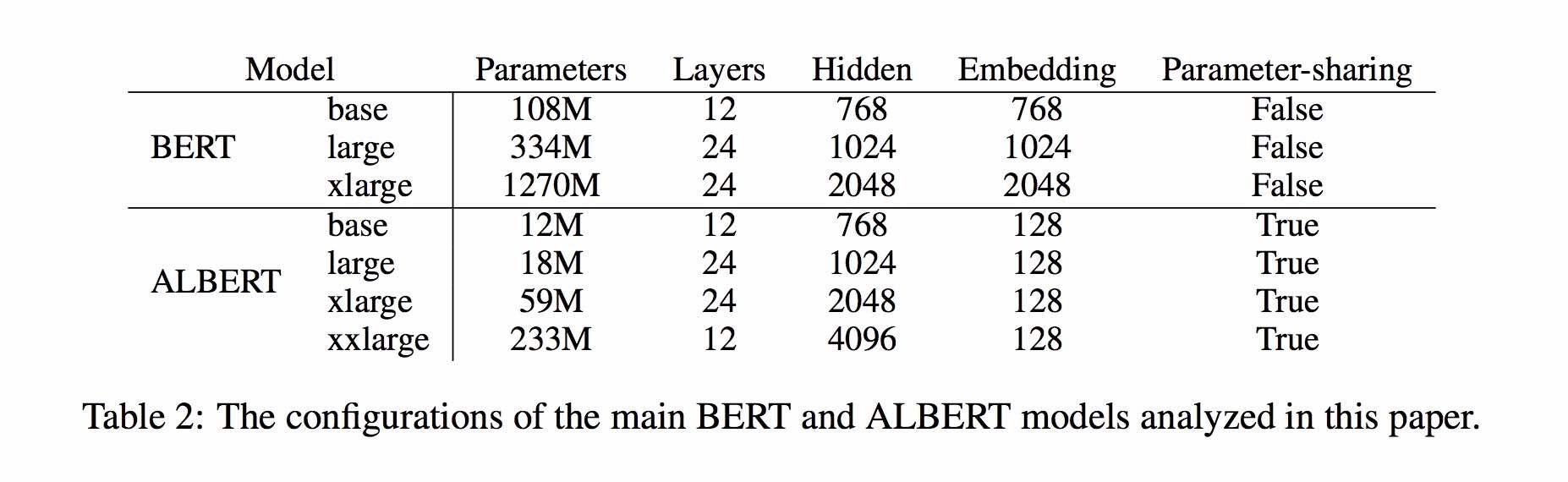
albert_zh
1.0.0
Une implémentation d'un lite bert pour les représentations de la langue d'apprentissage auto-supervisée avec TensorFlow
Albert est basé sur Bert, mais avec quelques améliorations. Il atteint la performance de pointe sur les références principales avec 30% de paramètres moins.
Pour Albert_Base_Zh, il n'a que dix paramètres pour pourcentage par rapport au modèle Bert d'origine, et la précision principale est conservée.
Différentes version du modèle pré-formé Albert pour chinois, y compris Tensorflow, Pytorch et Keras, est maintenant disponible.
Modèle Albert pré-formé sur un corpus chinois massif: moins de paramètres et de meilleurs résultats. Les petits modèles pré-formés peuvent également gagner 13 tâches NLP, et les trois principales transformations d'Albert atteignent le sommet de la référence de colle
Clueai Toolkit: trois lignes de code, personnalisez une API NLP en trois minutes (nul d'échantillon d'apprentissage)

Une comparaison détaillée des effets du modèle sur 10 ensembles de données, 9 modèles de base et une course en un clic, voir Clue Benchmark
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1. Albert_TINY_ZH, Albert_tiny_Zh (formation plus longtemps, accumulant 2 milliards d'échantillons à apprendre), la taille du fichier 16m, le paramètre est 4m
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. Albert_tiny_Google_ZH (apprentissage accumulatif de 1 milliard d'échantillons, version Google), taille du modèle 16m, les performances sont cohérentes avec Albert_tiny_Zh
1.2. albert_small_google_zh (apprentissage accumulatif de 1 milliard d'échantillons, version Google),
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
2. Albert_Large_Zh, quantité de paramètre, nombre de couches 24, la taille du fichier est de 64 m
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3. Albert_Base_Zh (150 millions d'instances supplémentaires ont été formées, c'est-à-dire 36K étapes * Batch_size 4096); Albert_Base_Zh (Small Model Experience Version), Quantité de paramètre 12m, nombre de couches 12, la taille est de 40m
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. Albert_xlarge_ZH_177K; Albert_xlARGE_ZH_183K (Priorité Try) Quantité, nombre de couches 24, la taille du fichier est de 230m
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
S'appuyant sur les transformateurs de HuggingFace 2.2.2, les modèles ci-dessus peuvent être facilement appelés.
