VoiceprintRecognition Pytorch
1.0.0
China yang disederhanakan | Bahasa inggris
Cabang ini adalah versi 1.1. Jika Anda ingin menggunakan versi 1.0 sebelumnya, silakan gunakan di cabang 1.0. Proyek ini menggunakan berbagai model pengenalan voiceprint canggih seperti Ecapatdnn, Resnetse, ERES2NET, dan CAM ++. Tidak dikesampingkan bahwa lebih banyak model akan didukung di masa depan. Pada saat yang sama, proyek ini juga mendukung berbagai metode preprocessing data seperti Melspectrogram, Spectrogram, MFCC, dan FBank. Kehilangan arcface, kehilangan arcface: Kehilangan margin sudut aditif (fungsi kehilangan interval sudut aditif), sesuai dengan aamloss dalam proyek, menormalkan vektor dan bobot eigen, dan menambahkan interval sudut M ke θ. Interval sudut memiliki dampak yang lebih langsung pada sudut daripada interval kosinus. Selain itu, ini juga mendukung berbagai fungsi kerugian seperti Amloss, Armloss, dan Celoss.
Jika proyek ini bermanfaat bagi Anda, selamat datang bintang untuk menghindarinya tidak ditemukan nanti.
Setiap orang dipersilakan untuk memindai kode untuk memasuki planet pengetahuan atau grup QQ untuk dibahas. Planet Pengetahuan Menyediakan file model proyek dan proyek model terkait blogger lainnya, serta sumber daya lainnya.
Lingkungan Penggunaan:
Model Paper:
| Model | Params (m) | Dataset | pembicara kereta api | ambang | Eer | Mindcf | Download model |
|---|---|---|---|---|---|---|---|
| ERES2NETV2 | 6.6 | CN-Celeb | 2796 | 0.20089 | 0,08071 | 0.45705 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Eres2net | 6.6 | CN-Celeb | 2796 | 0.20014 | 0,08132 | 0.45544 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Cam ++ | 6.8 | CN-Celeb | 2796 | 0.23323 | 0.08332 | 0.48536 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Resnetse | 7.8 | CN-Celeb | 2796 | 0.19066 | 0,08544 | 0.49142 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Ecapatdnn | 6.1 | CN-Celeb | 2796 | 0.23646 | 0,09259 | 0.51378 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Tdnn | 2.6 | CN-Celeb | 2796 | 0.23858 | 0.10825 | 0.59545 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Res2net | 5.0 | CN-Celeb | 2796 | 0.19526 | 0.12436 | 0.65347 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Cam ++ | 6.8 | Kumpulan data yang lebih besar | 2W+ | 0.33 | 0.07874 | 0.52524 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Eres2net | 55.1 | Set data lainnya | 20W+ | 0.36 | 0.02936 | 0.18355 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| ERES2NETV2 | 56.2 | Set data lainnya | 20W+ | 0.36 | 0.03847 | 0.24301 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Cam ++ | 6.8 | Set data lainnya | 20W+ | 0.29 | 0,04765 | 0.31436 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
menjelaskan:
speed_perturb_3_class: True .Fbank dan fungsi kerugian adalah AAMLoss .| Model | Params (m) | Dataset | pembicara kereta api | ambang | Eer | Mindcf | Download model |
|---|---|---|---|---|---|---|---|
| Cam ++ | 6.8 | Voxceleb1 & 2 | 7205 | 0.22504 | 0,02436 | 0.15543 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Ecapatdnn | 6.1 | Voxceleb1 & 2 | 7205 | 0.24877 | 0.02480 | 0.16188 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| ERES2NETV2 | 6.6 | Voxceleb1 & 2 | 7205 | 0.20710 | 0,02742 | 0.17709 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Eres2net | 6.6 | Voxceleb1 & 2 | 7205 | 0.20233 | 0.02954 | 0.17377 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Resnetse | 7.8 | Voxceleb1 & 2 | 7205 | 0.22567 | 0,03189 | 0.23040 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Tdnn | 2.6 | Voxceleb1 & 2 | 7205 | 0.23834 | 0,03486 | 0.26792 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Res2net | 5.0 | Voxceleb1 & 2 | 7205 | 0.19472 | 0,04370 | 0.40072 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Cam ++ | 6.8 | Kumpulan data yang lebih besar | 2W+ | 0.28 | 0,03182 | 0.23731 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Eres2net | 55.1 | Set data lainnya | 20W+ | 0,53 | 0.08904 | 0.62130 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| ERES2NETV2 | 56.2 | Set data lainnya | 20W+ | 0,52 | 0,08649 | 0.64193 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Cam ++ | 6.8 | Set data lainnya | 20W+ | 0.49 | 0.10334 | 0.71200 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
