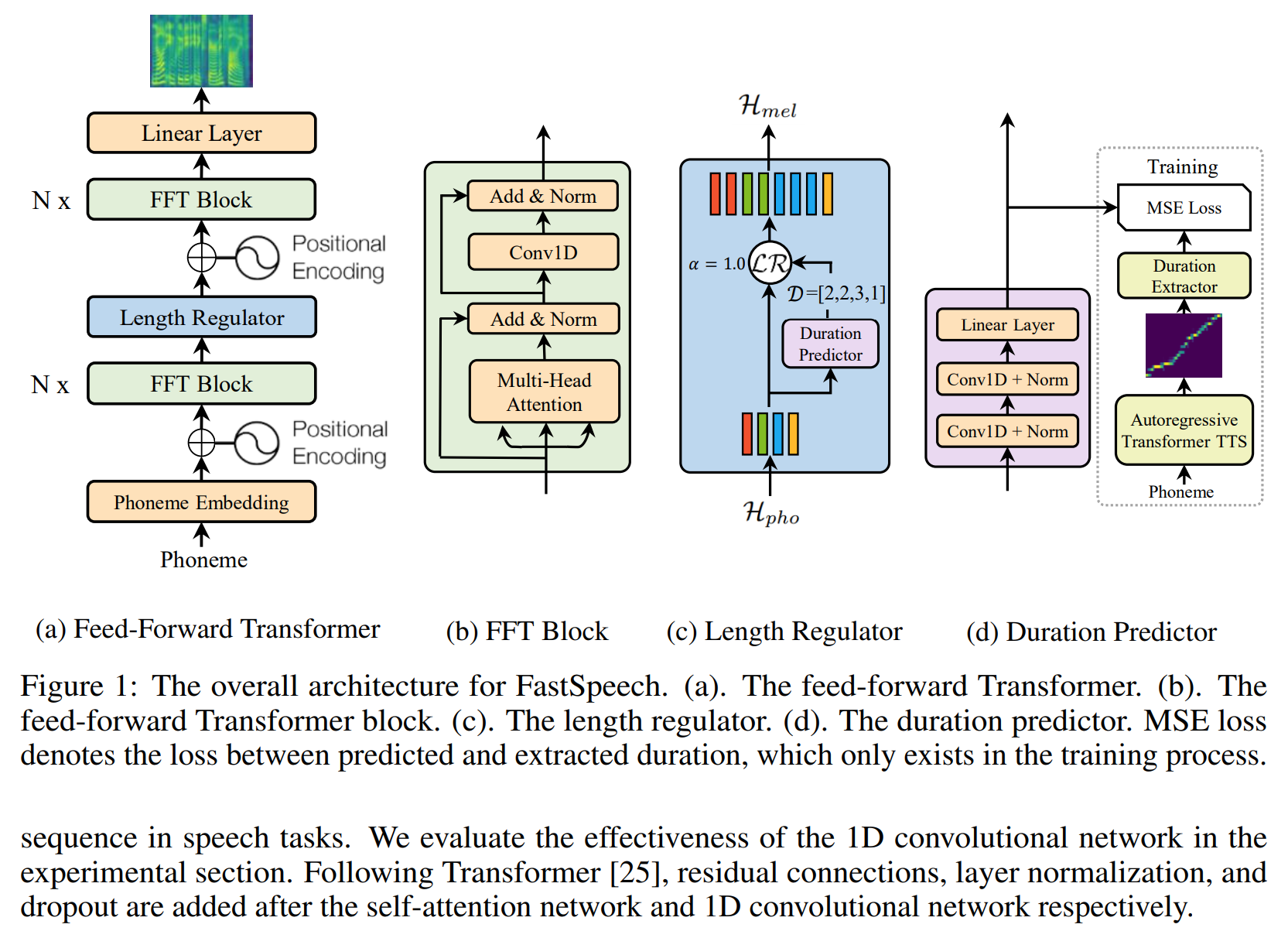
Fastspeech-Pytorch
การใช้งานของ Fastspeech ตาม pytorch
อัปเดต (2020/07/20)
- เพิ่มประสิทธิภาพกระบวนการฝึกอบรม
- เพิ่มประสิทธิภาพการใช้งานของตัวควบคุมความยาว
- ใช้พารามิเตอร์ไฮเปอร์เดียวกันกับ FastSpeech2
- มาตรการของ 1, 2 และ 3 ทำให้กระบวนการฝึกอบรมเร็วขึ้นกว่าเดิม 3 เท่า
- คุณภาพการพูดที่ดีขึ้น
แบบอย่าง
บล็อกของฉัน
- โน้ตการอ่าน Fastspeech
- รายละเอียดและทบทวนการใช้งานนี้
เตรียมชุดข้อมูล
- ดาวน์โหลดและแยกชุดข้อมูล LJSpeech
- ใส่ชุดข้อมูล ljspeech ใน
data - unzip
alignments.zip - ใส่โมเดล Waveglow ของ Nvidia ไว้ใน
waveglow/pretrained_model และเปลี่ยนชื่อเป็น waveglow_256channels.pt ; - เรียกใช้
python3 preprocess.py
การฝึกอบรม
Run python3 train.py
การประเมิน
เรียกใช้ python3 eval.py
หมายเหตุ
- ในกระดาษของ Fastspeech ผู้เขียนใช้โมเดล Transformer-TTS ที่ผ่านการฝึกอบรมมาแล้วเพื่อให้เป้าหมายของการจัดตำแหน่ง ฉันไม่มีรุ่น Transformer-TTS ที่ผ่านการฝึกอบรมมาอย่างดีดังนั้นฉันจึงใช้ Tacotron2 แทน
- ฉันใช้พารามิเตอร์ไฮเปอร์แบบเดียวกันกับ FastSpeech2
- ตัวอย่างเสียงอยู่ใน
sample - แบบจำลองก่อนหน้า
อ้างอิง
ที่เก็บ
- การดำเนินการของทาโคทรอนตาม tensorflow
- การใช้หม้อแปลงตาม pytorch
- การดำเนินการของหม้อแปลง TTS ตาม pytorch
- การดำเนินการของ Tacotron2 ตาม pytorch
- การใช้ FastSpeech2 ขึ้นอยู่กับ pytorch
กระดาษ
- Tacotron2
- หม้อแปลงไฟฟ้า
- จารึก
- FastSpeech2