VoiceprintRecognition Pytorch
1.0.0
Vereinfachtes Chinesisch | Englisch
Diese Filiale ist Version 1.1. Wenn Sie die vorherige Version 1.0 verwenden möchten, verwenden Sie sie bitte in der Filiale 1.0. Dieses Projekt verwendet verschiedene erweiterte Voiceprint -Erkennungsmodelle wie Ecapatdnn, ResNetse, ERES2NET und CAM ++. Es wird nicht ausgeschlossen, dass in Zukunft mehr Modelle unterstützt werden. Gleichzeitig unterstützt dieses Projekt auch verschiedene Datenvorverarbeitungsmethoden wie Melspectrogramm, Spektrogramm, MFCC und FBANK. Arcface -Verlust, Arcface -Verlust: Additive Winkelrandverlust (additive Winkelintervallverlustfunktion), entsprechend dem AAMLoss im Projekt, normalisiert die Eigenvektoren und Gewichte und fügt das Winkelintervall m zu θ hinzu. Das Winkelintervall hat einen direkteren Einfluss auf den Winkel als das Cosinus -Intervall. Darüber hinaus unterstützt es verschiedene Verlustfunktionen wie Amloss, Armloss und Celoss.
Wenn dieses Projekt für Sie hilfreich ist, willkommen, um zu vermeiden, dass es später nicht gefunden wird.
Jeder ist herzlich eingeladen, den Code zu scannen, um den Knowledge Planet oder die QQ -Gruppe einzugeben, um zu diskutieren. Knowledge Planet bietet Projektmodelldateien und andere verwandte Projektdateien von Bloggern sowie andere Ressourcen.
Nutzungsumgebung:
Modellpapier:
| Modell | Parameter (m) | Datensatz | Zugredner | Schwelle | Eer | Mindcf | Modell Download |
|---|---|---|---|---|---|---|---|
| ERES2NETV2 | 6.6 | CN-Celeb | 2796 | 0,20089 | 0,08071 | 0,45705 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| ERES2NET | 6.6 | CN-Celeb | 2796 | 0,20014 | 0,08132 | 0,45544 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Cam ++ | 6.8 | CN-Celeb | 2796 | 0,23323 | 0,08332 | 0,48536 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Resnetse | 7.8 | CN-Celeb | 2796 | 0,19066 | 0,08544 | 0,49142 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Ecapatdnn | 6.1 | CN-Celeb | 2796 | 0,23646 | 0,09259 | 0,51378 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Tdnn | 2.6 | CN-Celeb | 2796 | 0,23858 | 0,10825 | 0,59545 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Res2net | 5.0 | CN-Celeb | 2796 | 0,19526 | 0,12436 | 0,65347 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Cam ++ | 6.8 | Größerer Datensatz | 2W+ | 0,33 | 0,07874 | 0,52524 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| ERES2NET | 55.1 | Andere Datensätze | 20W+ | 0,36 | 0,02936 | 0,18355 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| ERES2NETV2 | 56,2 | Andere Datensätze | 20W+ | 0,36 | 0,03847 | 0,24301 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Cam ++ | 6.8 | Andere Datensätze | 20W+ | 0,29 | 0,04765 | 0,31436 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
veranschaulichen:
speed_perturb_3_class: True .Fbank und die Verlustfunktion ist AAMLoss .| Modell | Parameter (m) | Datensatz | Zugredner | Schwelle | Eer | Mindcf | Modell Download |
|---|---|---|---|---|---|---|---|
| Cam ++ | 6.8 | Voxceleb1 & 2 | 7205 | 0,22504 | 0,02436 | 0,15543 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Ecapatdnn | 6.1 | Voxceleb1 & 2 | 7205 | 0,24877 | 0,02480 | 0,16188 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| ERES2NETV2 | 6.6 | Voxceleb1 & 2 | 7205 | 0,20710 | 0,02742 | 0,17709 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| ERES2NET | 6.6 | Voxceleb1 & 2 | 7205 | 0,20233 | 0,02954 | 0,17377 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Resnetse | 7.8 | Voxceleb1 & 2 | 7205 | 0,22567 | 0,03189 | 0,23040 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Tdnn | 2.6 | Voxceleb1 & 2 | 7205 | 0,23834 | 0,03486 | 0,26792 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Res2net | 5.0 | Voxceleb1 & 2 | 7205 | 0,19472 | 0,04370 | 0,40072 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Cam ++ | 6.8 | Größerer Datensatz | 2W+ | 0,28 | 0,03182 | 0,23731 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| ERES2NET | 55.1 | Andere Datensätze | 20W+ | 0,53 | 0,08904 | 0,62130 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| ERES2NETV2 | 56,2 | Andere Datensätze | 20W+ | 0,52 | 0,08649 | 0,64193 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Cam ++ | 6.8 | Andere Datensätze | 20W+ | 0,49 | 0,10334 | 0,71200 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
veranschaulichen:
speed_perturb_3_class: True .Fbank und die Verlustfunktion ist AAMLoss .| Vorverarbeitungsmethode | Datensatz | Zugredner | Schwelle | Eer | Mindcf | Modell Download |
|---|---|---|---|---|---|---|
| FBANK | CN-Celeb | 2796 | 0,14574 | 0,10988 | 0,58955 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| MFCC | CN-Celeb | 2796 | 0,14868 | 0,11483 | 0,61275 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Spektrogramm | CN-Celeb | 2796 | 0,14962 | 0,11613 | 0,60057 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Melspektrogramm | CN-Celeb | 2796 | 0,13458 | 0,12498 | 0,60741 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Wavlm-Base-Plus | CN-Celeb | 2796 | 0,14166 | 0,13247 | 0,62451 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| W2V-Bert-2.0 | CN-Celeb | 2796 | Schließen Sie sich dem Wissensplanet an, um zu erhalten | |||
| WAV2VEC2-Large-XLSR-53 | CN-Celeb | 2796 | Schließen Sie sich dem Wissensplanet an, um zu erhalten | |||
| Wavlm-Large | CN-Celeb | 2796 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
veranschaulichen:
CAM++ und die Verlustfunktion ist AAMLoss .extract_features.py , um Features im Voraus zu extrahieren, was bedeutet, dass die Datenverbesserung des Audio während des Trainings nicht verwendet wird.w2v-bert-2.0 , wav2vec2-large-xlsr-53 werden aus mehrsprachigen Daten vor dem Training erhalten. Die Voraussetzungsdaten von wavlm-base-plus und wavlm-large sind nur in Englisch.| Verlustfunktion | Datensatz | Zugredner | Schwelle | Eer | Mindcf | Modell Download |
|---|---|---|---|---|---|---|
| Aamloss | CN-Celeb | 2796 | 0,14574 | 0,10988 | 0,58955 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Sphereface2 | CN-Celeb | 2796 | 0,20377 | 0.11309 | 0,61536 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Tripletangularmarginloss | CN-Celeb | 2796 | 0,28940 | 0,11749 | 0,63735 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| SubCenterloss | CN-Celeb | 2796 | 0,13126 | 0,11775 | 0,56995 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Armlloss | CN-Celeb | 2796 | 0,14563 | 0,11805 | 0,57171 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Amloses | CN-Celeb | 2796 | 0,12870 | 0,12301 | 0,63263 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Celoss | CN-Celeb | 2796 | 0,13607 | 0,12684 | 0,65176 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
veranschaulichen:
CAM++ und die Vorverarbeitungsmethode ist Fbank .extract_features.py , um Features im Voraus zu extrahieren, was bedeutet, dass die Datenverbesserung des Audio während des Trainings nicht verwendet wird. conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaVerwenden Sie Pip, um zu installieren, der Befehl lautet wie folgt:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleEs wird empfohlen, den Quellcode zu installieren , der die Verwendung des neuesten Codes sicherstellen kann.
