albert_zh
1.0.0
การดำเนินการตาม Lite Bert สำหรับการเป็นตัวแทนภาษาการเรียนรู้ด้วยตนเองด้วย TensorFlow
อัลเบิร์ตมีพื้นฐานมาจากเบิร์ต แต่มีการปรับปรุงบางอย่าง มันประสบความสำเร็จในการปฏิบัติงานศิลปะบนเกณฑ์มาตรฐานหลักโดยมีพารามิเตอร์ 30% น้อยลง
สำหรับ Albert_Base_ZH มีเพียงสิบเปอร์เซ็นต์พารามิเตอร์เมื่อเทียบกับรุ่น Bert ดั้งเดิมและความแม่นยำหลักจะถูกเก็บไว้
รุ่นที่แตกต่างกันของอัลเบิร์ตที่ได้รับการฝึกอบรมล่วงหน้าสำหรับภาษาจีนรวมถึง Tensorflow, Pytorch และ Keras พร้อมให้บริการแล้ว
โมเดลอัลเบิร์ตที่ผ่านการฝึกอบรมมาก่อนเกี่ยวกับคลังข้อมูลจีนขนาดใหญ่: พารามิเตอร์น้อยลงและผลลัพธ์ที่ดีกว่า โมเดลขนาดเล็กที่ผ่านการฝึกอบรมมาก่อนยังสามารถชนะงาน NLP 13 งานได้
Clueai Toolkit: รหัสสามบรรทัดปรับแต่ง NLP API ในสามนาที (การเรียนรู้ตัวอย่างเป็นศูนย์)

การเปรียบเทียบรายละเอียดของเอฟเฟกต์โมเดลในชุดข้อมูล 10 ชุดรุ่นพื้นฐาน 9 รุ่นและการวิ่งแบบคลิกเดียวดูเบนช์มาร์ก
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1. albert_tiny_zh, albert_tiny_zh (การฝึกอบรมนานขึ้น, สะสม 2 พันล้านตัวอย่างเพื่อเรียนรู้), ขนาดไฟล์ 16m, พารามิเตอร์คือ 4m
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. albert_tiny_google_zh (การเรียนรู้สะสมของตัวอย่าง 1 พันล้านรุ่น, เวอร์ชัน Google), ขนาดรุ่น 16m, ประสิทธิภาพสอดคล้องกับ albert_tiny_zh
1.2. albert_small_google_zh (การเรียนรู้สะสมของตัวอย่าง 1 พันล้านฉบับ, เวอร์ชัน Google),
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
2. albert_large_zh, ปริมาณพารามิเตอร์, จำนวนเลเยอร์ 24, ขนาดไฟล์คือ 64m
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3. Albert_Base_ZH (ได้รับการฝึกอบรมเพิ่มเติมอีก 150 ล้านอินสแตนซ์เช่นขั้นตอน 36K * BATCH_SIZE 4096); albert_base_zh (รุ่นประสบการณ์ขนาดเล็ก), ปริมาณพารามิเตอร์ 12m, จำนวนเลเยอร์ 12, ขนาด 40 เมตร
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. Albert_xlarge_zh_177k; albert_xlarge_zh_183k (ลำดับความสำคัญลอง) ปริมาณพารามิเตอร์จำนวนเลเยอร์ 24 ขนาดไฟล์คือ 230m
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
พึ่งพา HuggingFace-Transformers 2.2.2 รุ่นข้างต้นสามารถเรียกได้ง่าย
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
รายการที่สอดคล้องกันของ MODEL_NAME มีดังนี้:
| ชื่อนางแบบ | model_name |
|---|---|
| albert_tiny_google_zh | เป็นโมฆะ/albert_chinese_tiny |
