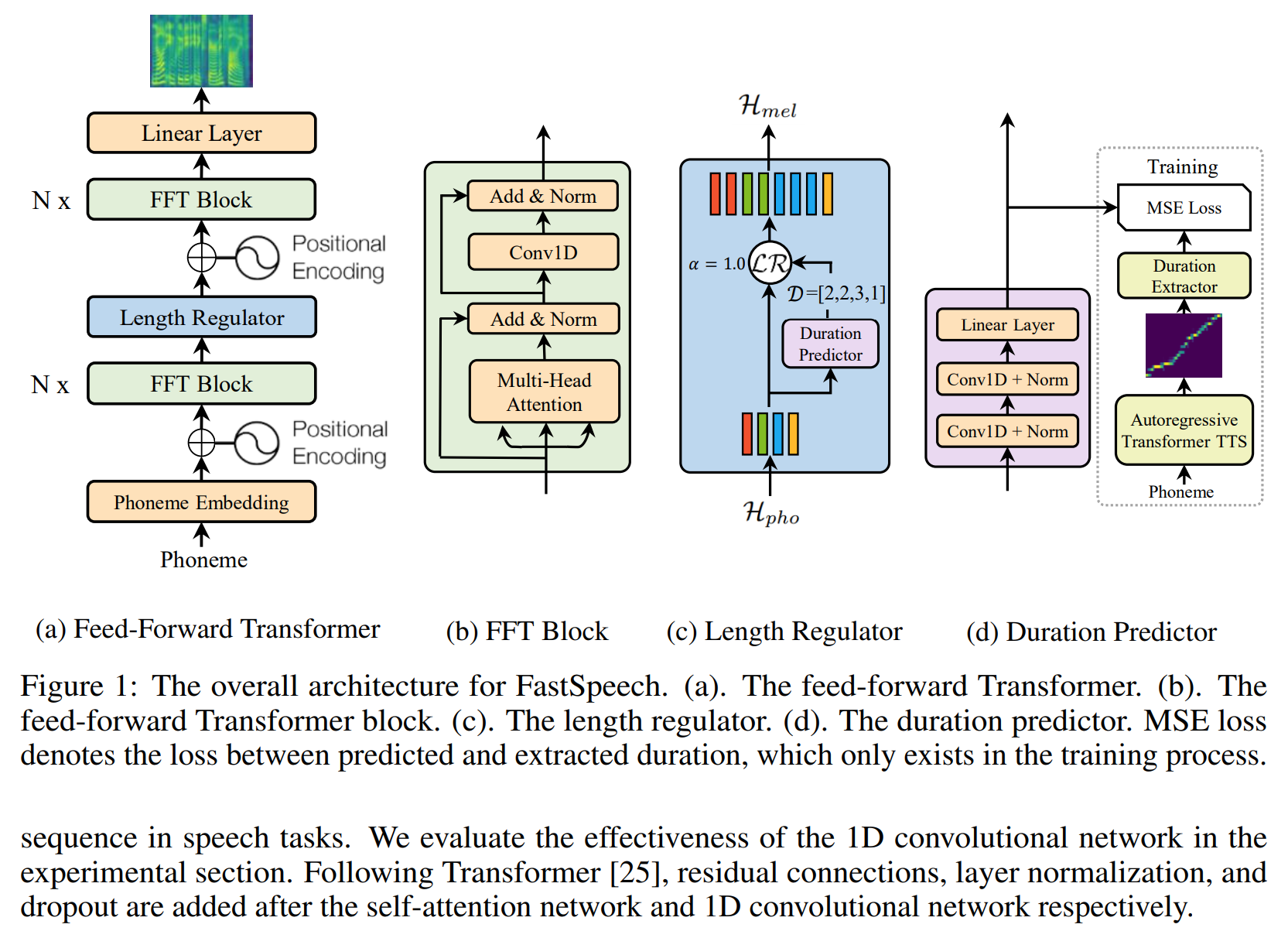
Fastspeech-Pytorch
Implementasi FastSpeech berdasarkan Pytorch.
UPDATE (2020/07/20)
- Optimalkan proses pelatihan.
- Optimalkan implementasi regulator panjang.
- Gunakan parameter hyper yang sama dengan FastSpeech2.
- Ukuran 1, 2 dan 3 membuat proses pelatihan 3 kali lebih cepat dari sebelumnya.
- Kualitas bicara yang lebih baik.
Model
Blog saya
- Catatan Membaca FastSpeech
- Detail dan pemikiran ulang implementasi ini
Siapkan dataset
- Unduh dan ekstrak dataset LJSPEECH.
- Masukkan dataset LJSPEECH ke dalam
data . - UNZIP
alignments.zip . - Letakkan model Waveglow pretrained nvidia di
waveglow/pretrained_model dan ganti nama sebagai waveglow_256channels.pt ; - Jalankan
python3 preprocess.py .
Pelatihan
Jalankan python3 train.py .
Evaluasi
Jalankan python3 eval.py
Catatan
- Dalam makalah FastSpeech, penulis menggunakan model Transformer-TTS pra-terlatih untuk memberikan target penyelarasan. Saya tidak memiliki model Transformer-TTS yang terlatih, jadi saya menggunakan TACOTRON2 sebagai gantinya.
- Saya menggunakan hyper-parameter yang sama dengan FastSpeech2.
- Contoh audio dalam
sample . - model pretrained.
Referensi
Gudang
- Implementasi Tacotron berdasarkan TensorFlow
- Implementasi transformator berdasarkan pytorch
- Implementasi Transformer-TTS berdasarkan Pytorch
- Implementasi TACOTRON2 Berdasarkan Pytorch
- Implementasi FastSpeech2 berdasarkan Pytorch
Kertas
- Tacotron2
- Transformator
- Fastspeech
- Fastspeech2