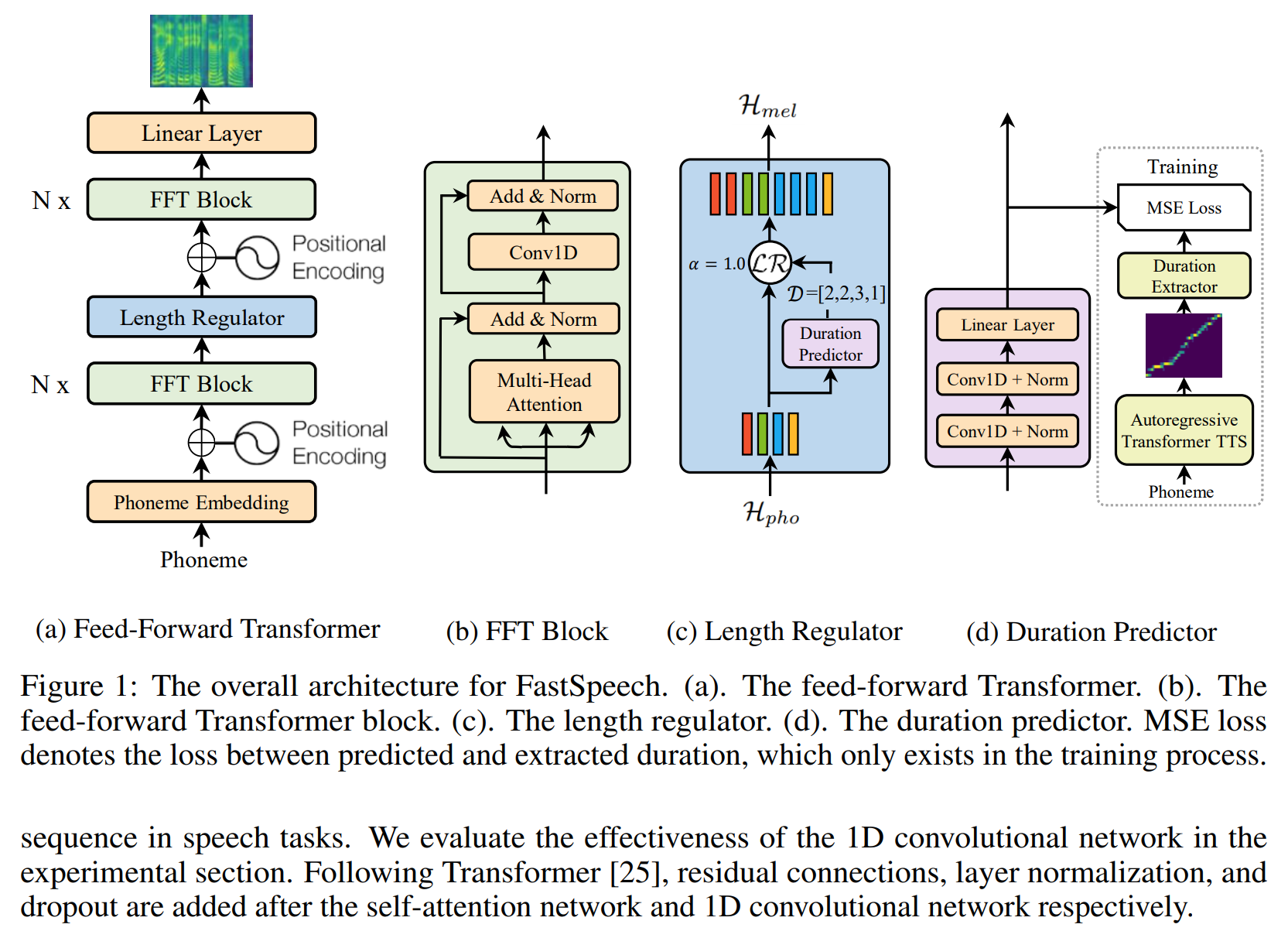
FastSpeech-Pytorch
A implementação do FastSpeech com base no Pytorch.
Atualização (2020/07/20)
- Otimize o processo de treinamento.
- Otimize a implementação do regulador de comprimento.
- Use o mesmo parâmetro hiper que o FastSpeech2.
- As medidas dos 1, 2 e 3 tornam o processo de treinamento 3 vezes mais rápido do que antes.
- Melhor qualidade da fala.
Modelo
Meu blog
- Notas de leitura do FastSpeech
- Detalhes e repensando esta implementação
Prepare o conjunto de dados
- Faça o download e extraia o conjunto de dados LJSpeech.
- Coloque o conjunto de dados LJSpeech em
data . -
alignments.zip DE ZIP.ZIP. - Coloque o modelo NVIDIA pré -criado onda no
waveglow/pretrained_model e renomeie como waveglow_256channels.pt ; - Execute
python3 preprocess.py .
Treinamento
Execute python3 train.py .
Avaliação
Execute python3 eval.py
Notas
- No artigo do FastSpeech, os autores usam o modelo Transformer-TTS pré-treinado para fornecer o alvo de alinhamento. Eu não tinha um modelo Transformer-TTS bem treinado, então uso o Tacotron2.
- Eu uso o mesmo hiper-parâmetro que o FastSpeech2.
- Os exemplos de áudio estão em
sample . - modelo pré -terenciado.
Referência
Repositório
- A implementação do tacotron baseada no tensorflow
- A implementação do transformador baseado em pytorch
- A implementação de transformadores-tts baseados em pytorch
- A implementação do Tacotron2 baseada em Pytorch
- A implementação do FastSpeech2 baseado em pytorch
Papel
- Tacotron2
- Transformador
- FastSpeech
- FastSpeech2