| albert_small_google_zh | เป็นโมฆะ/albert_chinese_small |
| albert_base_zh (จาก Google) | เป็นโมฆะ/albert_chinese_base |
| albert_large_zh (จาก Google) | เป็นโมฆะ/albert_chinese_large |
| albert_xlarge_zh (จาก Google) | เป็นโมฆะ/albert_chinese_xlarge |
| albert_xxlarge_zh (จาก Google) | เป็นโมฆะ/albert_chinese_xxlarge |
ตัวอย่างเพิ่มเติมของการใช้อัลเบิร์ตผ่านหม้อแปลง
เรียกใช้คำสั่งต่อไปนี้เรียกใช้คำสั่งต่อไปนี้ โครงการมีไฟล์ข้อความตัวอย่างโดยอัตโนมัติ (data/news_zh_1.txt)
bash create_pretrain_data.sh
หากคุณมีไฟล์ข้อความจำนวนมากคุณสามารถสร้างไฟล์หลายรูปแบบของรูปแบบเฉพาะโดยผ่านพารามิเตอร์ (tfrecords)
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
ใช้ python3 + tensorflow 1.x
เช่น tensorflow 1.4 หรือ 1.5
ใช้ Albert_Base สำหรับงาน LCQMC เป็นตัวอย่าง งาน LCQMC คือการทำนายความคล้ายคลึงกันของข้อความในชุดข้อมูลคำอธิบายภาษาพูด
เราจะใช้ชุดข้อมูล LCQMC สำหรับการปรับแต่งมันเป็นคลังภาษาปากมันถูกใช้ในการฝึกอบรมและทำนายความคล้ายคลึงกันทางความหมายของประโยคคู่หนึ่ง
ดาวน์โหลดชุดข้อมูล LCQMC ซึ่งมีการฝึกอบรมการตรวจสอบและชุดทดสอบ ชุดการฝึกอบรมประกอบด้วยคู่ประโยคจีน 240,000 คู่พร้อมคำอธิบายภาษาศาสตร์โดยมีป้ายกำกับ 1 หรือ 0. 1 เป็นประโยคความคล้ายคลึงกันของความหมายและ 0 มีความหมายแตกต่างกัน
ทำการปรับแต่งอย่างละเอียดในชุดข้อมูล LCQMC โดยเรียกใช้คำสั่งต่อไปนี้:
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03: เพิ่มเวอร์ชัน Google ของ Albert_Small, Albert_tiny;
เพิ่มวิธีการปรับใช้ ablert_tiny ไปยังอุปกรณ์มือถือด้วยเวลาอนุมานเพียง 0.1 วินาทีสำหรับความยาวลำดับ 128, หน่วยความจำ 60m ******
***** 2019-10-30: เพิ่มคู่มือง่ายๆเกี่ยวกับการแปลงโมเดลเป็น tensorflow lite สำหรับการปรับใช้ขอบ *****
***** 2019-10-15: Albert_tiny_zh เร็วกว่าฐานเบิร์ต 10 เท่าสำหรับการฝึกอบรมและการอนุมานความแม่นยำยังคงอยู่ *****
***** 2019-10-07: รุ่นเพิ่มเติมของ Albert *****
เพิ่ม albert_xlarge_zh; albert_base_zh_additional_steps ฝึกอบรมด้วยอินสแตนซ์เพิ่มเติม
***** 2019-10-04: Albert รุ่น Pytorch และ Keras ได้รับการสนับสนุน *****
a.convert to pytorch เวอร์ชันและทำงานของคุณผ่าน albert_pytorch
B.Load รุ่นที่ผ่านการฝึกอบรมล่วงหน้าด้วย keras โดยใช้รหัสหนึ่งบรรทัดผ่าน bert4keras
C. ใช้อัลเบิร์ตด้วย tensorflow 2.0: ใช้หรือโหลดโมเดลที่ผ่านการฝึกอบรมมาก่อนด้วย TF2.0 ผ่าน Bert-for-TF2
ปล่อย Albert_xlarge ในวันที่ 6 ต.ค.
