FastSpeech-Pytorch
The Implementation of FastSpeech Based on Pytorch.
Update (2020/07/20)
- Optimize the training process.
- Optimize the implementation of length regulator.
- Use the same hyper parameter as FastSpeech2.
- The measures of the 1, 2 and 3 make the training process 3 times faster than before.
- Better speech quality.
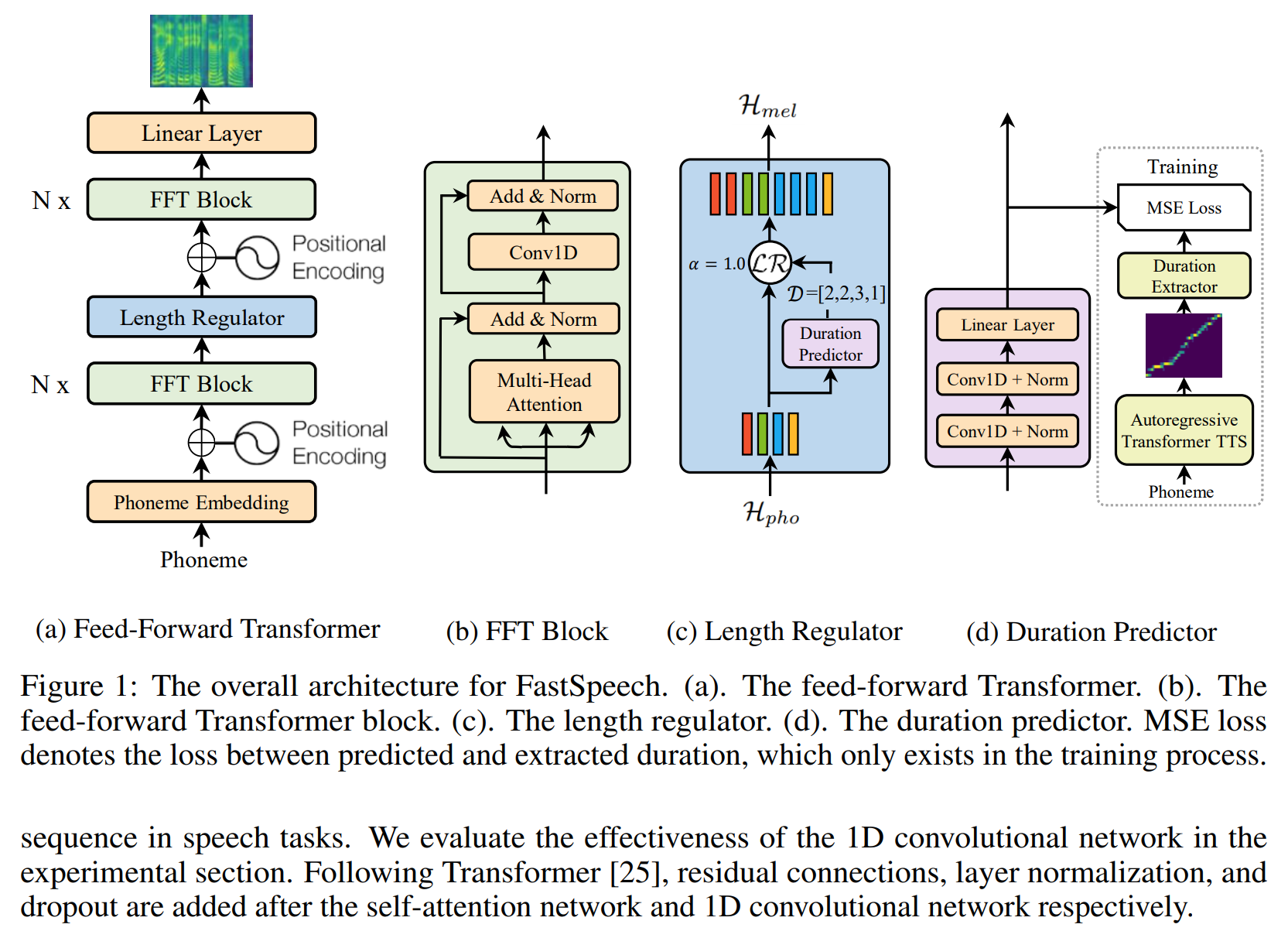
Model
My Blog
- FastSpeech Reading Notes
- Details and Rethinking of this Implementation
Prepare Dataset
- Download and extract LJSpeech dataset.
- Put LJSpeech dataset in
data.
- Unzip
alignments.zip.
- Put Nvidia pretrained waveglow model in the
waveglow/pretrained_model and rename as waveglow_256channels.pt;
- Run
python3 preprocess.py.
Training
Run python3 train.py.
Evaluation
Run python3 eval.py.
Notes
- In the paper of FastSpeech, authors use pre-trained Transformer-TTS model to provide the target of alignment. I didn't have a well-trained Transformer-TTS model so I use Tacotron2 instead.
- I use the same hyper-parameter as FastSpeech2.
- The examples of audio are in
sample.
- pretrained model.
Reference
Repository
- The Implementation of Tacotron Based on Tensorflow
- The Implementation of Transformer Based on Pytorch
- The Implementation of Transformer-TTS Based on Pytorch
- The Implementation of Tacotron2 Based on Pytorch
- The Implementation of FastSpeech2 Based on Pytorch
Paper
- Tacotron2
- Transformer
- FastSpeech
- FastSpeech2