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
La liste correspondante de MODEL_NAME est la suivante:
| Nom du modèle | Model_name |
|---|---|
| albert_tiny_google_zh | vide / albert_chinese_tiny |
| albert_small_google_zh | vide / albert_chinese_small |
| Albert_Base_Zh (de Google) | Noterful / Albert_Chinese_Base |
| Albert_Large_Zh (de Google) | Noterful / Albert_Chinese_Large |
| albert_xlarge_zh (de google) | vide / albert_chinese_xlarge |
| albert_xxlarge_zh (de google) | vide / albert_chinese_xxlarge |
Plus d'exemples d'utilisation d'Albert via Transformers
Exécutez la commande suivante Exécutez la commande suivante. Le projet a automatiquement un exemple de fichier texte (data / news_zh_1.txt)
bash create_pretrain_data.sh
Si vous avez de nombreux fichiers texte, vous pouvez générer plusieurs fichiers de formats spécifiques en transmettant les paramètres (tfrecords)
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
Utilisez Python3 + TensorFlow 1.x
par exemple TensorFlow 1.4 ou 1.5
Prenez à l'aide d'Albert_Base pour les tâches LCQMC comme exemple. La tâche LCQMC consiste à faire des prédictions de similitude de texte sur un ensemble de données de description familière.
Nous utiliserons un ensemble de données LCQMC pour un réglage fin, c'est un corpus de langue orale, il est utilisé pour former et prédire la similitude sémantique d'une paire de phrases.
Téléchargez l'ensemble de données LCQMC, qui contient des ensembles de formation, de validation et de tests. L'ensemble de formation contient 240 000 paires de phrases chinoises avec descriptions familières, avec des étiquettes de 1 ou 0. 1 est une similitude sémantique de phrase, et 0 est sémantique différente.
Faire un réglage fin sur l'ensemble de données LCQMC en exécutant la commande suivante:
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03: Ajoutez la version Google d'Albert_Small, Albert_tiny;
Ajoutez une méthode pour déployer ABLERT_TINY sur les appareils mobiles avec seulement 0,1 seconde du temps d'inférence pour la longueur de séquence 128, 60m mémoire ******
***** 2019-10-30: Ajoutez un guide simple sur la conversion du modèle en TensorFlow Lite pour le déploiement de bord *****
***** 2019-10-15: Albert_tiny_Zh, 10 fois rapide que la base de Bert pour la formation et l'inférence, la précision reste *****
***** 2019-10-07: Plus de modèles d'Albert *****
ajouter albert_xlarge_zh; albert_base_zh_additional_steps, formation avec plus d'instances
***** 2019-10-04: les versions Pytorch et Keras d'Albert ont été prises en charge *****
A.Convert à la version pytorch et effectuez vos tâches via Albert_Pytorch
B. Télécharger le modèle pré-formé avec des keras en utilisant une ligne de codes via Bert4keras
C.Utilisez Albert avec TensorFlow 2.0: Utilisez ou chargez le modèle pré-formé avec TF2.0 via Bert-for-TF2
Sortir Albert_xlarge le 6 octobre
***** 2019-10-02: Albert_Large_Zh, Albert_Base_Zh *****
ALBERT_BASE_ZH relued avec seulement 10% de paramètres de Bert_base, un petit modèle (40m) et une formation peuvent être très rapides.
Released Albert_Large_Zh avec seulement 16% de paramètres de Bert_base (64m)
***** 2019-09-28: codes et fonctions de test *****
Ajouter des codes et des fonctions de test pour trois changements principaux d'Albert de Bert
Le modèle Albert est une version améliorée de Bert. Contrairement à d'autres modèles récents de l'art, cette fois, c'est un petit modèle pré-formé, avec de meilleurs résultats et moins de paramètres.
Il a apporté trois modifications à Bert trois changements principaux d'Albert de Bert:
1.