***** 2019-10-02: albert_large_zh, albert_base_zh *****
Relesed Albert_Base_ZH ที่มีพารามิเตอร์เพียง 10% ของ BERT_BASE รุ่นเล็ก (40 ม.) และการฝึกอบรมอาจเร็วมาก
RELLAST ALBERT_LARGE_ZH มีพารามิเตอร์เพียง 16% ของ BERT_BASE (64M)
***** 2019-09-28: รหัสและฟังก์ชั่นทดสอบ *****
เพิ่มรหัสและฟังก์ชั่นทดสอบสำหรับการเปลี่ยนแปลงหลักสามประการของอัลเบิร์ตจากเบิร์ต
โมเดลอัลเบิร์ตเป็นรุ่นที่ได้รับการปรับปรุงของเบิร์ต ซึ่งแตกต่างจากรูปแบบล่าสุดของงานศิลปะคราวนี้มันเป็นรุ่นเล็กที่ผ่านการฝึกอบรมมาก่อนพร้อมผลลัพธ์ที่ดีกว่าและพารามิเตอร์น้อยลง
มันได้ทำการเปลี่ยนแปลงสามครั้งกับการเปลี่ยนแปลงหลักสามประการของอัลเบิร์ตจากเบิร์ต:
1) การกำหนดพารามิเตอร์แบบฝังตัวของพารามิเตอร์เวกเตอร์การฝังคำ
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) การแบ่งปันพารามิเตอร์ข้ามชั้น
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) งานความต่อเนื่องของการสูญเสียการเชื่อมโยงกันระหว่างประโยค
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
การเปลี่ยนแปลงอื่น ๆ :
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
คลังภาษาจีน 30 กรัมมีตัวละครจีนมากกว่า 10 พันล้านตัวรวมถึงสารานุกรมหลายฉบับข่าวและชุมชนอินเทอร์แอคทีฟ
ลำดับความยาวลำดับที่ผ่านการฝึกอบรมมาก่อนถูกตั้งค่าเป็น 512 แบทช์ batch_size คือ 4096 และการฝึกอบรมสร้างข้อมูลการฝึกอบรม 350 ล้าน (อินสแตนซ์); แต่ละรุ่นจะฝึกอบรมขั้นตอน 125K โดยค่าเริ่มต้นและ Albert_xxLarge จะได้รับการฝึกฝนมานานขึ้น
