VoiceprintRecognition Pytorch
1.0.0
Chinês simplificado | Inglês
Esta filial é a versão 1.1. Se você deseja usar a versão anterior 1.0, use -a na ramificação 1.0. Este projeto usa vários modelos avançados de reconhecimento de impressão de voz, como Ecapatdnn, Resnetse, ERES2NET e CAM ++. Não é descartado que mais modelos serão apoiados no futuro. Ao mesmo tempo, este projeto também suporta vários métodos de pré -processamento de dados, como Melspectrograma, Spectrogram, MFCC e FBANK. Perda de arcface, perda de arcface: perda de margem angular aditiva (função de perda de intervalo de ângulo aditivo), correspondendo ao Aamloss no projeto, normaliza os autovetores e os pesos e adiciona o intervalo de ângulo M a θ. O intervalo do ângulo tem um impacto mais direto no ângulo do que o intervalo cosseno. Além disso, também suporta várias funções de perda, como Amloss, Armloss e Celoss.
Se este projeto for útil para você, dê as boas -vindas a Star para evitar que não seja encontrado mais tarde.
Todos são bem -vindos para digitalizar o código para inserir o planeta do conhecimento ou o grupo QQ para discutir. O Planeta de Conhecimento fornece arquivos de modelo de projeto e outros arquivos de modelos de projetos relacionados dos blogueiros, bem como outros recursos.
Ambiente de uso:
Papel modelo:
| Modelo | Params (m) | Conjunto de dados | Alto -falantes de trem | limite | Eer | MINDCF | Download do modelo |
|---|---|---|---|---|---|---|---|
| ERES2NETV2 | 6.6 | CN-CELEB | 2796 | 0.20089 | 0.08071 | 0,45705 | Junte -se ao planeta do conhecimento para obter |
| ERES2NET | 6.6 | CN-CELEB | 2796 | 0.20014 | 0,08132 | 0,45544 | Junte -se ao planeta do conhecimento para obter |
| CAM ++ | 6.8 | CN-CELEB | 2796 | 0,23323 | 0,08332 | 0,48536 | Junte -se ao planeta do conhecimento para obter |
| Resnetse | 7.8 | CN-CELEB | 2796 | 0.19066 | 0.08544 | 0,49142 | Junte -se ao planeta do conhecimento para obter |
| Ecapatdnn | 6.1 | CN-CELEB | 2796 | 0,23646 | 0,09259 | 0,51378 | Junte -se ao planeta do conhecimento para obter |
| Tdnn | 2.6 | CN-CELEB | 2796 | 0,23858 | 0.10825 | 0,59545 | Junte -se ao planeta do conhecimento para obter |
| Res2net | 5.0 | CN-CELEB | 2796 | 0.19526 | 0,12436 | 0,65347 | Junte -se ao planeta do conhecimento para obter |
| CAM ++ | 6.8 | Conjunto de dados maior | 2W+ | 0,33 | 0,07874 | 0,52524 | Junte -se ao planeta do conhecimento para obter |
| ERES2NET | 55.1 | Outros conjuntos de dados | 20w+ | 0,36 | 0,02936 | 0,18355 | Junte -se ao planeta do conhecimento para obter |
| ERES2NETV2 | 56.2 | Outros conjuntos de dados | 20w+ | 0,36 | 0,03847 | 0.24301 | Junte -se ao planeta do conhecimento para obter |
| CAM ++ | 6.8 | Outros conjuntos de dados | 20w+ | 0,29 | 0,04765 | 0,31436 | Junte -se ao planeta do conhecimento para obter |
ilustrar:
speed_perturb_3_class: True .Fbank e a função de perda é AAMLoss .| Modelo | Params (m) | Conjunto de dados | Alto -falantes de trem | limite | Eer | MINDCF | Download do modelo |
|---|---|---|---|---|---|---|---|
| CAM ++ | 6.8 | Voxceleb1 e 2 | 7205 | 0,22504 | 0,02436 | 0,15543 | Junte -se ao planeta do conhecimento para obter |
| Ecapatdnn | 6.1 | Voxceleb1 e 2 | 7205 | 0,24877 | 0,02480 | 0.16188 | Junte -se ao planeta do conhecimento para obter |
| ERES2NETV2 | 6.6 | Voxceleb1 e 2 | 7205 | 0.20710 | 0,02742 | 0,17709 | Junte -se ao planeta do conhecimento para obter |
| ERES2NET | 6.6 | Voxceleb1 e 2 | 7205 | 0,20233 | 0,02954 | 0,17377 | Junte -se ao planeta do conhecimento para obter |
| Resnetse | 7.8 | Voxceleb1 e 2 | 7205 | 0,22567 | 0,03189 | 0.23040 | Junte -se ao planeta do conhecimento para obter |