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . Der Autor verwendet CN-Celeb in diesem Tutorial. Dieser Datensatz enthält insgesamt etwa 3.000 Sprachdaten und 65W+ Sprachdaten. Nach dem Herunterladen müssen Sie den Datensatz in das dataset dekomprimieren. Wenn Sie bewerten möchten, müssen Sie außerdem den CN-Celeb-Testsatz herunterladen. Wenn der Leser andere bessere Datensätze hat, kann er zusammen gemischt werden, aber es ist am besten, Pythons Tool -Modul Aukit zu verwenden, um Audio, Rauschreduzierung und Stummschaltung zu verarbeiten.
Das erste besteht darin, eine Datenliste zu erstellen. Das Format der Datenliste ist <语音文件路径t语音分类标签> . Das Erstellen dieser Liste dient hauptsächlich zum Komfort des späteren Lesens und zum Lesen des Lesens mit anderen Sprachdatensätzen. Sprachklassifizierungs -Tags beziehen sich auf die eindeutige ID des Sprechers. Verschiedene Sprachdatensätze können in dieselbe Datenliste geschrieben werden, indem entsprechende Funktionen zum Generieren von Datenlisten geschrieben werden.
Führen Sie das Programm create_data.py aus, um die Datenvorbereitung abzuschließen.
python create_data.pyNach der Ausführung des obigen Programms wird das folgende Datenformat generiert. Wenn Sie die Daten anpassen möchten, lesen Sie die folgende Datenliste. Die Front ist der relative Weg des Audios, und die Rückseite ist das Etikett des Lautsprechers, der dem Audio entspricht, der der Klassifizierung entspricht. Beachten Sie, dass die ID der Testdatenliste nicht mit der Trainings -ID übereinstimmen muss, was bedeutet, dass der Sprecher der Testdaten möglicherweise nicht im Trainingssatz angezeigt wird, solange dieselbe Person in der Testdatenliste sichergestellt ist, dass dieselbe Person dieselbe ID hat.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
Die Standard -FBANK -Vorverarbeitungsmethode wird in der Konfigurationsdatei verwendet. Wenn Sie andere Vorverarbeitungsmethoden verwenden möchten, können Sie die Installationsmethode in der Konfigurationsdatei ändern. Der spezifische Wert kann nach Ihrer eigenen Situation geändert werden. Wenn Sie sich nicht sicher sind, wie Sie Parameter festlegen, können Sie diesen Teil direkt löschen und den Standardwert direkt verwenden.