สำหรับการเปรียบเทียบ Roberta_ZH Pre-Training สร้างข้อมูลการฝึกอบรม 250 ล้านครั้งที่มีความยาวลำดับ 256 เนื่องจาก Albert_ZH การฝึกอบรมก่อนสร้างข้อมูลการฝึกอบรมมากขึ้นและใช้ความยาวลำดับที่ยาวขึ้น
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
การฝึกอบรมใช้ TPU V3 POD เราใช้ V3-256 ซึ่งมี 32 V3-8S เครื่อง V3-8 แต่ละเครื่องมีหน่วยความจำวิดีโอ 128 กรัม
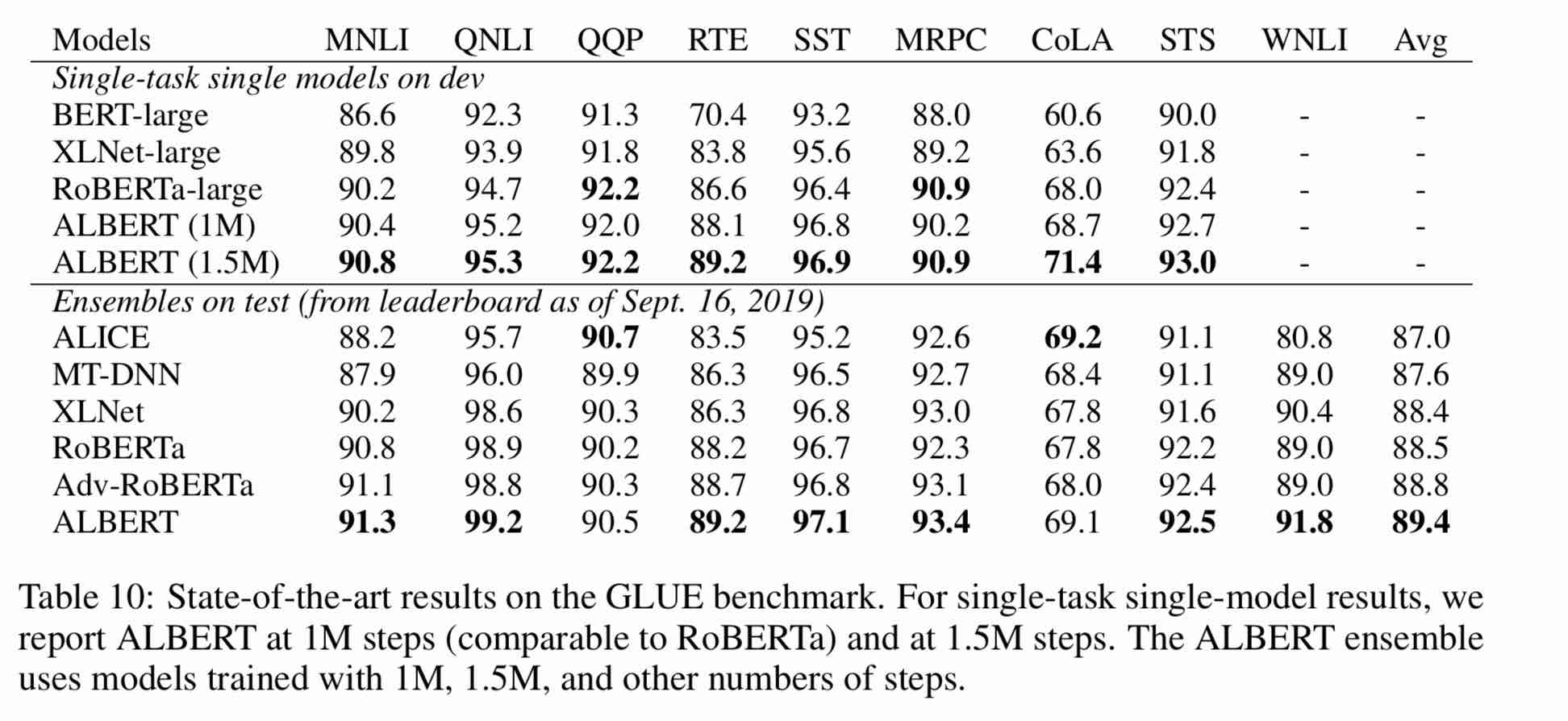
| แบบอย่าง | ชุดพัฒนา (dev) | ชุดทดสอบ (ทดสอบ) |
|---|---|---|
| เบิร์ต | 89.4 (88.4) | 86.9 (86.4) |
| เออร์นี่ | 89.8 (89.6) | 87.2 (87.0) |
| bert-wwm | 89.4 (89.2) | 87.0 (86.8) |
| bert-wwm-ext | - | - |
| Roberta-Zh-base | 88.7 | 87.0 |
| Roberta-ZH-large | 89.9 (89.6) | 87.2 (86.7) |
| Roberta-ZH-Large (20W_steps) | 89.7 | 87.0 |
| Albert-Zh-tiny | - | 85.4 |
| Albert-Zh-Small | - | 86.0 |
| Albert-Zh-Small (Pytorch) | - | 86.8 |
| Albert-Zh-base-additional-36K-steps | 87.8 | 86.3 |
| อัลเบิร์ต-ZH-base | 87.2 | 86.3 |
| อัลเบิร์ตขนาดใหญ่ | 88.7 | 87.1 |
| อัลเบิร์ต-xlarge | 87.3 | 87.7 |
หมายเหตุ: ฉันวิ่งเพียง Albert-Xlarge หนึ่งครั้งและอาจมีการปรับปรุงเอฟเฟกต์
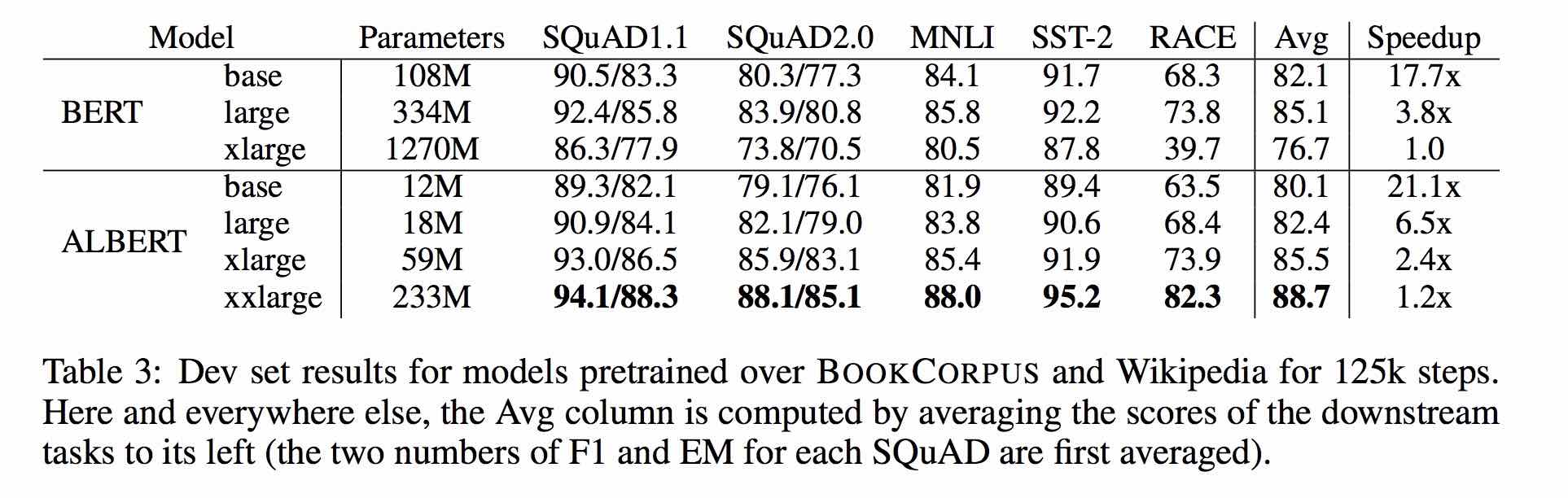
| แบบอย่าง | ชุดพัฒนา | ชุดทดสอบ |
|---|---|---|
| เบิร์ต | 77.8 (77.4) | 77.8 (77.5) |