| Tdnn | 2.6 | Voxceleb1 e 2 | 7205 | 0,23834 | 0,03486 | 0,26792 | Junte -se ao planeta do conhecimento para obter |
| Res2net | 5.0 | Voxceleb1 e 2 | 7205 | 0.19472 | 0,04370 | 0,40072 | Junte -se ao planeta do conhecimento para obter |
| CAM ++ | 6.8 | Conjunto de dados maior | 2W+ | 0,28 | 0,03182 | 0,23731 | Junte -se ao planeta do conhecimento para obter |
| ERES2NET | 55.1 | Outros conjuntos de dados | 20w+ | 0,53 | 0.08904 | 0,62130 | Junte -se ao planeta do conhecimento para obter |
| ERES2NETV2 | 56.2 | Outros conjuntos de dados | 20w+ | 0,52 | 0,08649 | 0,64193 | Junte -se ao planeta do conhecimento para obter |
| CAM ++ | 6.8 | Outros conjuntos de dados | 20w+ | 0,49 | 0.10334 | 0,71200 | Junte -se ao planeta do conhecimento para obter |
ilustrar:
speed_perturb_3_class: True .Fbank e a função de perda é AAMLoss .| Método de pré -processamento | Conjunto de dados | Alto -falantes de trem | limite | Eer | MINDCF | Download do modelo |
|---|---|---|---|---|---|---|
| Fbank | CN-CELEB | 2796 | 0,14574 | 0.10988 | 0,58955 | Junte -se ao planeta do conhecimento para obter |
| MFCC | CN-CELEB | 2796 | 0,14868 | 0.11483 | 0,61275 | Junte -se ao planeta do conhecimento para obter |
| Espectrograma | CN-CELEB | 2796 | 0,14962 | 0,11613 | 0.60057 | Junte -se ao planeta do conhecimento para obter |
| Melspectrograma | CN-CELEB | 2796 | 0,13458 | 0,12498 | 0.60741 | Junte -se ao planeta do conhecimento para obter |
| wavlm-Base-plus | CN-CELEB | 2796 | 0,14166 | 0,13247 | 0,62451 | Junte -se ao planeta do conhecimento para obter |
| W2V-Bert-2.0 | CN-CELEB | 2796 | Junte -se ao planeta do conhecimento para obter | |||
| WAV2VEC2-LARGE-XLSR-53 | CN-CELEB | 2796 | Junte -se ao planeta do conhecimento para obter | |||
| wavlm-grande | CN-CELEB | 2796 | Junte -se ao planeta do conhecimento para obter |
ilustrar:
CAM++ e a função de perda é AAMLoss .extract_features.py para extrair recursos com antecedência, o que significa que o aprimoramento de dados para o áudio não é usado durante o treinamento.w2v-bert-2.0 , wav2vec2-large-xlsr-53 são obtidos a partir do pré-treinamento de dados multilíngues. Os dados de pré-treinamento de wavlm-base-plus e wavlm-large são apenas em inglês.| Função de perda | Conjunto de dados | Alto -falantes de trem | limite | Eer | MINDCF | Download do modelo |
|---|---|---|---|---|---|---|
| Aamloss | CN-CELEB | 2796 | 0,14574 | 0.10988 | 0,58955 | Junte -se ao planeta do conhecimento para obter |
| Sphereface2 | CN-CELEB | 2796 | 0.20377 | 0.11309 | 0,61536 | Junte -se ao planeta do conhecimento para obter |
| Triplangularmarginloss | CN-CELEB | 2796 | 0,28940 | 0.11749 | 0,63735 | Junte -se ao planeta do conhecimento para obter |
| Subcenterloss | CN-CELEB | 2796 | 0,13126 | 0.11775 | 0,56995 | Junte -se ao planeta do conhecimento para obter |
| Armlloss | CN-CELEB | 2796 | 0,14563 | 0.11805 | 0,57171 | Junte -se ao planeta do conhecimento para obter |
| Amloss | CN-CELEB | 2796 | 0,12870 | 0.12301 | 0,63263 | Junte -se ao planeta do conhecimento para obter |
| Celoss | CN-CELEB | 2796 | 0.13607 | 0,12684 | 0,65176 | Junte -se ao planeta do conhecimento para obter |
ilustrar:
CAM++ e o método de pré-processamento é Fbank .extract_features.py para extrair recursos com antecedência, o que significa que o aprimoramento de dados para o áudio não é usado durante o treinamento. conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaUse PIP para instalar, o comando é o seguinte:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleRecomenda -se instalar o código -fonte , que pode garantir o uso do código mais recente.