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) Partage de paramètres de couche transversale
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) Tâche de continuité de paragraphe Perte de cohérence intersentente.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
Autres changements:
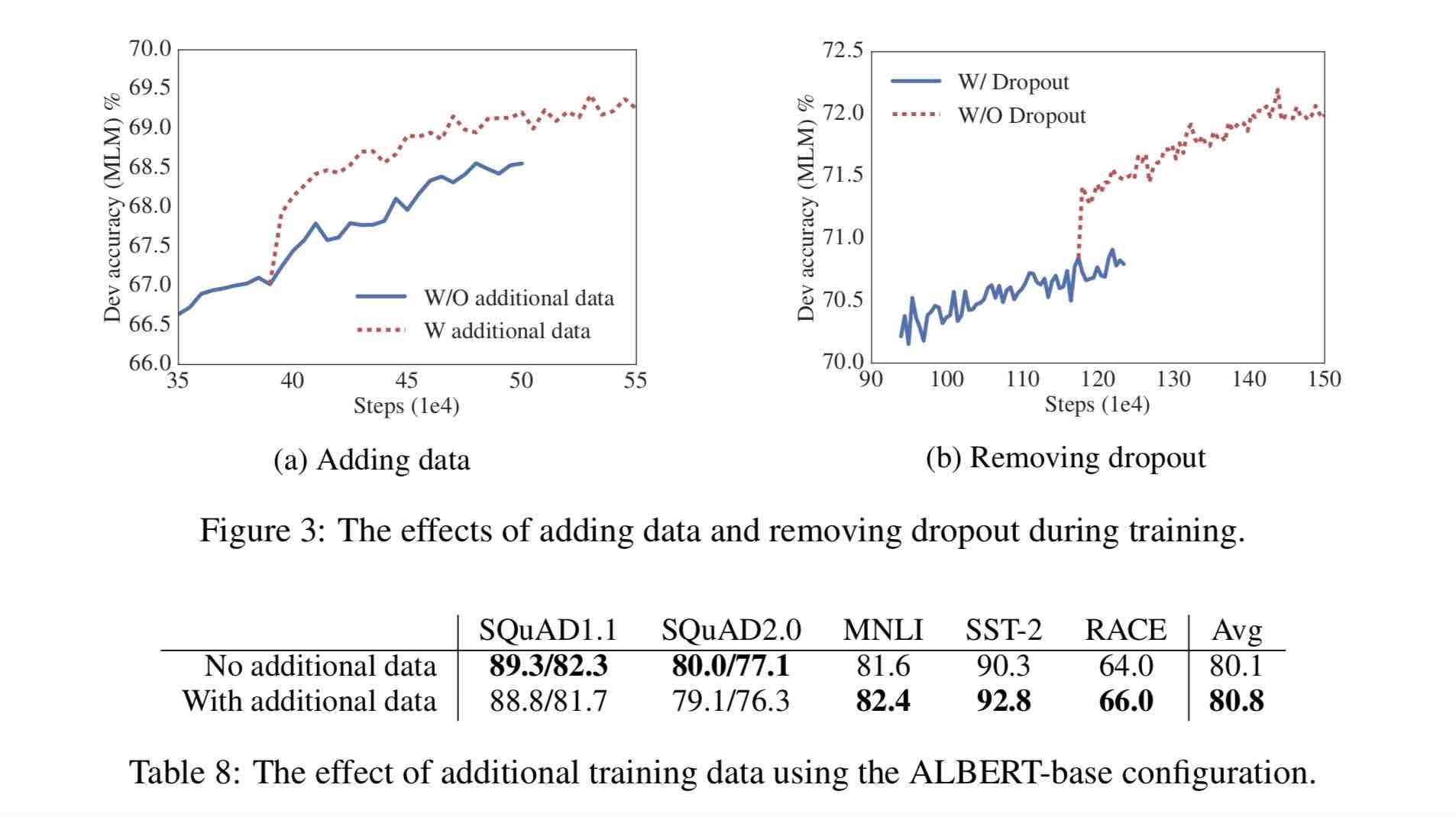
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
30G Corpus chinois, plus de 10 milliards de caractères chinois, dont plusieurs encyclopédies, des nouvelles et des communautés interactives.
