3 초 동안 사운드를 기록합니다. 그런 다음 프로그램은 자동으로 사운드를 녹음하고 음성 라이브러리의 음성과 일치하고 사용자 정보를 얻기 위해 VoicePrint 인식을 위해 녹음 된 오디오를 사용합니다. 이러한 방식으로 독자는 서비스 요청을 통해 VoicePrint 인식을 완료하기 위해이를 수정할 수 있습니다. 예를 들어 API가 호출 할 API를 제공합니다. 사용자가 앱에서 VoicePrint를 통해 로그인하면 기록 된 음성을 백엔드로 보내어 VoyPrint 인식을 완료 한 다음 사용자가 VoicePrint에 등록하고 audio_db 폴더에 음성 데이터를 성공적으로 저장하는 경우 결과를 앱에 반환합니다.
python infer_recognition.py출력은 다음과 유사합니다.
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
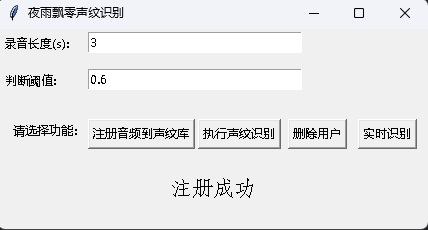
동시에 GUI 인터페이스가있는 VoicePrint 인식 프로그램도 제공됩니다. infer_recognition_gui.py 를 실행하려면 시작하려면注册音频到声纹库버튼 버튼을 클릭하고 말하기를 시작하고 3 초 동안 기록한 다음 등록자의 이름을 입력하십시오. 그런 다음执行声纹识别다음 즉시 말할 수 있습니다. 3 초 동안 녹음 한 후 인식 결과를 기다리십시오.删除用户버튼은 사용자를 삭제할 수 있습니다.实时识别버튼은 실시간으로 인식 할 수 있으며 실시간으로 기록하고 인식 할 수 있습니다.
infer_speaker_diarization.py 프로그램을 실행하고 오디오 경로를 입력하면 스피커를 분리하고 결과를 표시 할 수 있습니다. 오디오 길이는 10 초 이상이되지 않아야합니다. 더 많은 기능을 보려면 프로그램 매개 변수를 볼 수 있습니다.
python infer_speaker_diarization.py --audio_path=dataset/test_long.wav출력은 다음과 유사합니다.
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
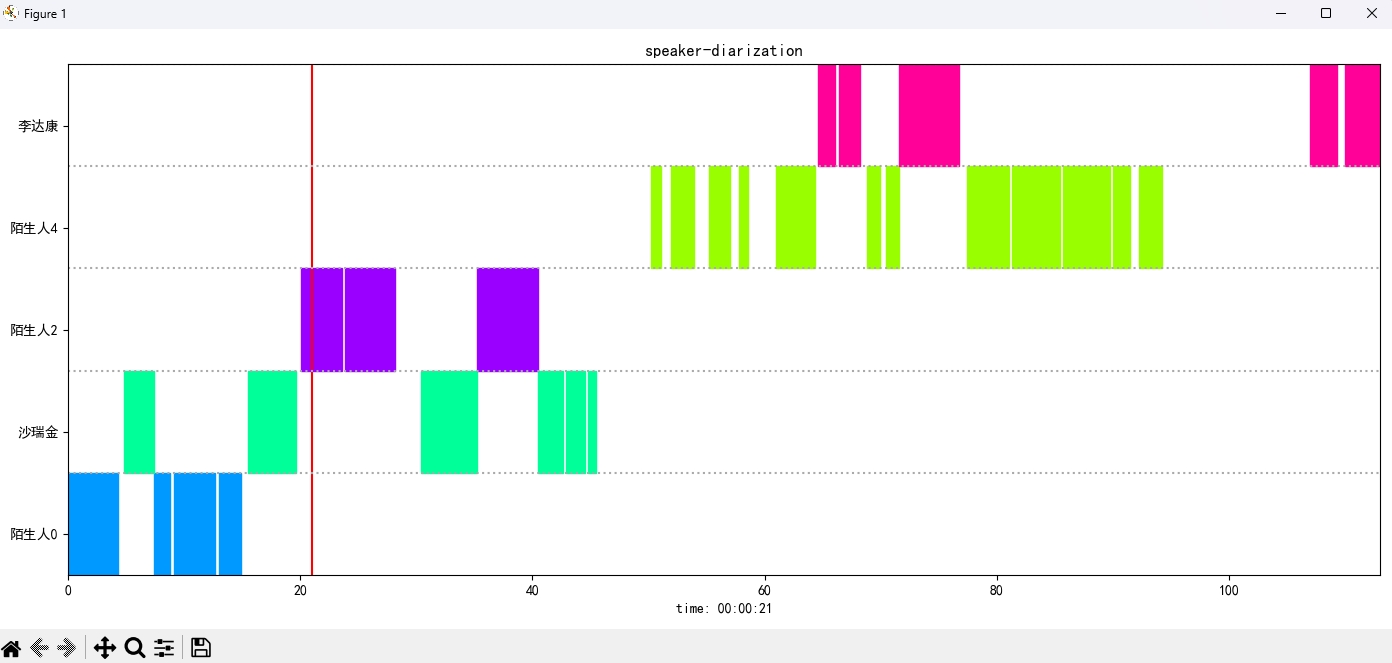
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
결과 이미지는 다음과 같이 표시됩니다.空格막대를 통해 오디오 재생을 제어 할 수 있습니다. 위치를 클릭하여 지정된 위치로 점프하십시오.
이 프로젝트는 또한 GUI 인터페이스와 함께 프로그램을 제공하여 infer_speaker_diarization_gui.py 프로그램을 실행합니다. 더 많은 기능을 보려면 프로그램 매개 변수를 볼 수 있습니다.
python infer_speaker_diarization_gui.py해당 페이지를 열어 스피커를 식별 할 수 있습니다.
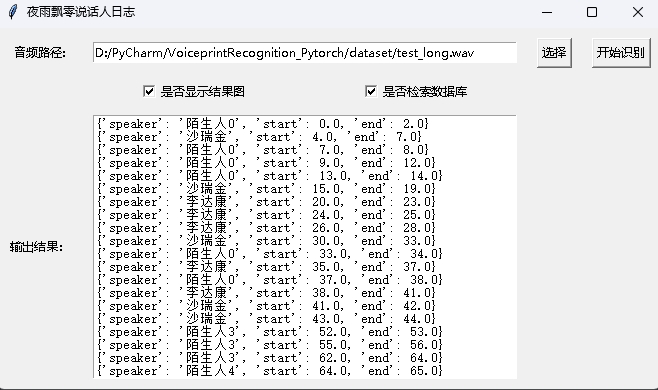
참고 : 스피커 이름이 중국어 인 경우 설치 글꼴을 정상적으로 표시하도록 설정해야합니다. 일반적으로 Windows를 설치할 필요는 없지만 Ubuntu를 설치해야합니다. Windows에 실제로 글꼴이 누락 된 경우 여기에서 .ttf 형식 파일 만 다운로드하여 C:WindowsFonts 로 복사하면됩니다. 우분투 시스템 작업은 다음과 같습니다.
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )저자를 지원하기 위해 1 달러를 보상하십시오