menjelaskan:
speed_perturb_3_class: True .Fbank dan fungsi kerugian adalah AAMLoss .| Metode preprocessing | Dataset | pembicara kereta api | ambang | Eer | Mindcf | Download model |
|---|---|---|---|---|---|---|
| Fbank | CN-Celeb | 2796 | 0.14574 | 0.10988 | 0.58955 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| MFCC | CN-Celeb | 2796 | 0.14868 | 0.11483 | 0.61275 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Spektrogram | CN-Celeb | 2796 | 0.14962 | 0.11613 | 0.60057 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Melk -Melspectrogram | CN-Celeb | 2796 | 0.13458 | 0.12498 | 0.60741 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| WAVLM-BASE-PLUS | CN-Celeb | 2796 | 0.14166 | 0.13247 | 0.62451 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| W2V-Bert-2.0 | CN-Celeb | 2796 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan | |||
| wav2vec2-large-xlsr-53 | CN-Celeb | 2796 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan | |||
| WAVLM-Large | CN-Celeb | 2796 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
menjelaskan:
CAM++ , dan fungsi kerugian adalah AAMLoss .extract_features.py untuk mengekstrak fitur terlebih dahulu, yang berarti bahwa peningkatan data untuk audio tidak digunakan selama pelatihan.w2v-bert-2.0 , wav2vec2-large-xlsr-53 diperoleh dari pra-pelatihan data multibahasa. Data pra-pelatihan wavlm-base-plus dan wavlm-large hanya dalam bahasa Inggris.| Fungsi kerugian | Dataset | pembicara kereta api | ambang | Eer | Mindcf | Download model |
|---|---|---|---|---|---|---|
| Aamloss | CN-Celeb | 2796 | 0.14574 | 0.10988 | 0.58955 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Sphereface2 | CN-Celeb | 2796 | 0.20377 | 0.11309 | 0.61536 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Tripletangularmarginloss | CN-Celeb | 2796 | 0.28940 | 0.11749 | 0.63735 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| SubCenterLoss | CN-Celeb | 2796 | 0.13126 | 0.11775 | 0.56995 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Armlloss | CN-Celeb | 2796 | 0.14563 | 0.11805 | 0.57171 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Amloss | CN-Celeb | 2796 | 0.12870 | 0.12301 | 0.63263 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Celoss | CN-Celeb | 2796 | 0.13607 | 0.12684 | 0.65176 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
menjelaskan:
CAM++ , dan metode preprocessing adalah Fbank .extract_features.py untuk mengekstrak fitur terlebih dahulu, yang berarti bahwa peningkatan data untuk audio tidak digunakan selama pelatihan. conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaGunakan PIP untuk menginstal, perintahnya adalah sebagai berikut:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleDisarankan untuk menginstal kode sumber , yang dapat memastikan penggunaan kode terbaru.
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . Penulis menggunakan CN-Celeb dalam tutorial ini. Kumpulan data ini memiliki total sekitar 3.000 data suara dan data suara 65W+. Setelah mengunduh, Anda perlu mendekompresi dataset ke direktori dataset . Selain itu, jika Anda ingin mengevaluasi, Anda juga perlu mengunduh set tes CN-Celeb. Jika pembaca memiliki set data lain yang lebih baik, itu dapat dicampur bersama, tetapi yang terbaik adalah menggunakan modul alat Python Aukit untuk memproses audio, pengurangan kebisingan dan bisu.
Yang pertama adalah membuat daftar data. Format daftar data adalah <语音文件路径t语音分类标签> . Membuat daftar ini terutama untuk kenyamanan membaca nanti dan kenyamanan membaca menggunakan set data suara lainnya. Tag klasifikasi suara merujuk ke ID unik speaker. Set data suara yang berbeda dapat ditulis dalam daftar data yang sama dengan menulis fungsi yang sesuai untuk menghasilkan daftar data.