| เออร์นี่ | 79.7 (79.4) | 78.6 (78.2) |
| bert-wwm | 79.0 (78.4) | 78.2 (78.0) |
| bert-wwm-ext | 79.4 (78.6) | 78.7 (78.3) |
| xlnet | 79.2 | 78.7 |
| Roberta-Zh-base | 79.8 | 78.8 |
| Roberta-ZH-large | 80.2 (80.0) | 79.9 (79.5) |
| แอลเบิร์ตเบส | 77.0 | 77.1 |
| อัลเบิร์ตขนาดใหญ่ | 78.0 | 77.5 |
| อัลเบิร์ต-xlarge | - | - |
หมายเหตุ: bert-wwm-ext มาจากที่นี่; Xlnet มาจากที่นี่; Roberta-ZH-base หมายถึงโมเดลจีน 12 ชั้น Roberta
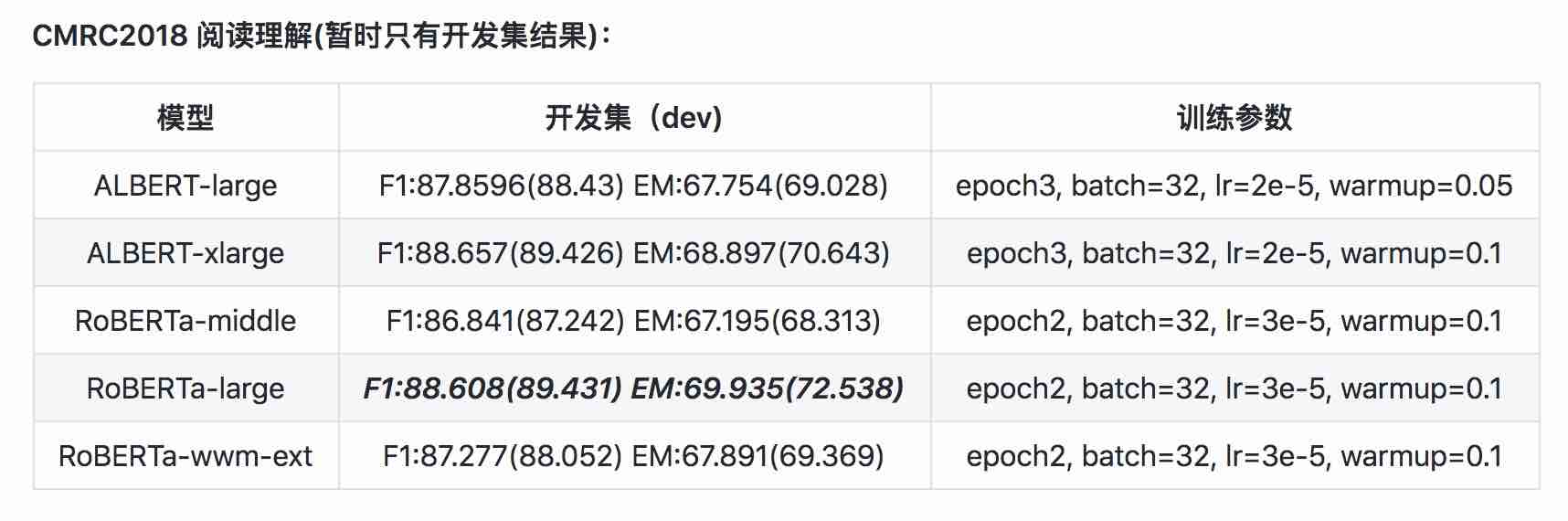
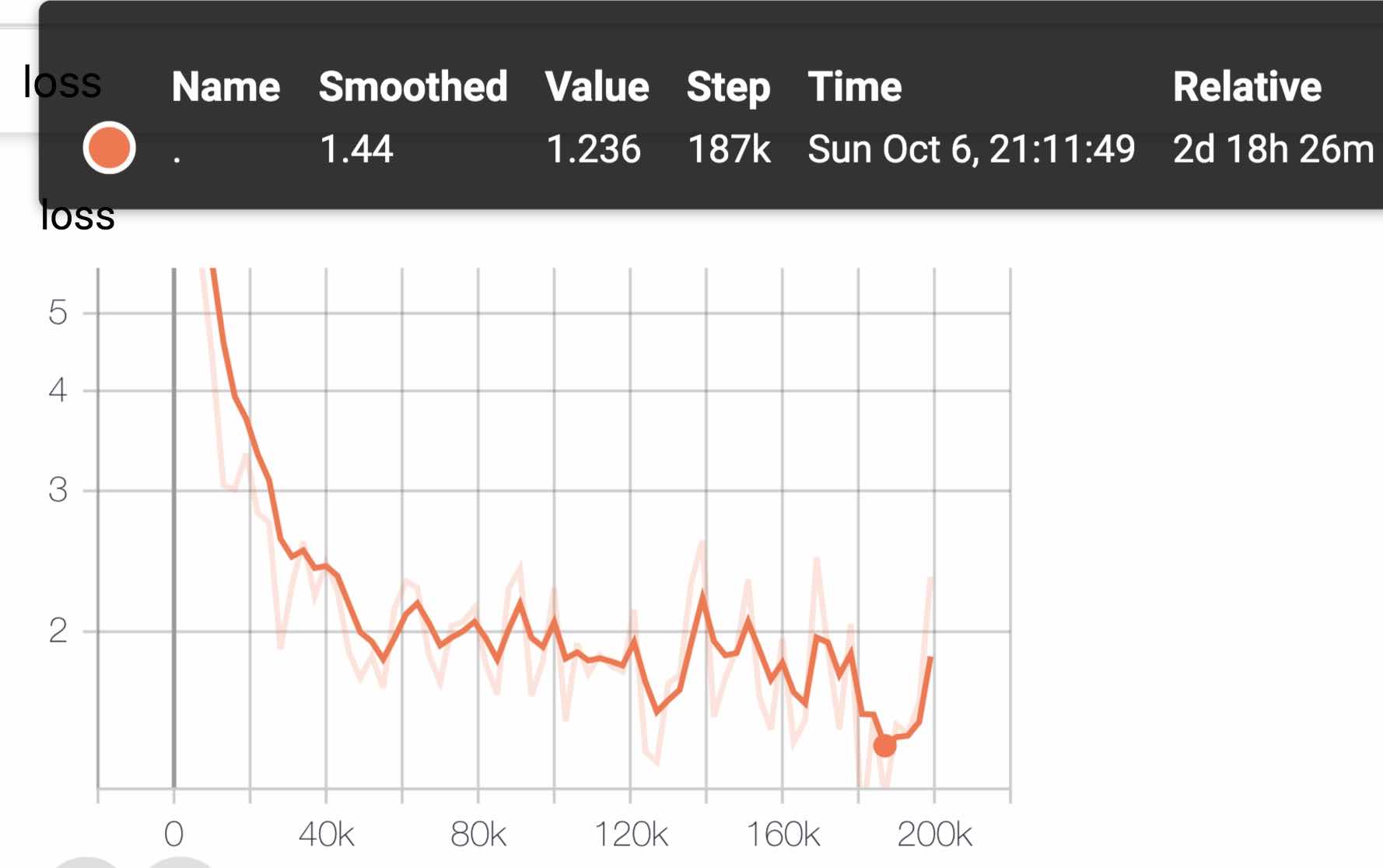
| แบบอย่าง | MLM Eval ACC | SOP Eval ACC | การฝึกอบรม (ชั่วโมง) | การประเมินการสูญเสีย |
|---|---|---|---|---|
| Albert_zh_base | 79.1% | 99.0% | 6h | 1.01 |
| Albert_zh_large | 80.9% | 98.6% | 22.5H | 0.93 |
| albert_zh_xlarge | - | - | 53H (ประมาณ) | - |
| albert_zh_xxlarge | - | - | 106h (ประมาณ) | - |
บันทึก:? จะถูกแทนที่เร็ว ๆ นี้
ทดสอบคะแนนการปรับปรุงหลักโดยการเรียกใช้คำสั่งต่อไปนี้รวมถึง แต่ไม่ จำกัด เพียงการแยกตัวประกอบของพารามิเตอร์การฝังคำพารามิเตอร์เวกเตอร์การแบ่งปันพารามิเตอร์ข้ามเลเยอร์งานต่อเนื่องของวรรค ฯลฯ
python test_changes.py
ที่นี่เราแนะนำการแปลงรูปแบบรูปแบบ TFLITE และการทดสอบประสิทธิภาพเป็นหลัก หลังจากแปลงเป็นโมเดล TFLITE สำหรับวิธีการใช้โมเดลทางด้านมือถือคุณสามารถอ้างถึงหน้าบทเรียนการพัฒนาแอปพลิเคชัน Android/iOS ที่สมบูรณ์แบบที่จัดทำโดย TFLITE หน้านี้มีสองกรณี Android สองกรณี: การจำแนกข้อความและข้อความตอบคำถาม
