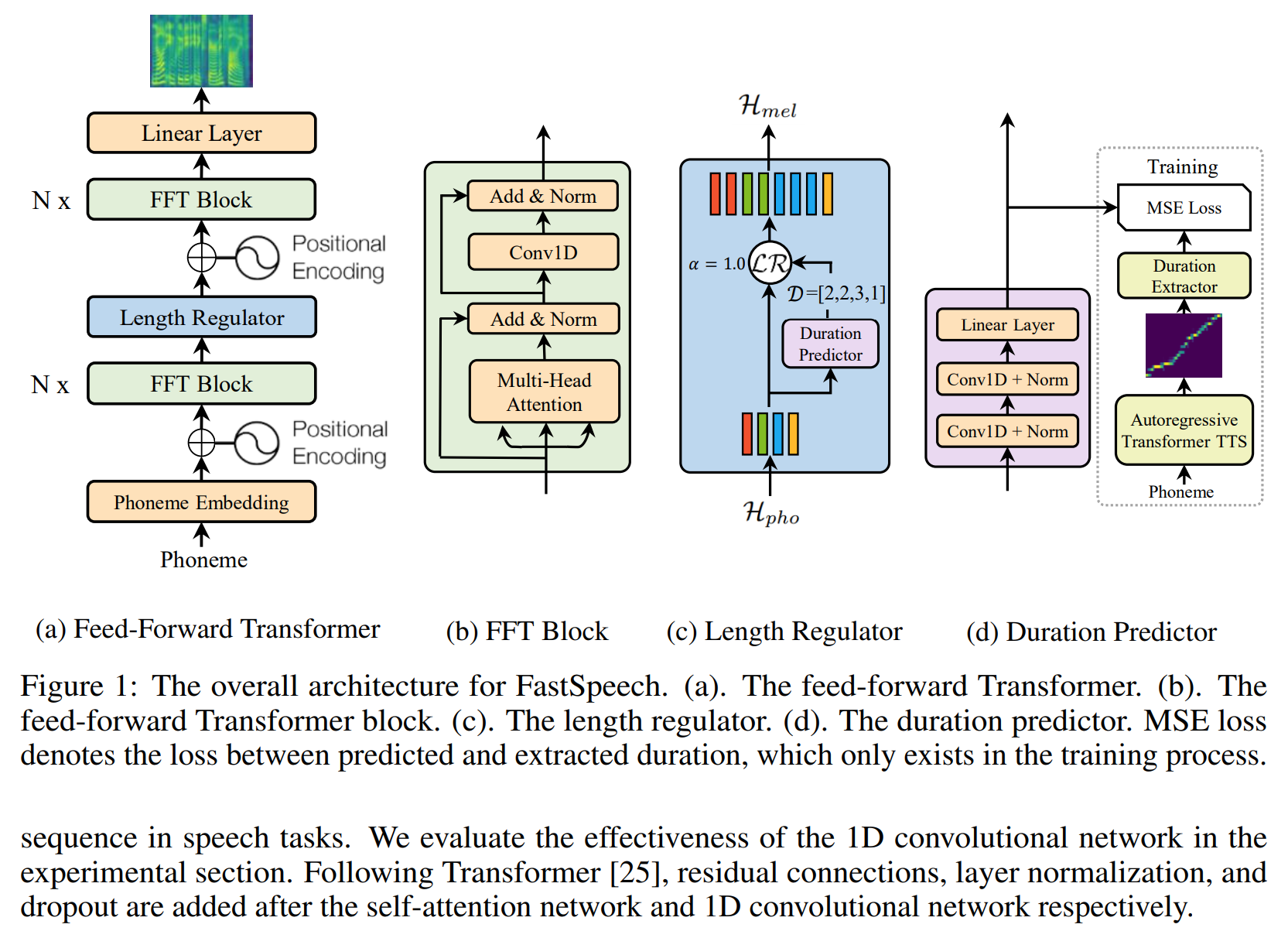
Fastspeech-Pytorch
Die Implementierung von Fastspeech basierend auf Pytorch.
Update (2020/07/20)
- Optimieren Sie den Trainingsprozess.
- Optimieren Sie die Implementierung des Längenreglers.
- Verwenden Sie denselben Hyperparameter wie Fastspeech2.
- Die Maßnahmen der 1, 2 und 3 machen den Trainingsprozess dreimal schneller als zuvor.
- Bessere Sprachqualität.
Modell
Mein Blog
- Fastspeech Reading Notes
- Details und Überdenken dieser Implementierung
Datensatz vorbereiten
- Download und extrahieren Sie LJSpeech -Datensatz.
- Legen Sie den Datensatz von LJSpeech in
data ein. - Unzipp
alignments.zip . - Nvidia vorgebrachtes Wellenlow -Modell in das
waveglow/pretrained_model geben und als waveglow_256channels.pt umbenennen. -
python3 preprocess.py .
Ausbildung
Run python3 train.py .
Auswertung
Rennen Sie python3 eval.py
Notizen
- Im Papier von Fastspeech verwenden Autoren ein vorgebildetes Transformator-TTS-Modell, um das Ziel der Ausrichtung bereitzustellen. Ich hatte kein gut ausgebildetes Transformator-TTS-Modell, daher verwende ich stattdessen Tacotron2.
- Ich benutze den gleichen Hyperparameter wie Fastspeech2.
- Die Beispiele für Audio sind in
sample . - vorbereitetes Modell.
Referenz
Repository
- Die Implementierung von Tacotron basierend auf Tensorflow
- Die Implementierung des Transformators basierend auf Pytorch
- Die Implementierung von Transformator-TTs basierend auf Pytorch
- Die Implementierung von Tacotron2 basierend auf Pytorch
- Die Implementierung von Fastspeech2 basierend auf Pytorch
Papier
- Tacotron2
- Transformator
- Fastspeech
- Fastspeech2