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80Während des Schulungsprozesses ist das erste, was die Audiodaten lesen, dann die Merkmale extrahiert und schließlich Schulungen durchführen kann. Unter ihnen ist das Lesen von Audiodaten und das Extrahieren von Funktionen ebenfalls zeitaufwändig, sodass wir im Voraus Features extrahieren können. Wenn wir das Modell trainieren, können wir die Funktionen direkt laden und extrahieren, damit die Trainingsgeschwindigkeit schneller ist. Diese extrahierte Funktion ist optional. Wenn keine guten Funktionen extrahiert werden, beginnt das Trainingsmodell mit dem Lesen der Audiodaten und dann mit dem Extrahieren der Merkmale. Die Schritte zum Extrahieren von Merkmalen sind wie folgt:
extract_features.py aus, um Merkmale zu extrahieren. Die Funktionen werden im Verzeichnis dataset/features gespeichert und generieren eine neue Datenliste train_list_features.txt , enroll_list_features.txt und trials_list_features.txt . python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list , dataset_conf.enroll_list und dataset_conf.trials_list an train_list_features.txt , enroll_list_features.txt und trials_list_features.txt . Dieses Projekt verwendet mit train.py , um das Modell zu trainieren, mehrere Audiovorverarbeitungsmethoden. Die Parameter preprocess_conf.feature_method configs/ecapa_tdnn.yml können angegeben werden. MelSpectrogram ist das MEL -Spektrum, Spectrogram ist der Spektrumgraf, MFCC MEL -Spektrum cepSpectral -Koeffizient usw. Die Datenverbesserungsmethode kann durch den Parameter augment_conf_path angegeben werden. Während des Trainingsprozesses wird VisualDL verwendet, um das Trainingsprotokoll zu speichern. Wenn Sie VisualDL starten, können Sie die Trainingsergebnisse jederzeit anzeigen. Der Startbefehl visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyTrainingsausgabeprotokoll:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
Starten Sie VisualDL: visualdl --logdir=log --host 0.0.0.0 , die visualdl -Seite ist wie folgt:
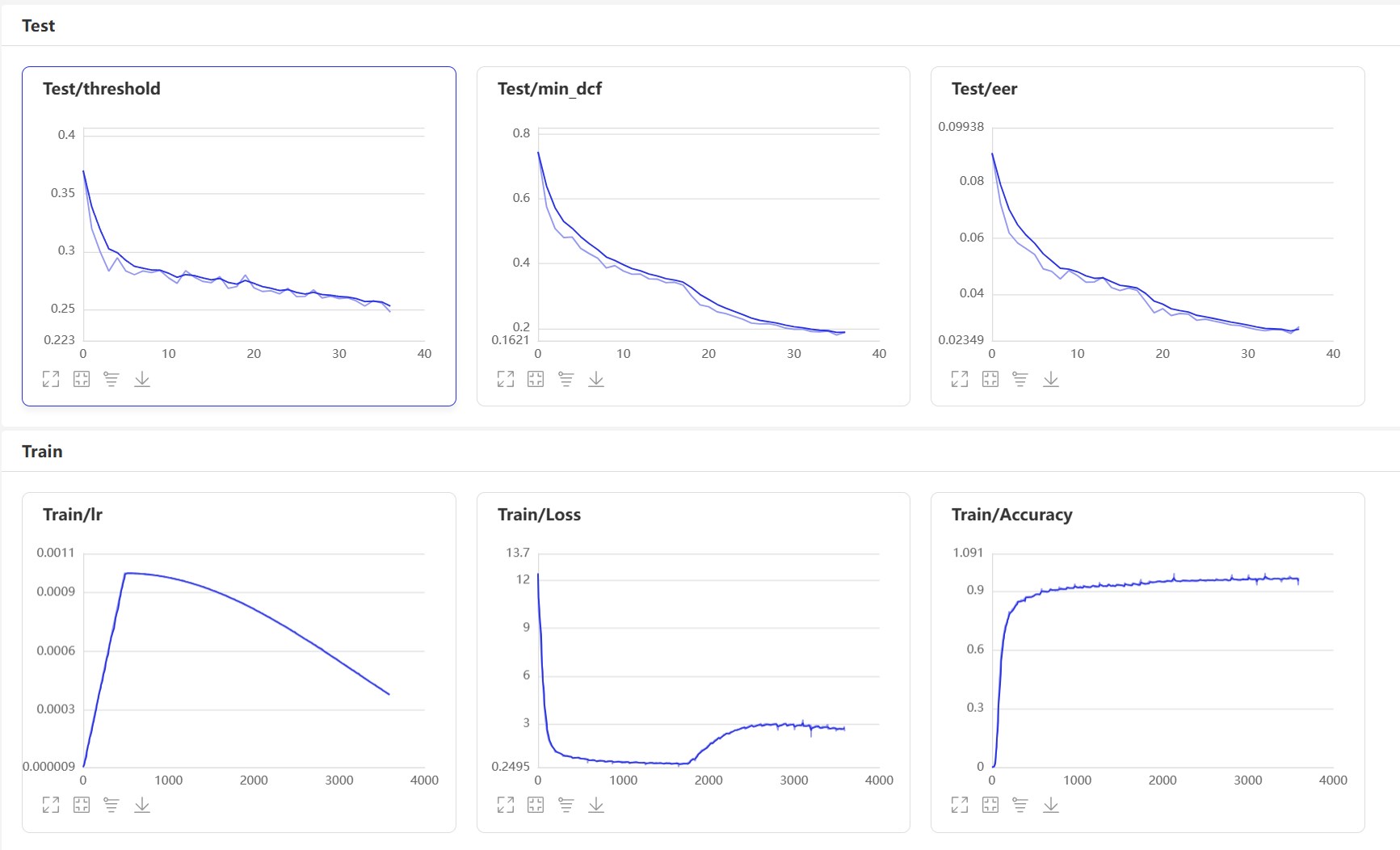
Nach dem Training wird das Vorhersagemodell gespeichert. Wir verwenden das Vorhersagemodell, um die Audiofunktionen im Testsatz vorherzusagen und dann die Audiofunktionen zu vergleichen, um EER und MINDCF zu berechnen.