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . O autor usa o CN-CELEB neste tutorial. Esse conjunto de dados possui um total de cerca de 3.000 dados de voz e dados de voz de 65W+. Após o download, você precisa descomprimir o conjunto de dados para o diretório dataset . Além disso, se você deseja avaliar, também precisa baixar o conjunto de testes CN-CELEB. Se o leitor tiver outros melhores conjuntos de dados, ele poderá ser misturado, mas é melhor usar o módulo de ferramentas do Python Aukit para processar áudio, redução de ruído e mudo.
O primeiro é criar uma lista de dados. O formato da lista de dados é <语音文件路径t语音分类标签> . Criar esta lista é principalmente para a conveniência da leitura posterior e a conveniência da leitura usando outros conjuntos de dados de voz. Tags de classificação de voz referem -se ao ID exclusivo do falante. Diferentes conjuntos de dados de voz podem ser gravados na mesma lista de dados escrevendo funções correspondentes para gerar listas de dados.
Execute o programa create_data.py para concluir a preparação de dados.
python create_data.pyApós executar o programa acima, o seguinte formato de dados será gerado. Se você deseja personalizar os dados, consulte a seguinte lista de dados. A frente é o caminho relativo do áudio e a parte traseira é o rótulo do alto -falante correspondente ao áudio, que é o mesmo que a classificação. Observe que o ID da lista de dados de teste não precisa ser o mesmo que o ID de treinamento, o que significa que o falante dos dados do teste pode não precisar aparecer no conjunto de treinamento, desde que a mesma pessoa na lista de dados de teste seja garantida que a mesma pessoa tenha o mesmo ID.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
O método de pré -processamento padrão do FBANK é usado no arquivo de configuração. Se você deseja usar outros métodos de pré -processamento, poderá modificar o método de instalação no arquivo de configuração. O valor específico pode ser modificado de acordo com sua própria situação. Se você não tiver certeza de como definir parâmetros, poderá excluir diretamente esta peça e usar o valor padrão diretamente.
