Fastspeech-pytorch
L'implémentation de FastSpeech basée sur Pytorch.
Mise à jour (2020/07/20)
- Optimiser le processus de formation.
- Optimiser la mise en œuvre du régulateur de longueur.
- Utilisez le même paramètre Hyper que FastSpeech2.
- Les mesures des 1, 2 et 3 rendent le processus de formation 3 fois plus rapide qu'auparavant.
- Meilleure qualité de la parole.
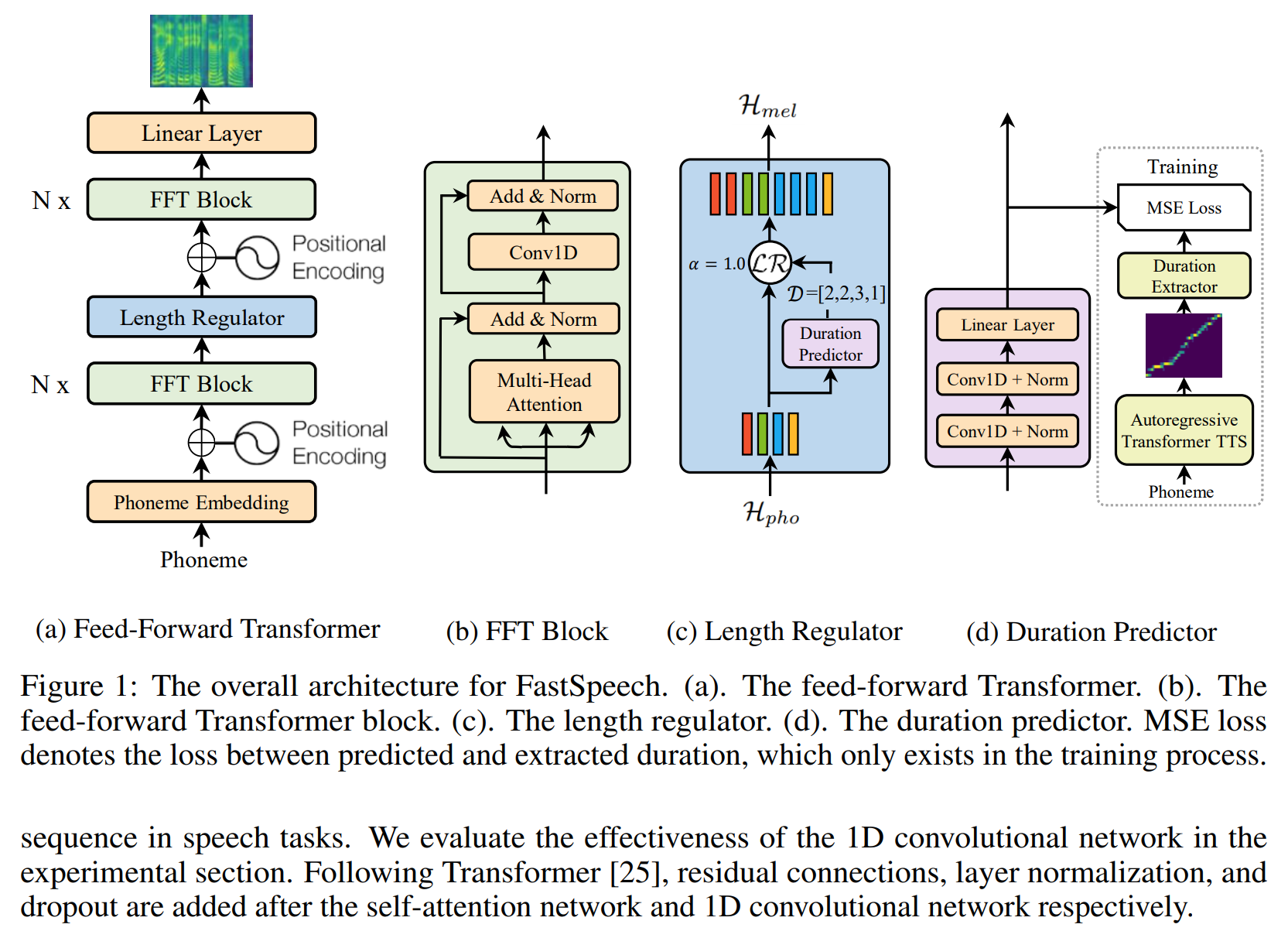
Modèle
Mon blog
- Remarques de lecture FastSpeech
- Détails et repenser cette implémentation
Préparer un ensemble de données
- Télécharger et extraire l'ensemble de données LJSpeech.
- Mettez l'ensemble de données LJSpeech dans
data . - Unzip
alignments.zip . - Mettez le modèle de lutte d'onde prétrainée NVIDIA dans l'
waveglow/pretrained_model et renomme comme waveglow_256channels.pt ; - Exécutez
python3 preprocess.py .
Entraînement
Exécutez python3 train.py .
Évaluation
Exécutez python3 eval.py
Notes
- Dans l'article de FastSpeech, les auteurs utilisent le modèle de transformateur-TTS pré-formé pour fournir la cible de l'alignement. Je n'avais pas de modèle transformateur-TTS bien formé, donc j'utilise Tacotron2 à la place.
- J'utilise le même hyper-paramètre que FastSpeech2.
- Les exemples d'audio sont en
sample . - modèle pré-entraîné.
Référence
Dépôt
- L'implémentation de tacotron basée sur TensorFlow
- L'implémentation de transformateur basé sur Pytorch
- La mise en œuvre de Transformer-TTS basée sur Pytorch
- La mise en œuvre de Tacotron2 basée sur Pytorch
- La mise en œuvre de FastSpeech2 basée sur Pytorch
Papier
- Tacotron2
- Transformateur
- Fast-espèle
- FastSpeech2