python eval.pyDie Ausgabe ähnelt wie folgt:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
Hier sind mehrere häufig verwendete Schnittstellen. Weitere Schnittstellen finden Sie unter mvector/predict.py . Sie können sich auch die Beispiele für声纹对比声纹识别ansehen.
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) Lassen Sie uns den Voiceprint -Vergleich implementieren und ein Programm infer_contrast.py erstellen. Zunächst führen wir mehrere wichtige Funktionen ein. predict() kann Voiceprint -Merkmale erhalten, predict_batch() kann eine Stapel von Sprachabdruckfunktionen erhalten, contrast() -Funktion kann die Ähnlichkeit zwischen zwei Audios vergleichen, register() -Funktion registriert einen Audio in die VoicePrint -Bibliothek, ein remove_user() recognition() vergleicht und erkennt die VoicePrint -Bibliothek. Registrieren Sie sich in der Voiceprint -Bibliothek. Wir geben zwei Reden ein und erhalten ihre Merkmalsdaten über die Vorhersagefunktion. Mit diesen Funktionsdaten können wir ihren diagonalen Cosinus -Wert finden, und das Ergebnis kann als Bekanntschaft verwendet werden. Für diese threshold können die Leser sie gemäß den Genauigkeitsanforderungen ihrer Projekte ändern.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavDie Ausgabe ähnelt wie folgt:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
Gleichzeitig wird auch ein Voiceprint -Vergleichsprogramm mit einer GUI -Schnittstelle bereitgestellt. Führen Sie infer_contrast_gui.py aus, um das Programm zu starten. Die Schnittstelle ist wie folgt. Wählen Sie zwei Audios. Klicken Sie hier, um zu beurteilen, um festzustellen, ob sie dieselbe Person sind.
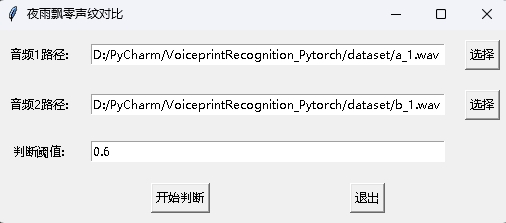
In der Nachrichtenerkennung werden die Funktion register() und recognition() -Funktion hauptsächlich verwendet. Verwenden Sie zunächst register() , um das Audio in der VoicePrint -Bibliothek zu registrieren. Sie können die Datei auch direkt zum Ordner audio_db hinzufügen. Wenn Sie es verwenden, können Sie die Erkennung durch die recognition() -Funktion initiieren. Geben Sie ein Audio ein und Sie können den erforderlichen Sprecher aus der VoicePrint -Bibliothek identifizieren.
