VoiceprintRecognition Pytorch
1.0.0
Chinois simplifié | Anglais
Cette branche est la version 1.1. Si vous souhaitez utiliser la version 1.0 précédente, veuillez l'utiliser dans la branche 1.0. Ce projet utilise divers modèles avancés de reconnaissance de la priorité vocale tels que EcapatDNN, Resnetse, Eres2Net et Cam ++. Il n'est pas exclu que davantage de modèles seront soutenus à l'avenir. Dans le même temps, ce projet prend également en charge diverses méthodes de prétraitement de données telles que le mélpectrogramme, le spectrogramme, le MFCC et le FBANK. Perte d'arc, perte d'arc de surface: perte de marge angulaire additive (fonction de perte d'intervalle d'angle additif), correspondant à l'Aamloss dans le projet, normalise les vecteurs propres et les poids, et ajoute l'intervalle d'angle M à θ. L'intervalle d'angle a un impact plus direct sur l'angle que l'intervalle de cosinus. De plus, il prend également en charge diverses fonctions de perte telles que les amloss, les armoises et le celoss.
Si ce projet vous est utile, bienvenue Star pour éviter qu'il ne soit pas trouvé plus tard.
Tout le monde est invité à scanner le code pour entrer la planète de connaissances ou le groupe QQ pour discuter. Knowledge Planet fournit des fichiers de modèle de projet et d'autres fichiers de modèles de projets liés des blogueurs, ainsi que d'autres ressources.
Environnement d'utilisation:
Document du modèle:
| Modèle | Paramètres (m) | Ensemble de données | haut-parleurs | seuil | Entourer | Mindcf | Téléchargement du modèle |
|---|---|---|---|---|---|---|---|
| Eres2netv2 | 6.6 | CN-Celeb | 2796 | 0.20089 | 0,08071 | 0,45705 | Rejoignez la planète de connaissances pour obtenir |
| ERES2NET | 6.6 | CN-Celeb | 2796 | 0.20014 | 0,08132 | 0,45544 | Rejoignez la planète de connaissances pour obtenir |
| Came ++ | 6.8 | CN-Celeb | 2796 | 0,23323 | 0,08332 | 0,48536 | Rejoignez la planète de connaissances pour obtenir |
| Resnetse | 7.8 | CN-Celeb | 2796 | 0.19066 | 0,08544 | 0.49142 | Rejoignez la planète de connaissances pour obtenir |
| Ecapatdnn | 6.1 | CN-Celeb | 2796 | 0,23646 | 0,09259 | 0,51378 | Rejoignez la planète de connaissances pour obtenir |
| TDNN | 2.6 | CN-Celeb | 2796 | 0,23858 | 0.10825 | 0,59545 | Rejoignez la planète de connaissances pour obtenir |
| Res2net | 5.0 | CN-Celeb | 2796 | 0.19526 | 0.12436 | 0,65347 | Rejoignez la planète de connaissances pour obtenir |
| Came ++ | 6.8 | Ensemble de données plus grand | 2W + | 0,33 | 0,07874 | 0,52524 | Rejoignez la planète de connaissances pour obtenir |
| ERES2NET | 55.1 | Autres ensembles de données | 20W + | 0,36 | 0,02936 | 0.18355 | Rejoignez la planète de connaissances pour obtenir |
| Eres2netv2 | 56.2 | Autres ensembles de données | 20W + | 0,36 | 0,03847 | 0.24301 | Rejoignez la planète de connaissances pour obtenir |
| Came ++ | 6.8 | Autres ensembles de données | 20W + | 0,29 | 0,04765 | 0,31436 | Rejoignez la planète de connaissances pour obtenir |
illustrer:
speed_perturb_3_class: True .Fbank et la fonction de perte est AAMLoss .| Modèle | Paramètres (m) | Ensemble de données | haut-parleurs | seuil | Entourer | Mindcf | Téléchargement du modèle |
|---|---|---|---|---|---|---|---|
| Came ++ | 6.8 | Voxceleb1 et 2 | 7205 | 0,22504 | 0,02436 | 0,15543 | Rejoignez la planète de connaissances pour obtenir |