ต่อไปนี้เป็นตัวอย่างในการแนะนำการแปลงรูปแบบรูปแบบ TFLITE และการทดสอบประสิทธิภาพ:
ตรวจสอบให้แน่ใจว่ามี> = 1.14 1.x ติดตั้งเพื่อใช้เครื่องมือ freeze_graph เนื่องจากถูกลบออกจากการแจกแจง 2.x
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
เราจะใช้ตัวแปลง Tf-> tflite ทดลองใหม่ที่แจกจ่ายด้วยการสร้าง Tensorflow ยามค่ำคืน
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
ดูที่นี่สำหรับรายละเอียดเกี่ยวกับเครื่องมือมาตรฐานประสิทธิภาพใน tflite ตัวอย่างเช่น: หลังจากสร้างไบนารีเครื่องมือมาตรฐานสำหรับโทรศัพท์ Android ให้ทำสิ่งต่อไปนี้เพื่อรับทราบว่ารุ่น tflite ทำงานอย่างไรบนโทรศัพท์
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
บนโทรศัพท์ Android พร้อม SD845 SOC ของ Qualcomm ผ่านเครื่องมือมาตรฐานด้านบน ณ ปี 2019/11/01 เวลาแฝงการอนุมานคือ ~ 120ms w/ รุ่น TFLITE ที่แปลงโดยใช้ 4 เธรดบน CPU และการใช้หน่วยความจำคือ ~ 60MB สำหรับรุ่น โปรดทราบว่าประสิทธิภาพจะดีขึ้นต่อไปด้วยการเพิ่มประสิทธิภาพการใช้งาน TFLITE ในอนาคต
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
ใช้ albert_pytorch
Bert4keras ปรับให้เข้ากับอัลเบิร์ตซึ่งสามารถโหลดน้ำหนักของ Albert_ZH ได้สำเร็จ คุณจะต้องเพิ่ม albert = true ลงในฟังก์ชั่น load_pretrained_model
โหลดโมเดลที่ผ่านการฝึกอบรมล่วงหน้าด้วย bert4keras