Mit der obigen Sprachabdruckerkennungsfunktion können die Leser die Anerkennung der Sprachabdruck nach ihren eigenen Projektanforderungen ausfüllen. Zum Beispiel ist das, was ich unten anbietet, die Erkennung von Sprachabdrücken durch Aufzeichnung zu vervollständigen. Zunächst muss die Stimme in der Sprachbibliothek geladen werden. Der Sprachbibliotheksordner ist audio_db , und dann wird der Benutzer den Sound für 3 Sekunden nach dem Drücken des Autos aufnehmen. Anschließend wird das Programm automatisch den Sound aufgenommen und das aufgenommene Audio für die Erkennung von VoicePrint -Erkennung verwendet, um die Voice in der Sprachbibliothek zu entsprechen und Benutzerinformationen zu erhalten. Auf diese Weise können die Leser es auch ändern, um die Anerkennung von Sprachabdrücken durch Serviceanfragen zu vervollständigen, z. B. eine API für die App zur Anruf bereitzustellen. Wenn sich der Benutzer über Voiceprint in der App anmeldet, sendet er die aufgezeichnete Sprache an das Backend, um die Voiceprint -Erkennung zu vervollständigen, und gibt das Ergebnis dann an die App zurück, sofern der Benutzer die Sprachdaten im Ordner audio_db mit VoicePrint registriert und erfolgreich gespeichert hat.
python infer_recognition.pyDie Ausgabe ähnelt wie folgt:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
Gleichzeitig wird auch ein Sprachabdruckerkennungsprogramm mit einer GUI -Schnittstelle bereitgestellt. Führen Sie infer_recognition_gui.py aus, um zu starten, klicken Sie auf注册音频到声纹库, verstehen Sie und beginnen Sie zu sprechen, zeichnen Sie sie 3 Sekunden lang auf und geben Sie dann den Namen des Registranten ein. Danach können Sie执行声纹识别und dann sofort sprechen. Warten Sie nach 3 Sekunden lang auf das Erkennungsergebnis. Die Schaltfläche删除用户kann den Benutzer löschen. Die实时识别kann in Echtzeit erkannt und in Echtzeit erfasst und erkannt werden.