La longueur de séquence pré-formée Sequence_Length est définie sur 512, le lot Batch_Size est 4096 et la formation génère 350 millions de données de formation (instance); Chaque modèle entraînera 125k étapes par défaut, et Albert_XXLarge sera formé plus longtemps.
À titre de comparaison, Roberta_ZH pré-formation a généré 250 millions de données de formation avec une longueur de séquence de 256. Étant donné que la pré-formation Albert_ZH génère plus de données de formation et utilise des durées de séquence plus longues,
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
La formation utilise TPU V3 POD, nous utilisons V3-256, qui contient 32 V3-8. Chaque machine V3-8 contient 128 g de mémoire vidéo.
| Modèle | Ensemble de développement (DEV) | Test Set (test) |
|---|---|---|
| Bert | 89.4 (88.4) | 86.9 (86.4) |
| Ernie | 89.8 (89,6) | 87.2 (87.0) |
| Bert-wwm | 89.4 (89.2) | 87.0 (86.8) |
| Bert-wwm- | - | - |
| Roberta-zh-base | 88.7 | 87.0 |
| Roberta-zh-gard | 89,9 (89,6) | 87.2 (86.7) |
| Roberta-Zh-Large (20w_steps) | 89.7 | 87.0 |
| Albert-zh-Tiny | - | 85.4 |
| Albert-zh-small | - | 86.0 |
| Albert-Zh-Small (Pytorch) | - | 86.8 |
| Albert-Zh-base-additional-36k-Steps | 87.8 | 86.3 |
| Albert-zh-base | 87.2 | 86.3 |
| Albert-grand | 88.7 | 87.1 |
| Albert-xlarge | 87.3 | 87.7 |