Jalankan program create_data.py untuk menyelesaikan persiapan data.
python create_data.pySetelah menjalankan program di atas, format data berikut akan dihasilkan. Jika Anda ingin menyesuaikan data, lihat daftar data berikut. Bagian depan adalah jalur relatif audio, dan bagian belakang adalah label speaker yang sesuai dengan audio, yang sama dengan klasifikasi. Perhatikan bahwa ID dari daftar data uji tidak perlu sama dengan ID pelatihan, yang berarti bahwa pembicara data tes mungkin tidak perlu muncul dalam set pelatihan, selama orang yang sama dalam daftar data tes memastikan bahwa orang yang sama memiliki ID yang sama.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
Metode preprocessing fbank default digunakan dalam file konfigurasi. Jika Anda ingin menggunakan metode preprocessing lainnya, Anda dapat memodifikasi metode instalasi dalam file konfigurasi. Nilai spesifik dapat dimodifikasi sesuai dengan situasi Anda sendiri. Jika Anda tidak yakin cara mengatur parameter, Anda dapat menghapus bagian ini secara langsung dan menggunakan nilai default secara langsung.
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80Selama proses pelatihan, hal pertama adalah membaca data audio, kemudian mengekstrak fitur, dan akhirnya melaksanakan pelatihan. Di antara mereka, membaca data audio dan fitur ekstrak juga memakan waktu, sehingga kami dapat memilih untuk mengekstrak fitur terlebih dahulu. Jika kita melatih model, kita dapat secara langsung memuat dan mengekstrak fitur, sehingga kecepatan pelatihan akan lebih cepat. Fitur yang diekstraksi ini opsional. Jika tidak ada fitur bagus yang diekstraksi, model pelatihan akan dimulai dengan membaca data audio dan kemudian mengekstraksi fitur. Langkah -langkah untuk mengekstrak fitur adalah sebagai berikut:
extract_features.py untuk mengekstrak fitur. Fitur akan disimpan dalam direktori dataset/features dan menghasilkan daftar data baru train_list_features.txt , enroll_list_features.txt dan trials_list_features.txt . python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list , dataset_conf.enroll_list , dan dataset_conf.trials_list ke train_list_features.txt , enroll_list_features.txt , dan trials_list_features.txt . Menggunakan train.py untuk melatih model, proyek ini mendukung beberapa metode preprocessing audio. Parameter preprocess_conf.feature_method dari file konfigurasi configs/ecapa_tdnn.yml dapat