bert-for-tf2
ฟังก์ชั่นคำอธิบาย: ผู้ใช้สามารถใช้ตัวอย่างนี้เพื่อทำความเข้าใจวิธีโหลดชุดการฝึกอบรมเพื่อให้ได้การตัดสินความคล้ายคลึงกันของข้อความสั้น ๆ ตามการป้อนข้อมูลของผู้ใช้ จากรหัสนี้คุณสามารถขยายโปรแกรมไปยังบริการพื้นหลังได้อย่างยืดหยุ่นหรือเพิ่มการจำแนกประเภทข้อความและตัวอย่างอื่น ๆ
รหัสที่เกี่ยวข้อง: ความคล้ายคลึงกัน py, args.py
ขั้นตอน:
1. ใช้โมเดลนี้เพื่อฝึกความคล้ายคลึงกันของข้อความและบันทึกไฟล์โมเดลลงในไดเรกทอรีที่เกี่ยวข้อง
2. ตามสถานการณ์จริงแก้ไขพารามิเตอร์ใน args.py พารามิเตอร์มีดังนี้:
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )โครงสร้างไฟล์ในตัวอย่างนี้คือ:
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. แก้ไขคำป้อนข้อมูลของผู้ใช้
เปิดความคล้ายคลึงกัน py และรหัสต่อไปนี้ที่ด้านล่าง:
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])โดยที่ sim.start_model () แสดงถึงรูปแบบการโหลดและอินพุตของ sim.predict_sentences เป็นอาร์เรย์ของ tuples และ tuple มีสององค์ประกอบประโยคที่ต้องตัดสินคล้ายกัน
4. เรียกใช้ไฟล์ Python: ความคล้ายคลึงกัน py
| ระบบ | ความยาว SEQ | ขนาดแบทช์สูงสุด |
|---|---|---|
albert-base | 64 | 64 |
| - | 128 | 32 |
| - | 256 | 16 |
| - | 320 | 14 |
| - | 384 | 12 |
| - | 512 | 6 |
albert-large | 64 | 12 |
| - | 128 | 6 |
| - | 256 | 2 |
| - | 320 | 1 |
| - | 384 | 0 |
| - | 512 | 0 |
albert-xlarge | - | - |