Remarque: je n'ai couru qu'albert-xlarge une fois, et l'effet peut être amélioré
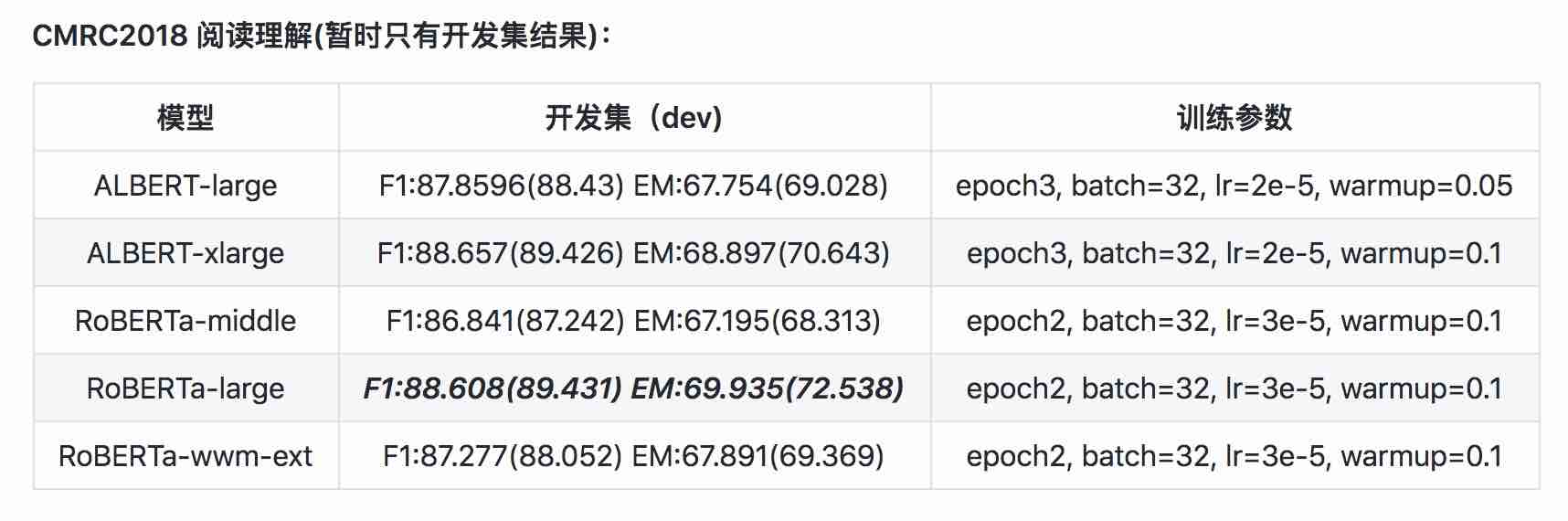
| Modèle | Ensemble de développement | Test de test |
|---|---|---|
| Bert | 77.8 (77,4) | 77,8 (77,5) |
| Ernie | 79.7 (79.4) | 78.6 (78.2) |
| Bert-wwm | 79.0 (78.4) | 78.2 (78.0) |
| Bert-wwm- | 79.4 (78,6) | 78.7 (78,3) |
| Xlnet | 79.2 | 78.7 |
| Roberta-zh-base | 79.8 | 78.8 |
| Roberta-zh-gard | 80.2 (80.0) | 79,9 (79,5) |
| ALBERT-BASE | 77.0 | 77.1 |
| Albert-grand | 78.0 | 77.5 |
| Albert-xlarge | ? | ? |
Remarque: Bert-WWM-Ext. Xlnet vient d'ici; Roberta-Zh-Base fait référence au modèle chinois Roberta à 12 couches
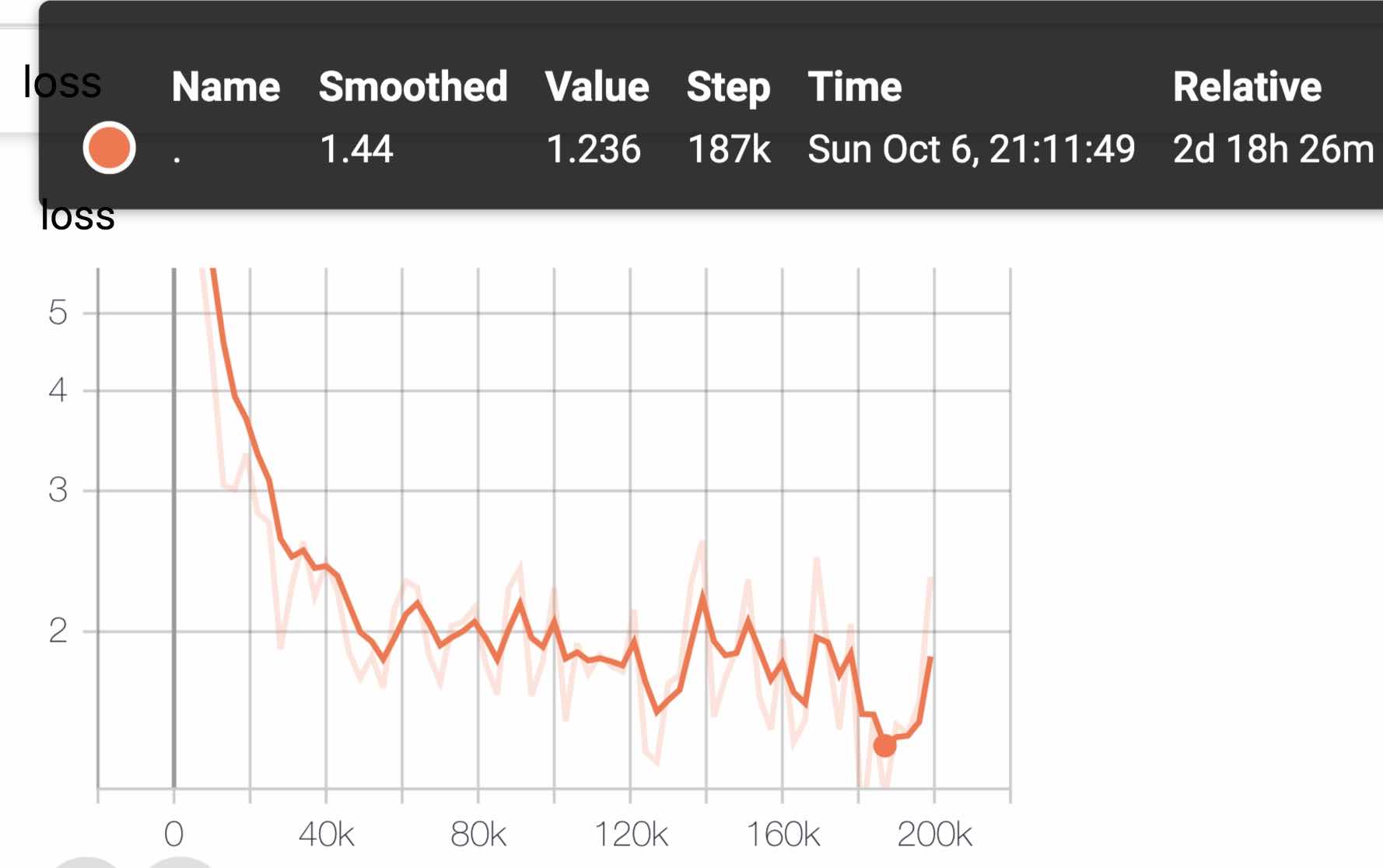
| Modèle | MLM EVC ACC | SOP EVC ACC | Formation (heures) | Perte Eval |
|---|---|---|---|---|
| albert_zh_base | 79,1% | 99,0% | 6h | 1.01 |
| albert_zh_large | 80,9% | 98,6% | 22.5h | 0,93 |
| albert_zh_xlarge | ? | ? | 53h (estimé) | ? |
| albert_zh_xxlarge | ? | ? | 106h (estimé) | ? |
Note:? Sera remplacé bientôt
Testez les principaux points d'amélioration en exécutant les commandes suivantes, y compris, mais sans s'y limiter, la factorisation des paramètres vectoriels intégrés de mots, le partage des paramètres de couche transversale, les tâches de continuité des paragraphes, etc.