| Ecapatdnn | 6.1 | Voxceleb1 et 2 | 7205 | 0,24877 | 0,02480 | 0.16188 | Rejoignez la planète de connaissances pour obtenir |
| Eres2netv2 | 6.6 | Voxceleb1 et 2 | 7205 | 0.20710 | 0,02742 | 0.17709 | Rejoignez la planète de connaissances pour obtenir |
| ERES2NET | 6.6 | Voxceleb1 et 2 | 7205 | 0.20233 | 0,02954 | 0.17377 | Rejoignez la planète de connaissances pour obtenir |
| Resnetse | 7.8 | Voxceleb1 et 2 | 7205 | 0,22567 | 0,03189 | 0.23040 | Rejoignez la planète de connaissances pour obtenir |
| TDNN | 2.6 | Voxceleb1 et 2 | 7205 | 0,23834 | 0,03486 | 0,26792 | Rejoignez la planète de connaissances pour obtenir |
| Res2net | 5.0 | Voxceleb1 et 2 | 7205 | 0.19472 | 0,04370 | 0.40072 | Rejoignez la planète de connaissances pour obtenir |
| Came ++ | 6.8 | Ensemble de données plus grand | 2W + | 0,28 | 0,03182 | 0,23731 | Rejoignez la planète de connaissances pour obtenir |
| ERES2NET | 55.1 | Autres ensembles de données | 20W + | 0,53 | 0,08904 | 0,62130 | Rejoignez la planète de connaissances pour obtenir |
| Eres2netv2 | 56.2 | Autres ensembles de données | 20W + | 0,52 | 0,08649 | 0,64193 | Rejoignez la planète de connaissances pour obtenir |
| Came ++ | 6.8 | Autres ensembles de données | 20W + | 0,49 | 0.10334 | 0,71200 | Rejoignez la planète de connaissances pour obtenir |
illustrer:
speed_perturb_3_class: True .Fbank et la fonction de perte est AAMLoss .| Méthode de prétraitement | Ensemble de données | haut-parleurs | seuil | Entourer | Mindcf | Téléchargement du modèle |
|---|---|---|---|---|---|---|
| Fbank | CN-Celeb | 2796 | 0.14574 | 0.10988 | 0,58955 | Rejoignez la planète de connaissances pour obtenir |
| MFCC | CN-Celeb | 2796 | 0.14868 | 0,11483 | 0,61275 | Rejoignez la planète de connaissances pour obtenir |
| Spectrogramme | CN-Celeb | 2796 | 0.14962 | 0,11613 | 0,60057 | Rejoignez la planète de connaissances pour obtenir |
| Mélant | CN-Celeb | 2796 | 0.13458 | 0.12498 | 0,60741 | Rejoignez la planète de connaissances pour obtenir |
| wavlm-base-plus | CN-Celeb | 2796 | 0.14166 | 0.13247 | 0,62451 | Rejoignez la planète de connaissances pour obtenir |
| W2V-BERT-2.0 | CN-Celeb | 2796 | Rejoignez la planète de connaissances pour obtenir | |||
| wav2vec2-large-xlsr-53 | CN-Celeb | 2796 | Rejoignez la planète de connaissances pour obtenir | |||
| wavlm-gard | CN-Celeb | 2796 | Rejoignez la planète de connaissances pour obtenir |
illustrer:
CAM++ et la fonction de perte est AAMLoss .extract_features.py pour extraire les fonctionnalités à l'avance, ce qui signifie que l'amélioration des données de l'audio n'est pas utilisée pendant la formation.w2v-bert-2.0 , wav2vec2-large-xlsr-53 sont obtenus à partir de la pré-formation des données multilingues. Les données pré-formation de wavlm-base-plus et wavlm-large sont uniquement en anglais.| Fonction de perte | Ensemble de données | haut-parleurs | seuil | Entourer | Mindcf | Téléchargement du modèle |
|---|---|---|---|---|---|---|
| Aamloss | CN-Celeb | 2796 | 0.14574 | 0.10988 | 0,58955 | Rejoignez la planète de connaissances pour obtenir |
| Sphereface2 | CN-Celeb | 2796 | 0.20377 | 0.11309 | 0,61536 | Rejoignez la planète de connaissances pour obtenir |
| Tripletangular marginloss | CN-Celeb | 2796 | 0.28940 | 0,11749 | 0,63735 | Rejoignez la planète de connaissances pour obtenir |