ditentukan. MelSpectrogram adalah spektrum Mel, Spectrogram adalah grafik spektrum, koefisien spektrum spektrum MFCC MEL, dll. Metode peningkatan data dapat ditentukan oleh parameter augment_conf_path . Selama proses pelatihan, VisualDL akan digunakan untuk menyimpan log pelatihan. Dengan memulai VisualDL, Anda dapat melihat hasil pelatihan kapan saja. Perintah startup visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyLog Output Pelatihan:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
Mulai VisualDL: visualdl --logdir=log --host 0.0.0.0 , halaman VisualDL adalah sebagai berikut:
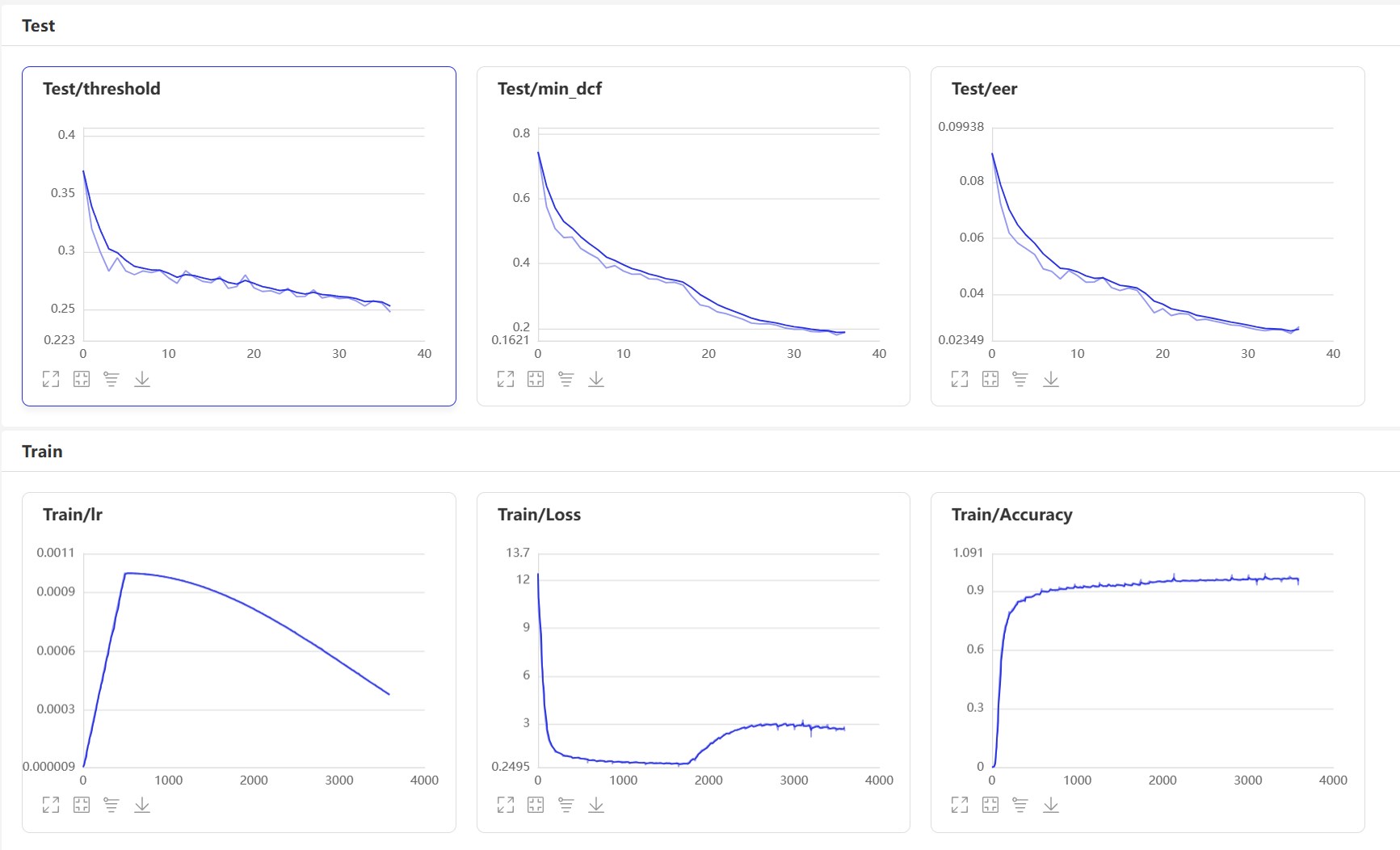
Setelah pelatihan, model prediksi akan disimpan. Kami menggunakan model prediksi untuk memprediksi fitur audio dalam set tes, dan kemudian menggunakan fitur audio untuk membandingkannya berpasangan untuk menghitung EER dan MindCF.
python eval.pyOutputnya mirip dengan yang berikut:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
Berikut adalah beberapa antarmuka yang umum digunakan. Untuk antarmuka lebih lanjut, silakan merujuk ke mvector/predict.py . Anda juga dapat melihat contoh声纹对比声纹识别.
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) Mari kita mulai menerapkan perbandingan voiceprint dan buat program infer_contrast.py . Pertama, kami memperkenalkan beberapa fungsi penting. Fungsi predict() dapat memperoleh fitur suaraan, fungsi predict_batch() dapat memperoleh batch fitur suaraan, fungsi contrast() dapat membandingkan kesamaan antara dua audio, fungsi register() recognition() ) mendaftarkan audio ke dalam pustaka remove_user() menghapusnya. Daftar di perpustakaan Voiceprint. Kami memasukkan dua pidato dan mendapatkan data fitur mereka melalui fungsi prediksi. Dengan menggunakan data fitur ini, kita dapat menemukan nilai cosinus diagonal mereka, dan hasilnya dapat digunakan sebagai kenalan mereka. Untuk threshold pengakuan ini, pembaca dapat memodifikasinya sesuai dengan persyaratan akurasi proyek mereka.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavOutputnya mirip dengan yang berikut:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
Pada saat yang sama, program perbandingan suara dengan antarmuka GUI juga disediakan. Jalankan infer_contrast_gui.py untuk memulai program. Antarmuka adalah sebagai berikut. Pilih dua audio masing -masing. Klik untuk mulai menilai untuk menentukan apakah mereka orang yang sama.