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80Durante o processo de treinamento, a primeira coisa é ler os dados de áudio, extrair os recursos e finalmente realizar treinamento. Entre eles, a leitura de dados de áudio e a extração de recursos também consome tempo, para que possamos optar por extrair recursos com antecedência. Se treinarmos o modelo, podemos carregar e extrair diretamente os recursos, para que a velocidade de treinamento seja mais rápida. Esse recurso extraído é opcional. Se nenhum bom recurso for extraído, o modelo de treinamento começará lendo os dados de áudio e extraindo os recursos. As etapas para extrair recursos são as seguintes:
extract_features.py para extrair recursos. Os recursos serão salvos no diretório dataset/features e gerarão uma nova lista de dados train_list_features.txt , enroll_list_features.txt e trials_list_features.txt . python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list , dataset_conf.enroll_list e dataset_conf.trials_list para train_list_features.txt , enroll_list_features.txt e trials_list_features.txt . Usando train.py para treinar o modelo, este projeto suporta vários métodos de pré -processamento de áudio. Os parâmetros preprocess_conf.feature_method do arquivo de configuração configs/ecapa_tdnn.yml podem ser especificados. MelSpectrogram é o espectro MEL, Spectrogram é o gráfico do espectro, o coeficiente de espectro MFCC MEL Spectrum, etc. O método de aprimoramento de dados pode ser especificado pelo parâmetro augment_conf_path . Durante o processo de treinamento, o VisualDL será usado para salvar o registro de treinamento. Ao iniciar o VisualDL, você pode visualizar os resultados do treinamento a qualquer momento. O comando de inicialização visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyLog de saída de treinamento:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
Iniciar VisualDL: visualdl --logdir=log --host 0.0.0.0 , a página do VisualDL é a seguinte:
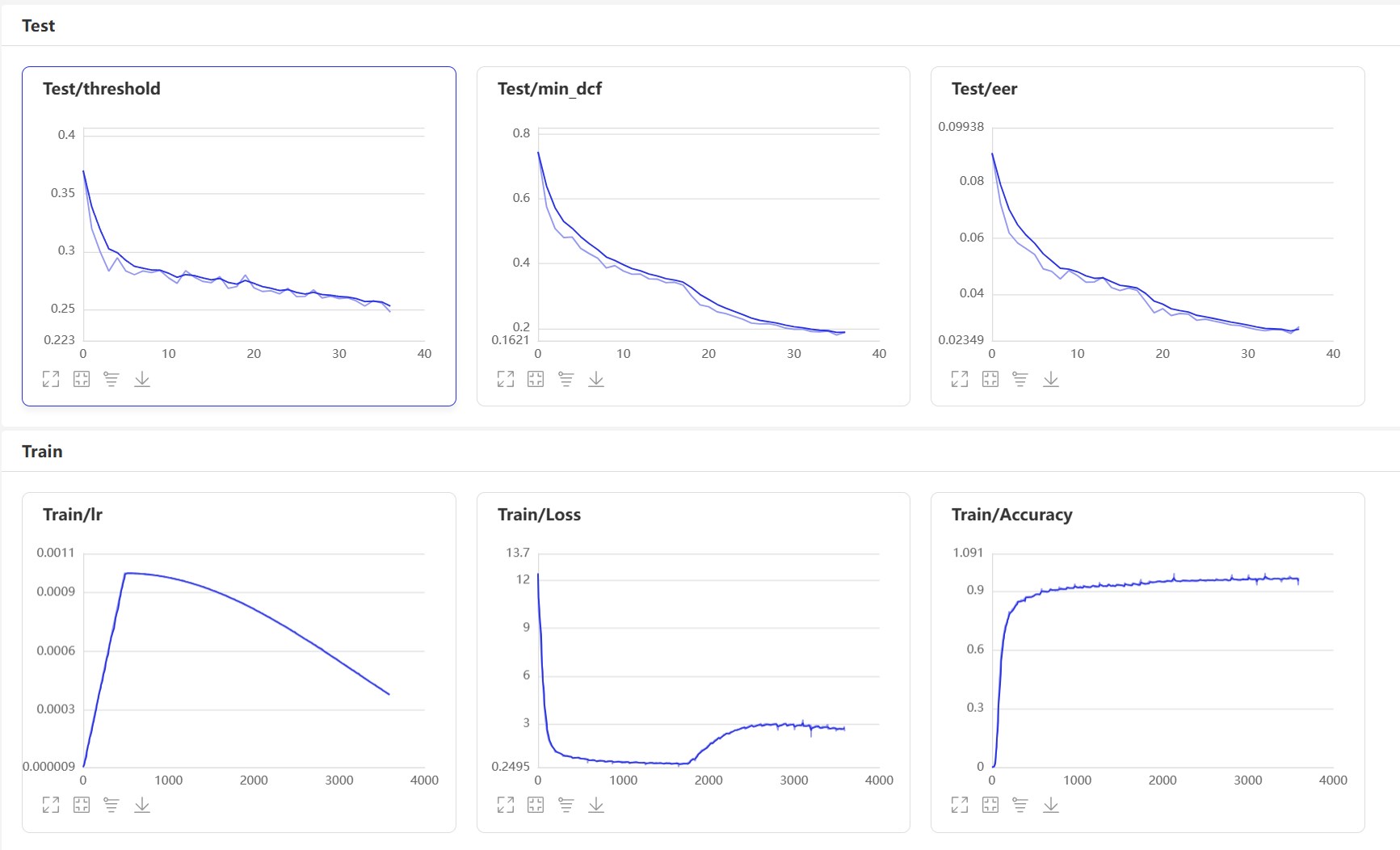
Após o treinamento, o modelo de previsão será salvo. Usamos o modelo de previsão para prever os recursos de áudio no conjunto de testes e, em seguida, usamos os recursos de áudio para compará -los em pares para calcular o EER e o MindCF.
python eval.pyA saída é semelhante ao seguinte:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
Aqui estão várias interfaces comumente usadas. Para mais interfaces, consulte o mvector/predict.py . Você também pode analisar os exemplos de声纹对比声纹识别.