| Subventerloss | CN-Celeb | 2796 | 0.13126 | 0,11775 | 0,56995 | Rejoignez la planète de connaissances pour obtenir |
| Armloss | CN-Celeb | 2796 | 0.14563 | 0,11805 | 0,57171 | Rejoignez la planète de connaissances pour obtenir |
| Amloss | CN-Celeb | 2796 | 0.12870 | 0.12301 | 0,63263 | Rejoignez la planète de connaissances pour obtenir |
| Celoss | CN-Celeb | 2796 | 0.13607 | 0.12684 | 0,65176 | Rejoignez la planète de connaissances pour obtenir |
illustrer:
CAM++ et la méthode de prétraitement est Fbank .extract_features.py pour extraire les fonctionnalités à l'avance, ce qui signifie que l'amélioration des données de l'audio n'est pas utilisée pendant la formation. conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidiaUtilisez PIP pour installer, la commande est la suivante:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleIl est recommandé d'installer le code source , qui peut garantir l'utilisation du dernier code.
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
pip install . L'auteur utilise CN-Celeb dans ce tutoriel. Cet ensemble de données a un total d'environ 3 000 données vocales et des données vocales 65W +. Après le téléchargement, vous devez décompresser l'ensemble de données dans le répertoire dataset . De plus, si vous souhaitez évaluer, vous devez également télécharger l'ensemble de tests CN-Celeb. Si le lecteur a d'autres meilleurs ensembles de données, il peut être mélangé ensemble, mais il est préférable d'utiliser le module d'outils de Python aukit pour traiter l'audio, la réduction du bruit et la muet.
La première consiste à créer une liste de données. Le format de la liste de données est <语音文件路径t语音分类标签> . La création de cette liste est principalement pour la commodité de la lecture ultérieure et la commodité de la lecture à l'aide d'autres ensembles de données vocales. Les balises de classification vocale se réfèrent à l'ID unique de l'orateur. Différents ensembles de données vocales peuvent être écrits dans la même liste de données en écrivant des fonctions correspondantes pour générer des listes de données.
Exécutez le programme create_data.py pour terminer la préparation des données.
python create_data.pyAprès avoir exécuté le programme ci-dessus, le format de données suivant sera généré. Si vous souhaitez personnaliser les données, reportez-vous à la liste de données suivante. Le front est le chemin relatif de l'audio, et le dos est l'étiquette du haut-parleur correspondant à l'audio, qui est la même que la classification. Notez que l'ID de la liste des données de test n'a pas besoin d'être le même que l'ID de formation, ce qui signifie que le locuteur des données de test peut ne pas avoir besoin d'apparaître dans l'ensemble de formation, tant que la même personne dans la liste de données de test est assurée que la même personne a le même ID.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795
La méthode de prétraitement FBANK par défaut est utilisée dans le fichier de configuration. Si vous souhaitez utiliser d'autres méthodes de prétraitement, vous pouvez modifier la méthode d'installation dans le fichier de configuration. La valeur spécifique peut être modifiée en fonction de votre propre situation. Si vous ne savez pas comment définir les paramètres, vous pouvez supprimer directement cette pièce et utiliser directement la valeur par défaut.
