FastSpeech-Pytorch
La implementación de FastSpeech basada en Pytorch.
Actualización (2020/07/20)
- Optimizar el proceso de capacitación.
- Optimizar la implementación del regulador de longitud.
- Use el mismo parámetro Hyper que FastSpeech2.
- Las medidas de los 1, 2 y 3 hacen el proceso de entrenamiento 3 veces más rápido que antes.
- Mejor calidad del habla.
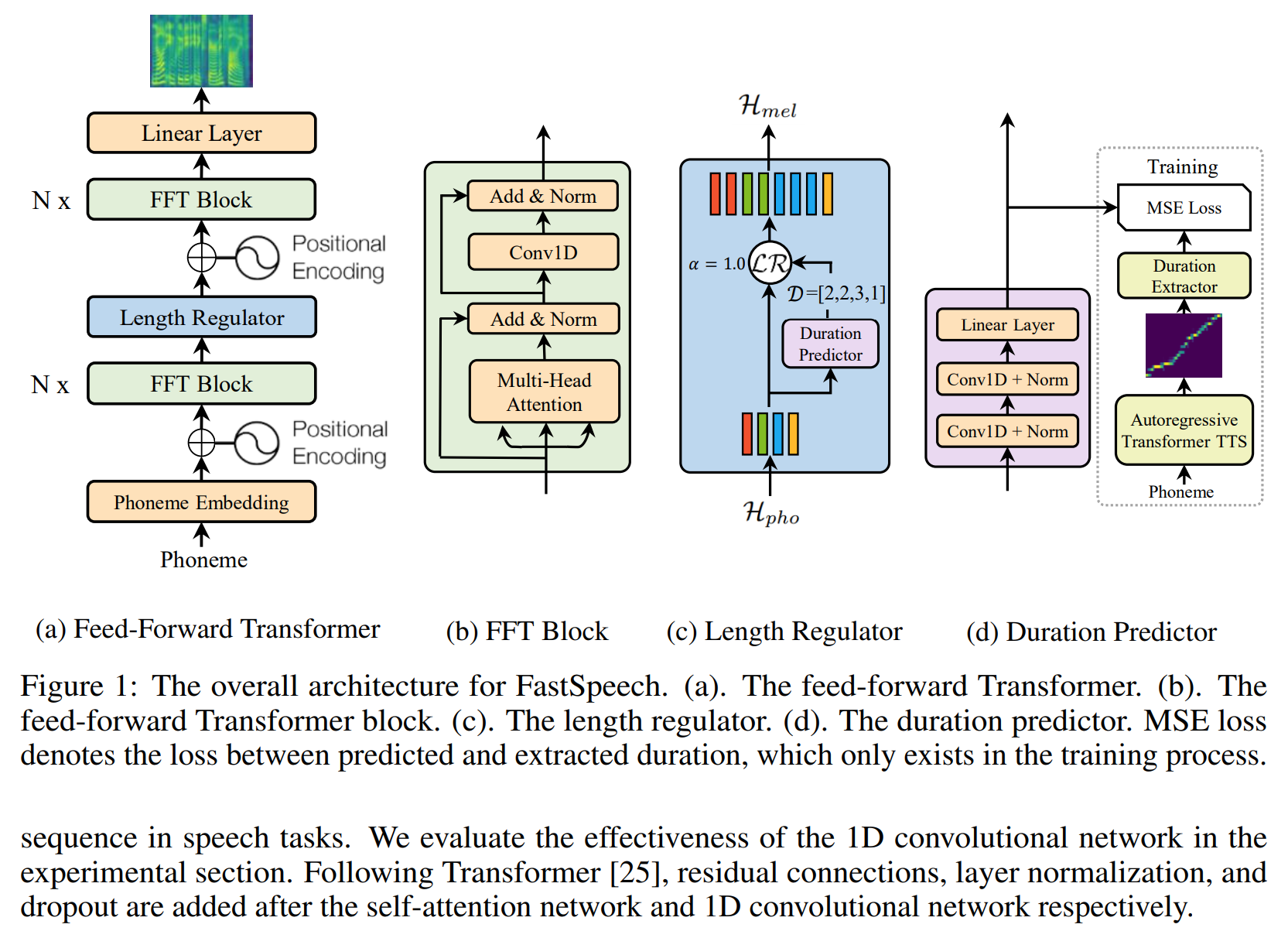
Modelo
Mi blog
- Notas de lectura de FastSpeech
- Detalles y replanteamiento de esta implementación
Preparar el conjunto de datos
- Descargue y extraiga el conjunto de datos LJSPEECH.
- Coloque el conjunto de datos LJSPEECH en
data . -
alignments.zip de descenso.zip. - Ponga el modelo de Glow de onda Pretrado de NVIDIA en el
waveglow/pretrained_model y cambie el nombre de waveglow_256channels.pt ; - Ejecute
python3 preprocess.py .
Capacitación
Corre python3 train.py .
Evaluación
Ejecute python3 eval.py
Notas
- En el documento de FastSpeech, los autores utilizan el modelo Transformer TTS previamente capacitado para proporcionar el objetivo de alineación. No tenía un modelo Transformer-TTS bien entrenado, así que uso Tacotron2 en su lugar.
- Utilizo el mismo hiper-parámetro que FastSpeech2.
- Los ejemplos de audio están en
sample . - modelo previo a la aparición.
Referencia
Repositorio
- La implementación de Tacotron basada en TensorFlow
- La implementación de Transformer basada en Pytorch
- La implementación de Transformer-TTS basada en Pytorch
- La implementación de Tacotron2 basada en Pytorch
- La implementación de FastSpeech2 basada en Pytorch
Papel
- Tacotrón2
- Transformador
- Espacios rápidos
- FastSpeech2