หากคุณมีคำถามใด ๆ คุณสามารถยกปัญหาหรือส่งอีเมลถึงฉัน: [email protected];
ขณะนี้วิธีใช้อัลเบิร์ตเวอร์ชัน Pytorch ยังไม่ชัดเจนหากคุณรู้วิธีทำเช่นนั้นเพียงส่งอีเมลถึงเราหรือเปิดปัญหา
นอกจากนี้คุณยังสามารถส่งคำขอดึงเพื่อรายงานประสิทธิภาพของคุณในงานของคุณหรือเพิ่มวิธีการเกี่ยวกับวิธีการโหลดโมเดลสำหรับ pytorch และอื่น ๆ
หากคุณมีแนวคิดในการสร้างโมเดลการฝึกอบรมก่อนการฝึกอบรมที่ดีที่สุดโปรดแจ้งให้เราทราบด้วย
Bright Liang Xu, Albert_zh, (2019), ที่เก็บ GitHub, https://github.com/brightmart/albert_zh
1. อัลเบิร์ต: Lite Bert สำหรับการเรียนรู้ด้วยตนเองเกี่ยวกับการเป็นตัวแทนภาษา
2. เบิร์ต: การฝึกอบรมหม้อแปลงสองทิศทางลึกเพื่อทำความเข้าใจภาษา
3. Spanbert: การปรับปรุงก่อนการฝึกอบรมโดยการเป็นตัวแทนและทำนายช่วง
4. Roberta: วิธีการฝึกอบรมเบิร์ตที่ได้รับการปรับปรุงอย่างดี
5. การเพิ่มประสิทธิภาพแบทช์ขนาดใหญ่สำหรับการเรียนรู้ลึก: การฝึกอบรมเบิร์ตใน 76 นาที (เนื้อแกะ)
6. Lamb Optimizer, TensorFlow เวอร์ชัน
7. โมเดลขนาดเล็กที่ผ่านการฝึกอบรมมาก่อนสามารถชนะได้ 13 งาน NLP และการเปลี่ยนแปลงครั้งสำคัญสามครั้งของอัลเบิร์ตถึงจุดสูงสุดของเกณฑ์มาตรฐานกาว
8. Albert_pytorch
9. โหลดอัลเบิร์ตกับเครส
10. โหลดอัลเบิร์ตด้วย tf2.0
11. repo ของอัลเบิร์ตจาก Google
12. การประเมินเกณฑ์มาตรฐานงานของจีน-จีน-จีน: มีหลายงานที่เปิดเผยต่อสาธารณะแบบจำลองพื้นฐานการประเมินอย่างกว้างขวางและการเปรียบเทียบผล