# 数据预处理参数
preprocess_conf :
# 是否使用HF上的Wav2Vec2类似模型提取音频特征
use_hf_model : False
# 音频预处理方法,也可以叫特征提取方法
# 当use_hf_model为False时,支持:MelSpectrogram、Spectrogram、MFCC、Fbank
# 当use_hf_model为True时,指定的是HuggingFace的模型或者本地路径,比如facebook/w2v-bert-2.0或者./feature_models/w2v-bert-2.0
feature_method : ' Fbank '
# 当use_hf_model为False时,设置API参数,更参数查看对应API,不清楚的可以直接删除该部分,直接使用默认值。
# 当use_hf_model为True时,可以设置参数use_gpu,指定是否使用GPU提取特征
method_args :
sample_frequency : 16000
num_mel_bins : 80Pendant le processus de formation, la première chose est de lire les données audio, puis d'extraire les fonctionnalités et enfin d'effectuer une formation. Parmi eux, la lecture des données audio et l'extraction des fonctionnalités prennent également du temps, nous pouvons donc choisir d'extraire les fonctionnalités à l'avance. Si nous formons le modèle, nous pouvons charger et extraire directement les fonctionnalités, afin que la vitesse d'entraînement soit plus rapide. Cette fonctionnalité extraite est facultative. Si aucune bonne fonctionnalité n'est extraite, le modèle de formation commencera par lire les données audio puis extraire les fonctionnalités. Les étapes pour extraire les fonctionnalités sont les suivantes:
extract_features.py pour extraire les fonctionnalités. Les fonctionnalités seront enregistrées dans le répertoire dataset/features et généreront une nouvelle liste de données train_list_features.txt , enroll_list_features.txt et trials_list_features.txt . python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/featuresdataset_conf.train_list , dataset_conf.enroll_list et dataset_conf.trials_list pour train_list_features.txt , enroll_list_features.txt et trials_list_features.txt . En utilisant train.py pour former le modèle, ce projet prend en charge plusieurs méthodes de prétraitement audio. Les paramètres preprocess_conf.feature_method du fichier de configuration configs/ecapa_tdnn.yml peuvent être spécifiés. MelSpectrogram est