python test_changes.py
Ici, nous introduisons principalement la conversion du format de modèle TFLITE et les tests de performances. Après avoir converti au modèle TFLITE, pour utiliser le modèle du côté mobile, vous pouvez vous référer à la page Tutoriel complète de cas de développement d'applications Android / iOS fournie par TFLITE. Cette page contient actuellement deux cas Android: classification du texte et questions / réponses de texte.
Ce qui suit est un exemple pour introduire la conversion du format du modèle TFLITE et les tests de performances:
Assurez-vous d'avoir> = 1.14 1.x installé pour utiliser l'outil Freeze_Graph lorsqu'il est supprimé de la distribution 2.x
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
Nous allons utiliser le nouveau convertisseur TF-> Tflite expérimental qui est distribué avec la construction de TensorFlow nocturne.
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
Voir ici pour plus de détails sur les outils de référence Performance dans TFLITE. Par exemple: après avoir construit le binaire de l'outil de référence pour un téléphone Android, procédez comme suit pour avoir une idée de la façon dont le modèle Tflite fonctionne sur le téléphone
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
Sur un téléphone Android avec SOC SD845 de Qualcomm, via l'outil de référence ci-dessus, à partir de 2019/11/01, la latence d'inférence est de ~ 120 ms avec ce modèle TFLITE converti en utilisant 4 threads sur le processeur, et l'utilisation de la mémoire est ~ 60 Mo pour le modèle pendant l'inférence. Remarque Les performances s'amélioreront davantage avec les futures optimisations de l'implémentation TFLITE.
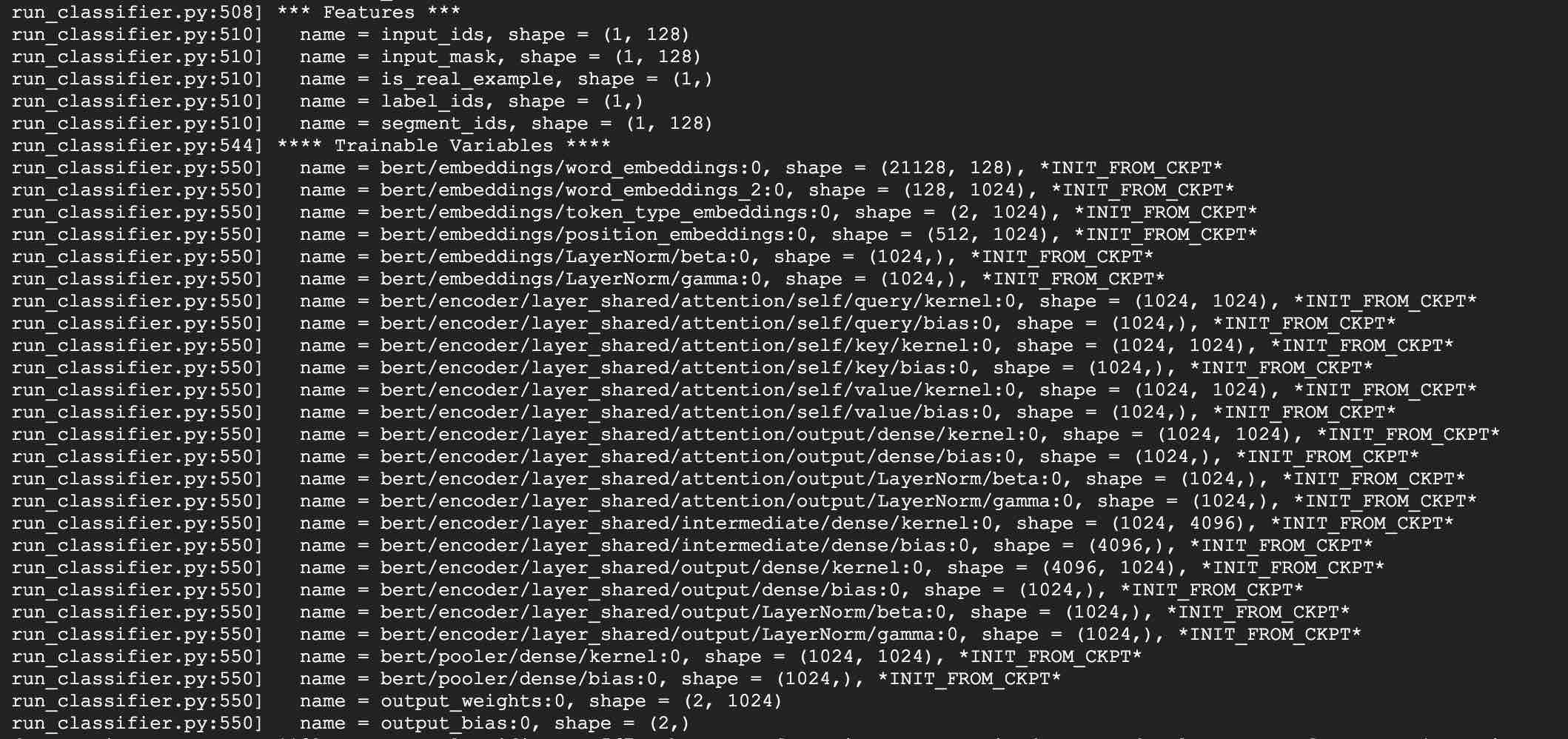
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
Utilisation d'Albert_Pytorch
Bert4keras s'adapte à Albert, qui peut charger avec succès le poids d'Albert_Zh. Il vous suffit d'ajouter Albert = TRUE à la fonction LOAD_PRETRENED_MODEL.
Chargez le modèle pré-formé avec Bert4keras
bert-pour-tf2