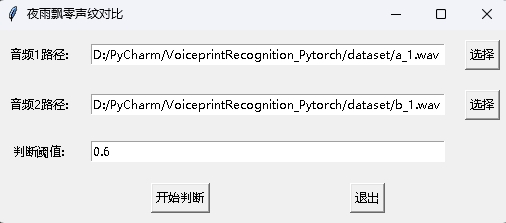
Dalam pengakuan berita, fungsi register() dan fungsi recognition() terutama digunakan. Pertama, gunakan fungsi register() untuk mendaftarkan audio ke pustaka voiceprint. Anda juga dapat secara langsung menambahkan file ke folder audio_db . Saat menggunakannya, Anda dapat memulai pengakuan melalui fungsi recognition() . Masukkan audio dan Anda dapat mengidentifikasi speaker yang diperlukan dari perpustakaan voiceprint.
Dengan fungsi pengenalan voiceprint di atas, pembaca dapat menyelesaikan pengakuan suara sesuai dengan kebutuhan proyek mereka sendiri. Misalnya, apa yang saya berikan di bawah ini adalah menyelesaikan pengakuan suarakan melalui perekaman. Pertama, suara di perpustakaan suara harus dimuat. Folder Perpustakaan Suara audio_db , dan kemudian pengguna akan merekam suara selama 3 detik setelah menekan mobil. Kemudian program akan secara otomatis merekam suara dan menggunakan audio yang direkam untuk pengakuan voiceprint untuk mencocokkan suara di perpustakaan suara dan mendapatkan informasi pengguna. Dengan cara ini, pembaca juga dapat memodifikasinya untuk menyelesaikan pengakuan voiceprint melalui permintaan layanan, misalnya, menyediakan API untuk dihubungi aplikasi. Ketika pengguna masuk melalui voiceprint pada aplikasi, ia mengirimkan suara yang direkam ke backend untuk menyelesaikan pengakuan suara, dan kemudian mengembalikan hasilnya ke aplikasi, asalkan pengguna telah terdaftar dengan sorotan suara dan berhasil menyimpan data suara di folder audio_db .
python infer_recognition.pyOutputnya mirip dengan yang berikut:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
Pada saat yang sama, program pengakuan voiceprint dengan antarmuka GUI juga disediakan. Jalankan infer_recognition_gui.py untuk memulai, klik注册音频到声纹库, pahami dan mulai berbicara, merekam selama 3 detik, dan kemudian masukkan nama pendaftar. Setelah itu, Anda dapat执行声纹识别, dan kemudian berbicara segera. Setelah merekam selama 3 detik, tunggu hasil pengakuan. Tombol删除用户dapat menghapus pengguna. Tombol实时识别dapat dikenali secara real time, dan dapat direkam dan dikenali secara real time.
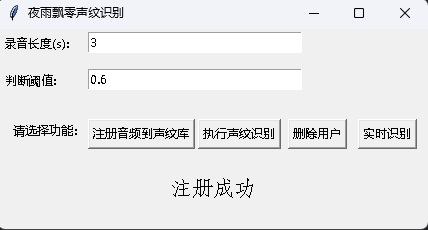
Jalankan program infer_speaker_diarization.py , masukkan jalur audio, dan Anda dapat memisahkan speaker dan menampilkan hasilnya. Disarankan bahwa panjang audio tidak boleh kurang dari 10 detik. Untuk fungsi lebih lanjut, Anda dapat melihat parameter program.