le spectre MEL, Spectrogram est le graphique du spectre, le coefficient CEPPERCECTRAL MFCC MEL Spectrum, etc. La méthode d'amélioration des données peut être spécifiée par le paramètre augment_conf_path . Pendant le processus de formation, VisualDL sera utilisé pour enregistrer le journal de formation. En commençant VisualDL, vous pouvez voir les résultats de la formation à tout moment. La commande de démarrage visualdl --logdir=log --host 0.0.0.0
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyJournal de sortie de la formation:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- 配置文件参数 -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Non-trainable params: 0
Total mult-adds (M): 468.81
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 10.36
Params size (MB): 32.05
Estimated Total Size (MB): 42.44
===============================================================================================
[2023-08-05 09:52:08.084231 INFO ] trainer:train:388 - 训练数据:874175
[2023-08-05 09:52:09.186542 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08
Démarrer VisualDl: visualdl --logdir=log --host 0.0.0.0 , la page VisualDL est la suivante:
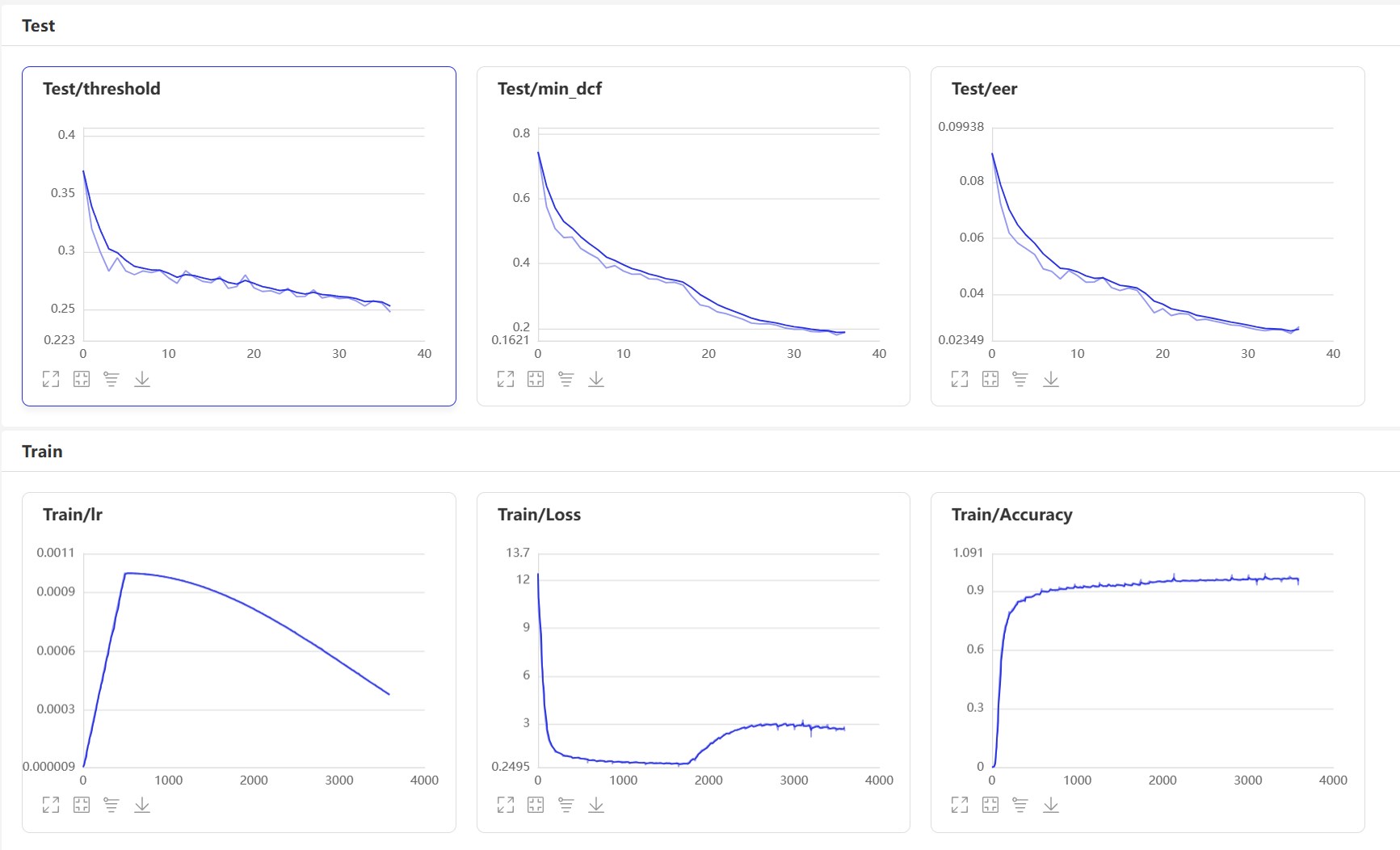
Après la formation, le modèle de prédiction sera sauvé. Nous utilisons le modèle de prédiction pour prédire les fonctionnalités audio dans l'ensemble de tests, puis utilisons les fonctionnalités audio pour les comparer par paires pour calculer EER et MINDCF.
python eval.pyLa sortie est similaire à ce qui suit:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - 成功加载模型:models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
开始两两对比音频特征...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
评估消耗时间:65s,threshold:0.26,EER: 0.14739, MinDCF: 0.41999
Voici plusieurs interfaces couramment utilisées. Pour plus d'interfaces, veuillez vous référer à mvector/predict.py . Vous pouvez également consulter les exemples de声纹对比声纹识别.