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) Vamos começar a implementar a comparação do VoicePrint e criar um programa infer_contrast.py . Primeiro, introduzimos várias funções importantes. predict() pode obter recursos de impressão de voz, predict_batch() pode obter um lote de recursos de impressão de voz, contrast() pode comparar a semelhança entre dois áudios, register() registra um áudio na biblioteca VoicePrint, insere um áudio da função recognition() remove_user() a compara e a reconhece da função da voz. Registre -se na biblioteca de impressão de voz. Passamos dois discursos e obtemos seus dados de recursos através da função de previsão. Usando esses dados do recurso, podemos encontrar o valor do cosseno diagonal e o resultado pode ser usado como seu conhecido. Para esse threshold de reconhecimento, os leitores podem modificá -lo de acordo com os requisitos de precisão de seus projetos.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavA saída é semelhante ao seguinte:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
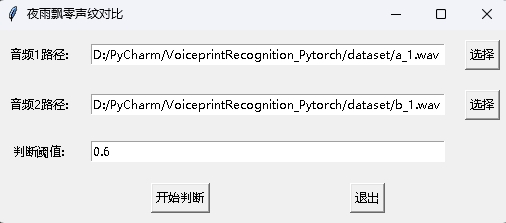
Ao mesmo tempo, também é fornecido um programa de comparação de impressão de voz com uma interface da GUI. Execute infer_contrast_gui.py para iniciar o programa. A interface é a seguinte. Selecione dois áudios, respectivamente. Clique para começar a julgar para determinar se eles são a mesma pessoa.
No reconhecimento de notícias, a função register() e recognition() são usadas principalmente. Primeiro, use register() para registrar o áudio na biblioteca VoicePrint. Você também pode adicionar diretamente o arquivo à pasta audio_db . Ao usá -lo, você pode iniciar o reconhecimento através da função recognition() . Digite um áudio e você pode identificar o alto -falante necessário na biblioteca de impressão de voz.
Com a função de reconhecimento de impressão de voz acima, os leitores podem concluir o reconhecimento de impressão de voz de acordo com suas próprias necessidades do projeto. Por exemplo, o que eu forneço abaixo é concluir o reconhecimento de impressão de voz através da gravação. Primeiro, a voz na biblioteca de voz deve ser carregada. A pasta da biblioteca de voz é audio_db e, em seguida, o usuário gravará o som por 3 segundos depois de pressionar o carro. Em seguida, o programa gravará automaticamente o som e usará o áudio gravado para reconhecimento de impressão de voz para corresponder à voz na biblioteca de voz e obter informações do usuário. Dessa forma, os leitores também podem modificá -lo para concluir o reconhecimento de impressão de voz por meio de solicitações de serviço, por exemplo, fornecer uma API para o aplicativo ligar. Quando o usuário faz login através do VoicePrint no aplicativo, ele envia a voz gravada para o back -end para concluir o reconhecimento de impressão de voz e, em seguida, retorna o resultado ao aplicativo, desde que o usuário tenha registrado o VoicePrint e armazena com sucesso os dados de voz na pasta audio_db .
python infer_recognition.pyA saída é semelhante ao seguinte:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
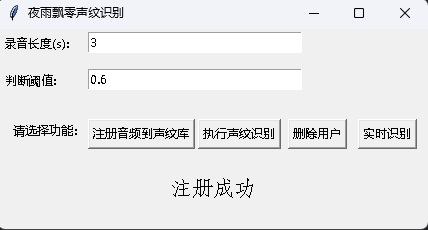
Ao mesmo tempo, também é fornecido um programa de reconhecimento de impressão de voz com uma interface da GUI. Execute infer_recognition_gui.py para iniciar, clique注册音频到声纹库, entender e começar a falar, gravar por 3 segundos e digite o nome do registrante. Depois disso, você pode执行声纹识别e depois falar imediatamente. Depois de gravar por 3 segundos, aguarde o resultado do reconhecimento. O botão删除用户pode excluir o usuário. O botão实时识别pode ser reconhecido em tempo real e pode ser gravado e reconhecido em tempo real.
Execute o programa infer_speaker_diarization.py , digite o caminho do áudio e você pode separar o alto -falante e exibir os resultados. Recomenda -se que o comprimento do áudio não seja inferior a 10 segundos. Para mais funções, você pode visualizar os parâmetros do programa.
