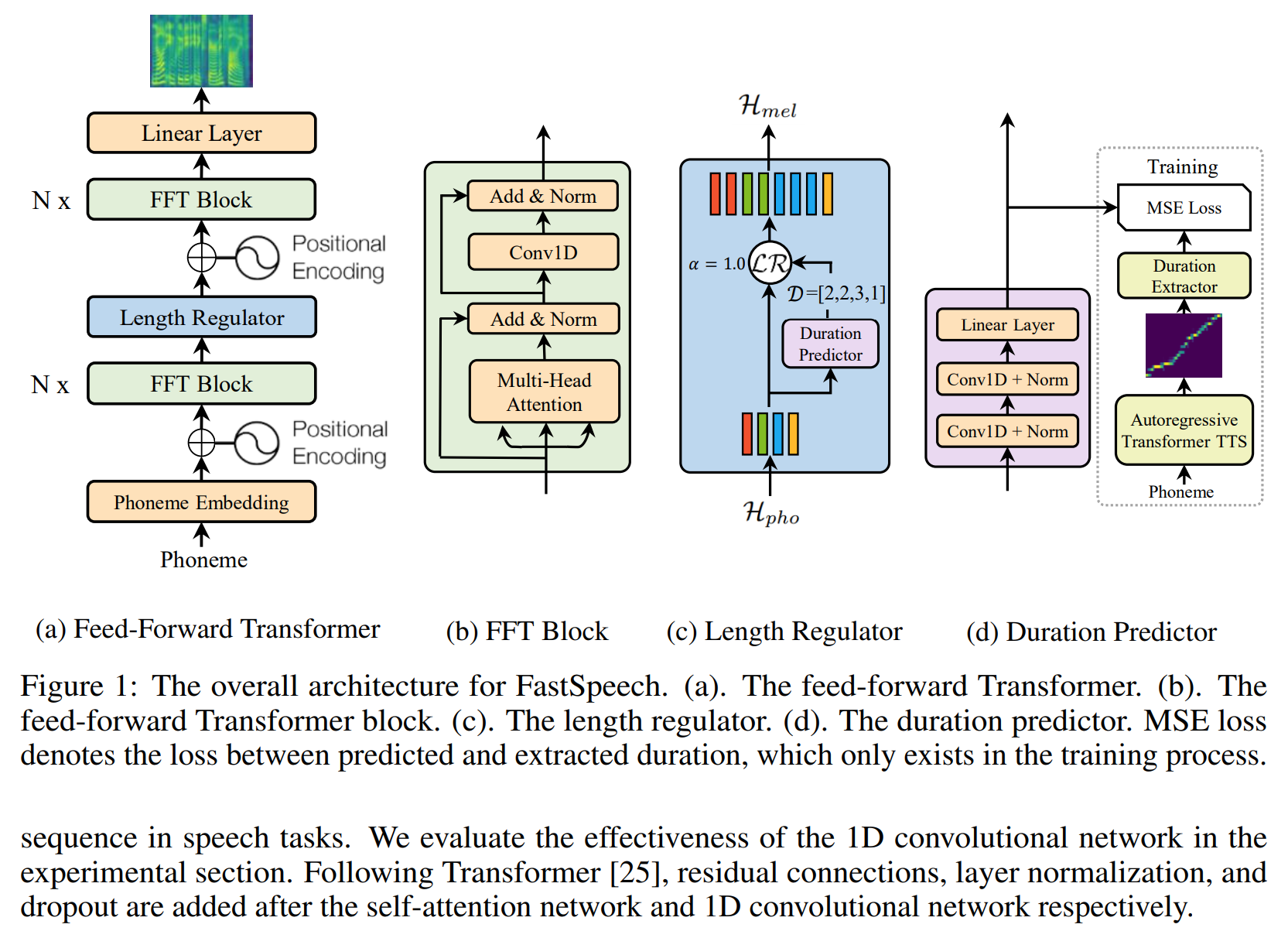
fastspeech-pytorch
Pytorchに基づくFastSpeechの実装。
更新(2020/07/20)
- トレーニングプロセスを最適化します。
- 長さレギュレータの実装を最適化します。
- FastSpeech2と同じハイパーパラメーターを使用します。
- 1、2、3の測定により、トレーニングプロセスは以前よりも3倍高速になります。
- より良い音質の品質。
モデル
私のブログ
- FastSpeechの読み取りメモ
- この実装の詳細と再考
データセットを準備します
- ljspeechデータセットをダウンロードして抽出します。
- ljspeechデータセットを
dataに入れます。 - unzip
alignments.zip 。 - Nvidiaの前処理された波動モデルを
waveglow/pretrained_modelに置き、 waveglow_256channels.ptと名前を変更します。 -
python3 preprocess.pyを実行します。
トレーニング
python3 train.pyを実行します。
評価
python3 eval.pyを実行します。
メモ
- FastSpeechの論文では、著者は事前に訓練されたトランスTTSモデルを使用して、アライメントのターゲットを提供します。よく訓練されたトランスTTSモデルがなかったので、代わりにTacotron2を使用します。
- FastSpeech2と同じハイパーパラメーターを使用しています。
- オーディオの例は
sampleにあります。 - 事前に保護されたモデル。
参照
リポジトリ
- Tensorflowに基づくタコトロンの実装
- Pytorchに基づくトランスの実装
- Pytorchに基づくトランスTTの実装
- Pytorchに基づくTacotron2の実装
- Pytorchに基づくFastSpeech2の実装
紙
- Tacotron2
- トランス
- fastspeech
- fastspeech2