from mvector . predict import MVectorPredictor
predictor = MVectorPredictor ( configs = 'configs/cam++.yml' ,
model_path = 'models/CAMPPlus_Fbank/best_model/' )
# 获取音频特征
embedding = predictor . predict ( audio_data = 'dataset/a_1.wav' )
# 获取两个音频的相似度
similarity = predictor . contrast ( audio_data1 = 'dataset/a_1.wav' , audio_data2 = 'dataset/a_2.wav' )
# 注册用户音频
predictor . register ( user_name = '夜雨飘零' , audio_data = 'dataset/test.wav' )
# 识别用户音频
name , score = predictor . recognition ( audio_data = 'dataset/test1.wav' )
# 获取所有用户
users_name = predictor . get_users ()
# 删除用户音频
predictor . remove_user ( user_name = '夜雨飘零' ) Commençons à mettre en œuvre la comparaison de voix de voix et créez un programme infer_contrast.py . Tout d'abord, nous introduisons plusieurs fonctions importantes. predict() peut obtenir des fonctionnalités VoicePrint, predict_batch() peut obtenir un lot de fonctionnalités VoicePrint, contrast() peut comparer la similitude entre deux audios, register() enregistre un audio dans la bibliothèque VoicePrint, entre un audio de recognition() et de composer et de retirer la fonction de la bibliothèque VoicePrint, remove_user() et de retirer la fonction. Inscrivez-vous dans la bibliothèque Voiceprint. Nous entrons dans deux discours et obtenons leurs données de fonctionnalité via la fonction de prédiction. En utilisant ces données de fonctionnalité, nous pouvons trouver leur valeur de cosinus diagonale et le résultat peut être utilisé comme connaissance. Pour ce threshold de reconnaissance, les lecteurs peuvent le modifier en fonction des exigences de précision de leurs projets.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavLa sortie est similaire à ce qui suit:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav 和 audio/b_2.wav 不是同一个人,相似度为:-0.09565544128417969
Dans le même temps, un programme de comparaison VoicePrint avec une interface GUI est également fourni. Exécutez infer_contrast_gui.py pour démarrer le programme. L'interface est la suivante. Sélectionnez deux audios respectivement. Cliquez pour commencer à juger pour déterminer s'il s'agit de la même personne.
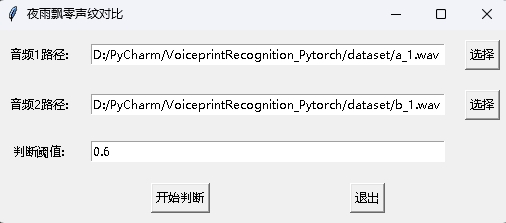
Dans la reconnaissance des nouvelles, la fonction register() et recognition() sont principalement utilisées. Tout d'abord, utilisez register() pour enregistrer l'audio dans la bibliothèque Voiceprint. Vous pouvez également ajouter directement le fichier dans le dossier audio_db . Lorsque vous l'utilisez, vous pouvez initier la reconnaissance via la fonction recognition() . Entrez un audio et vous pouvez identifier le haut-parleur requis à partir de la bibliothèque Voiceprint.
Avec la fonction de reconnaissance ci-dessus de l'empreinte Voice, les lecteurs peuvent compléter la reconnaissance de l'empreinte Voice en fonction de leurs propres besoins de projet. Par exemple, ce que je fournis ci-dessous, c'est compléter la reconnaissance de l'empreinte vocale via l'enregistrement. Tout d'abord, la voix de la bibliothèque vocale doit être chargée. Le dossier de la bibliothèque vocale est audio_db , puis l'utilisateur enregistrera le son pendant 3 secondes après avoir appuyé sur la voiture. Ensuite, le programme enregistrera automatiquement le son et utilisera l'audio enregistré pour la reconnaissance de la priorité de voix pour correspondre à la voix de la bibliothèque vocale et obtiendra des informations utilisateur. De cette façon, les lecteurs peuvent également le modifier pour compléter la reconnaissance de la priorité vocale via les demandes de service, par exemple, fournir une API à appeler l'application. Lorsque l'utilisateur se connecte via VoicePrint sur l'application, il envoie la voix enregistrée au backend pour terminer la reconnaissance de voix de voix, puis renvoie le résultat à l'application, à condition que l'utilisateur soit enregistré avec Voiceprint et stocke avec succès les données vocales dans le dossier audio_db .
python infer_recognition.pyLa sortie est similaire à ce qui suit:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- 额外配置参数 -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
成功加载模型参数和优化方法参数:models/ecapa_tdnn/model.pth
Loaded 沙瑞金 audio.
Loaded 李达康 audio.
请选择功能,0为注册音频到声纹库,1为执行声纹识别:0
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
请输入该音频用户的名称:夜雨飘零
请选择功能,0为注册音频到声纹库,1为执行声纹识别:1
按下回车键开机录音,录音3秒中:
开始录音......