python infer_speaker_diarization.py --audio_path=dataset/test_long.wavA saída é semelhante ao seguinte:
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
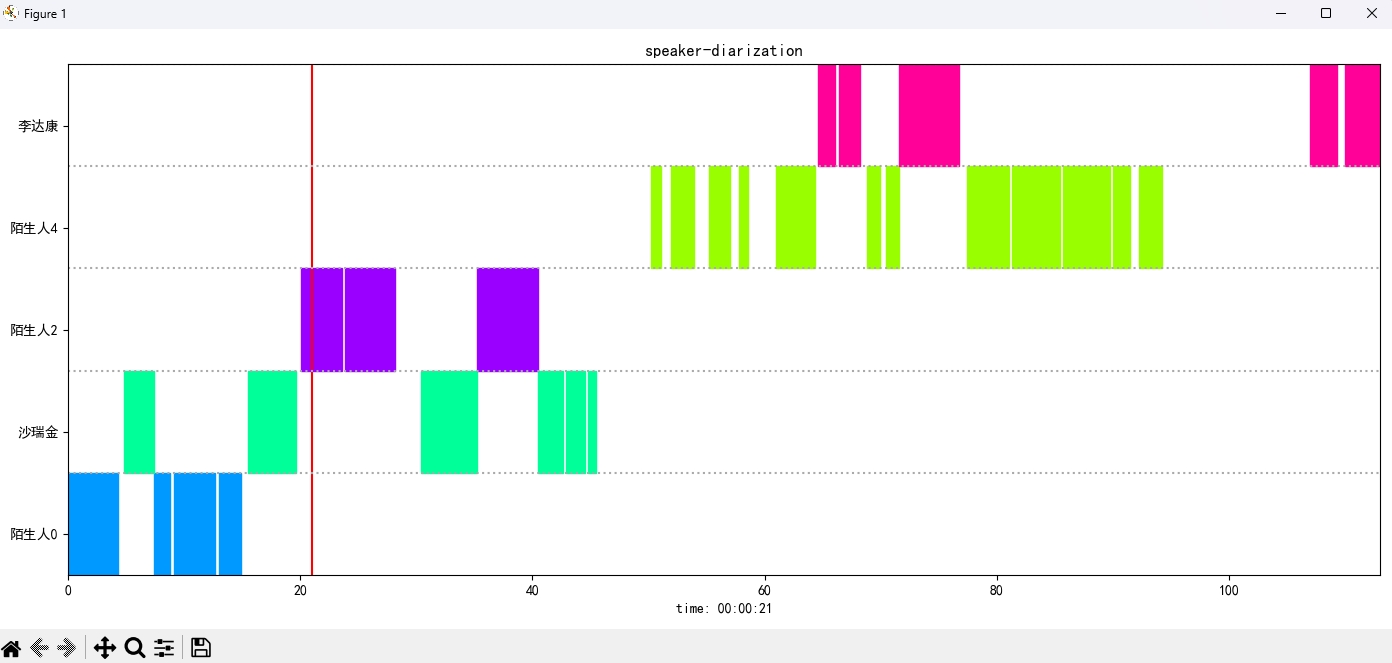
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
A imagem de resultado é exibida da seguinte forma. Você pode controlar a reprodução do áudio através空格. Clique na posição para pular para a posição especificada:
O projeto também fornece a um programa a interface da GUI, executando o programa infer_speaker_diarization_gui.py . Para mais funções, você pode visualizar os parâmetros do programa.
python infer_speaker_diarization_gui.pyVocê pode abrir essa página para identificar o orador:
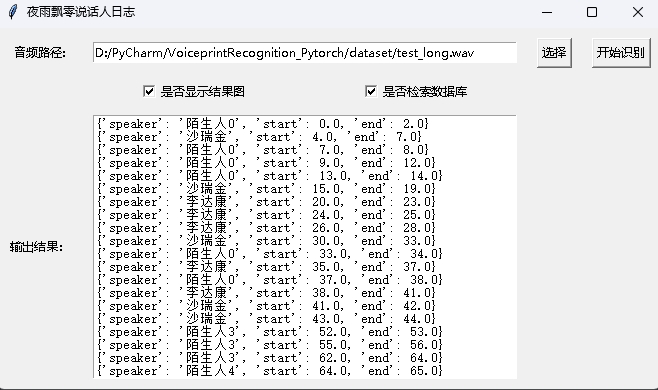
Nota: Se o nome do alto -falante estiver em chinês, você precisará definir a fonte de instalação para exibi -la normalmente. De um modo geral, o Windows não precisa ser instalado, mas o Ubuntu precisa ser instalado. Se o Windows estiver realmente ausente fontes, você só precisará baixar o arquivo de formato .ttf aqui e copiá -lo para C:WindowsFonts . A operação do sistema Ubuntu é a seguinte.
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )Recompensar um dólar para apoiar o autor