python infer_speaker_diarization.py --audio_path=dataset/test_long.wavOutputnya mirip dengan yang berikut:
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
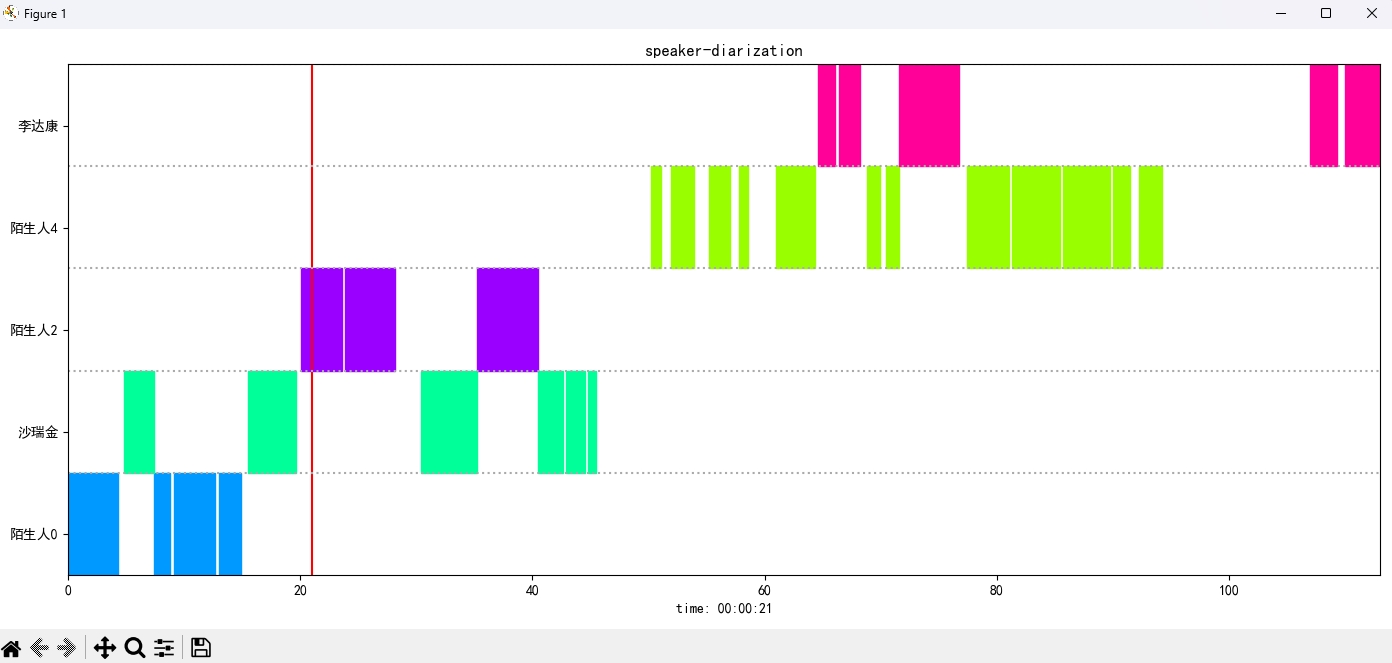
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
Gambar hasil ditampilkan sebagai berikut. Anda dapat mengontrol pemutaran audio melalui bilah空格. Klik posisi untuk melompat ke posisi yang ditentukan:
Proyek ini juga menyediakan program dengan antarmuka GUI, mengeksekusi program infer_speaker_diarization_gui.py . Untuk fungsi lebih lanjut, Anda dapat melihat parameter program.
python infer_speaker_diarization_gui.pyAnda dapat membuka halaman seperti itu untuk mengidentifikasi speaker:
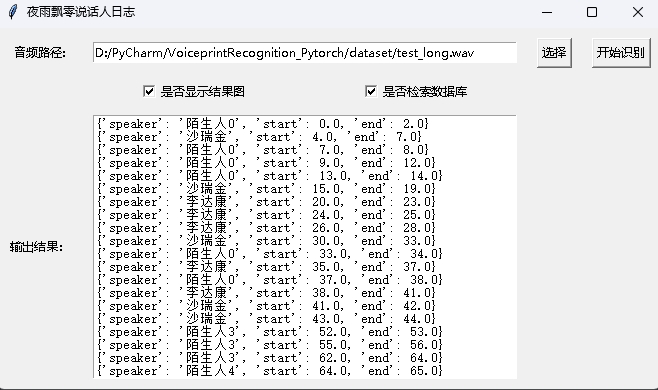
Catatan: Jika nama speaker dalam bahasa Cina, Anda perlu mengatur font instalasi untuk menampilkannya secara normal. Secara umum, Windows tidak perlu diinstal, tetapi Ubuntu perlu diinstal. Jika Windows memang hilang font, Anda hanya perlu mengunduh file format .ttf di sini dan menyalinnya ke C:WindowsFonts . Operasi sistem Ubuntu adalah sebagai berikut.
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )Hadiah satu dolar untuk mendukung penulis