录音已结束!
识别说话的为:夜雨飘零,相似度为:0.920434
Dans le même temps, un programme de reconnaissance vocale avec une interface GUI est également fourni. Exécutez infer_recognition_gui.py pour démarrer, cliquez sur注册音频到声纹库, comprenez et commencez à parler, enregistrez pendant 3 secondes, puis entrez le nom du déclarant. Après cela, vous pouvez执行声纹识别, puis parler immédiatement. Après avoir enregistré pendant 3 secondes, attendez le résultat de reconnaissance. Le bouton删除用户peut supprimer l'utilisateur. Le bouton实时识别peut être reconnu en temps réel et peut être enregistré et reconnu en temps réel.
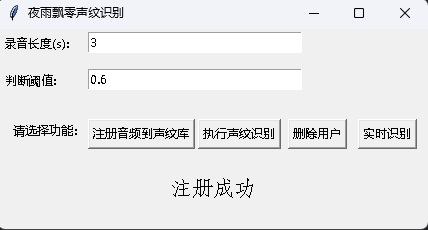
Exécutez le programme infer_speaker_diarization.py , entrez le chemin audio et vous pouvez séparer le haut-parleur et afficher les résultats. Il est recommandé que la longueur audio ne soit pas inférieure à 10 secondes. Pour plus de fonctions, vous pouvez afficher les paramètres du programme.
python infer_speaker_diarization.py --audio_path=dataset/test_long.wavLa sortie est similaire à ce qui suit:
2024-10-10 19:30:40.768 | INFO | mvector.predict:__init__:61 - 成功加载模型参数:models/CAMPPlus_Fbank/best_model/model.pth
2024-10-10 19:30:40.795 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.796 | INFO | mvector.predict:__load_audio_db:142 - 正在加载声纹库数据...
100%|██████████| 3/3 [00:00<?, ?it/s]
2024-10-10 19:30:40.798 | INFO | mvector.predict:__create_index:127 - 声纹特征索引创建完成,一共有3个用户,分别是:['沙瑞金', '夜雨飘零', '李达康']
2024-10-10 19:30:40.798 | INFO | mvector.predict:__load_audio_db:172 - 声纹库数据加载完成!
识别结果:
{'speaker': '沙瑞金', 'start': 0.0, 'end': 2.0}
{'speaker': '陌生人1', 'start': 4.0, 'end': 7.0}