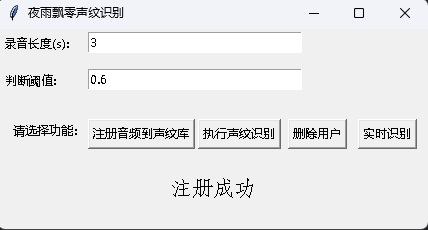
Führen Sie das Programm infer_speaker_diarization.py aus, geben Sie den Audio -Pfad ein und Sie können den Lautsprecher trennen und die Ergebnisse anzeigen. Es wird empfohlen, dass die Audiolänge nicht weniger als 10 Sekunden betragen sollte. Für weitere Funktionen können Sie die Programmparameter anzeigen.
python infer_speaker_diarization.py --audio_path=dataset/test_long.wavDie Ausgabe ähnelt wie folgt:
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
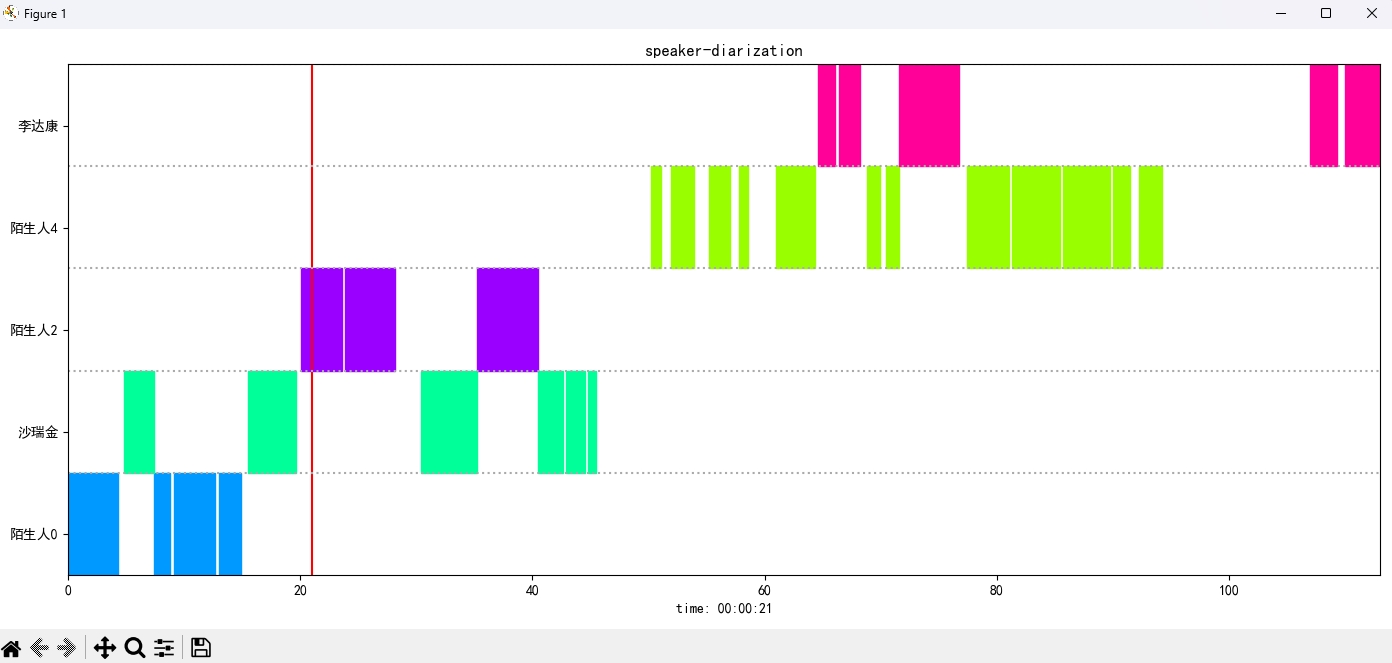
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
Das Ergebnisbild wird wie folgt angezeigt. Sie können die Wiedergabe von Audio durch空格-Leiste steuern. Klicken Sie auf die Position, um zur angegebenen Position zu springen:
Das Projekt bietet auch ein Programm mit der GUI -Schnittstelle, in der das Programm infer_speaker_diarization_gui.py ausführt. Für weitere Funktionen können Sie die Programmparameter anzeigen.
python infer_speaker_diarization_gui.pySie können eine solche Seite öffnen, um den Sprecher zu identifizieren:
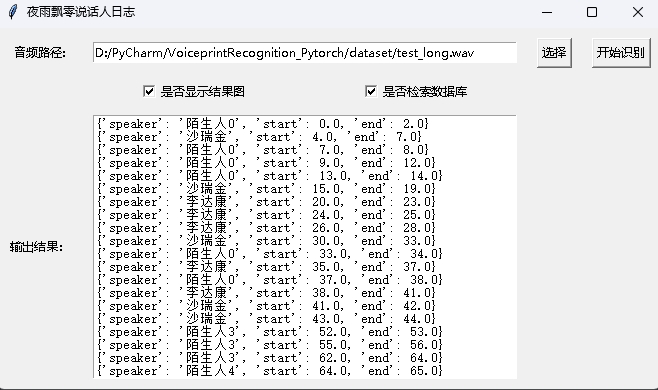
Hinweis: Wenn der Name des Sprechers in Chinesisch ist, müssen Sie die Installationsschrift einstellen, um sie normal anzuzeigen. Im Allgemeinen muss Windows nicht installiert werden, aber Ubuntu muss installiert werden. Wenn Windows tatsächlich Schriftarten fehlt, müssen Sie hier nur die .ttf -Formatdatei herunterladen und in C:WindowsFonts kopieren. Der Ubuntu -Systembetrieb ist wie folgt.
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )Belohnen Sie einen Dollar, um den Autor zu unterstützen