{'speaker': '李达康', 'start': 7.0, 'end': 8.0}
{'speaker': '沙瑞金', 'start': 9.0, 'end': 12.0}
{'speaker': '沙瑞金', 'start': 13.0, 'end': 14.0}
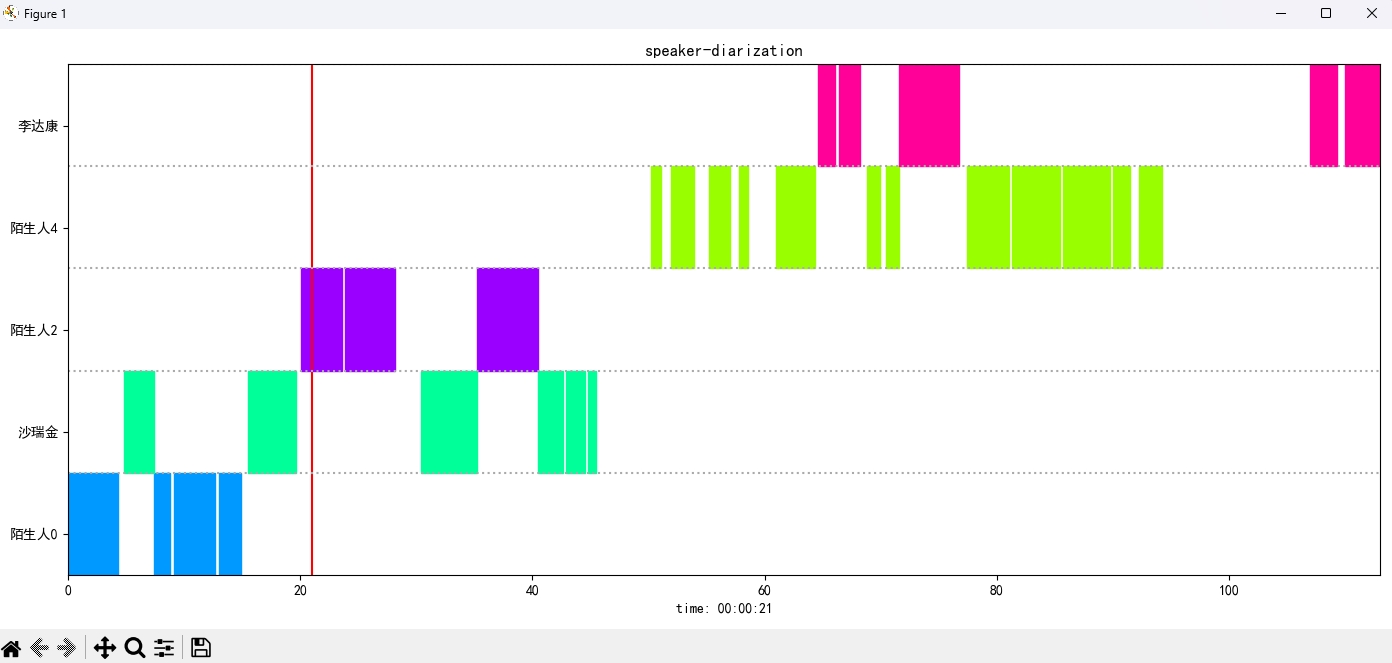
{'speaker': '陌生人1', 'start': 15.0, 'end': 19.0}
L'image du résultat s'affiche comme suit. Vous pouvez contrôler la lecture de l'audio via空格. Cliquez sur la position pour sauter vers la position spécifiée:
Le projet fournit également un programme avec l'interface GUI, en exécutant le programme infer_speaker_diarization_gui.py . Pour plus de fonctions, vous pouvez afficher les paramètres du programme.
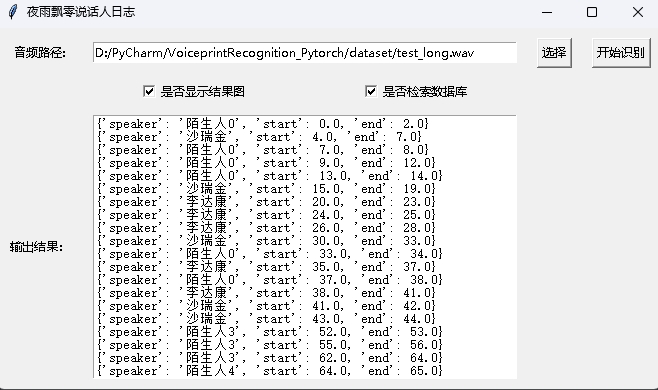
python infer_speaker_diarization_gui.pyVous pouvez ouvrir une telle page pour identifier l'orateur:
Remarque: Si le nom du haut-parleur est en chinois, vous devez définir la police d'installation pour l'afficher normalement. D'une manière générale, Windows n'a pas besoin d'être installé, mais Ubuntu doit être installé. Si Windows manque en effet les polices, il vous suffit de télécharger le fichier de format .ttf ici et de le copier sur C:WindowsFonts . Le fonctionnement du système Ubuntu est le suivant.
git clone https://github.com/tracyone/program_font && cd program_font && ./install.sh import matplotlib
import shutil
import os
path = matplotlib . matplotlib_fname ()
path = path . replace ( 'matplotlibrc' , 'fonts/ttf/' )
print ( path )
shutil . copy ( '/usr/share/fonts/MyFonts/simhei.ttf' , path )
user_dir = os . path . expanduser ( '~' )
shutil . rmtree ( f' { user_dir } /.cache/matplotlib' , ignore_errors = True )Récompensez un dollar pour soutenir l'auteur