Description de la fonction: Les utilisateurs peuvent utiliser cet exemple pour comprendre comment charger l'ensemble de formation pour obtenir un court jugement de similitude de texte en fonction de l'entrée des utilisateurs. Sur la base de ce code, vous pouvez étendre le programme de manière flexible aux services d'arrière-plan ou ajouter une classification de texte et d'autres exemples.
Code impliqué: similitude.py, args.py
étape:
1. Utilisez ce modèle pour former la similitude du texte et enregistrer le fichier de modèle avec le répertoire correspondant.
2. Selon la situation réelle, modifiez les paramètres dans args.py. Les paramètres sont les suivants:
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )La structure des fichiers dans cet exemple est:
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. Modifier le mot d'entrée de l'utilisateur
Ouvrir la similitude.py et le code suivant en bas:
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])Lorsque sim.start_model () représente le modèle de chargement, et l'entrée de sim.predict_sences est un tableau de tuples, et le tuple contient deux éléments, des phrases qui doivent être jugées similaires.
4. Exécuter le fichier python: similitude.py
| Système | Longueur de seq | Taille du lot maximum |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - | - |
Si vous avez une question, vous pouvez soulever un problème ou m'envoyer un e-mail: [email protected];
Actuellement, comment utiliser la version Pytorch d'Albert n'est pas encore claire, si vous savez comment le faire, envoyez-nous un e-mail ou ouvrez un problème.
Vous pouvez également envoyer une demande Pull pour signaler vos performances sur votre tâche ou ajouter des méthodes sur la façon de charger des modèles pour Pytorch, etc.
Si vous avez des idées pour générer le meilleur modèle chinois de pré-formation de performance, veuillez également me le faire savoir.
Bright Liang Xu, Albert_Zh, (2019), Github Repository, https://github.com/brightmart/albert_zh
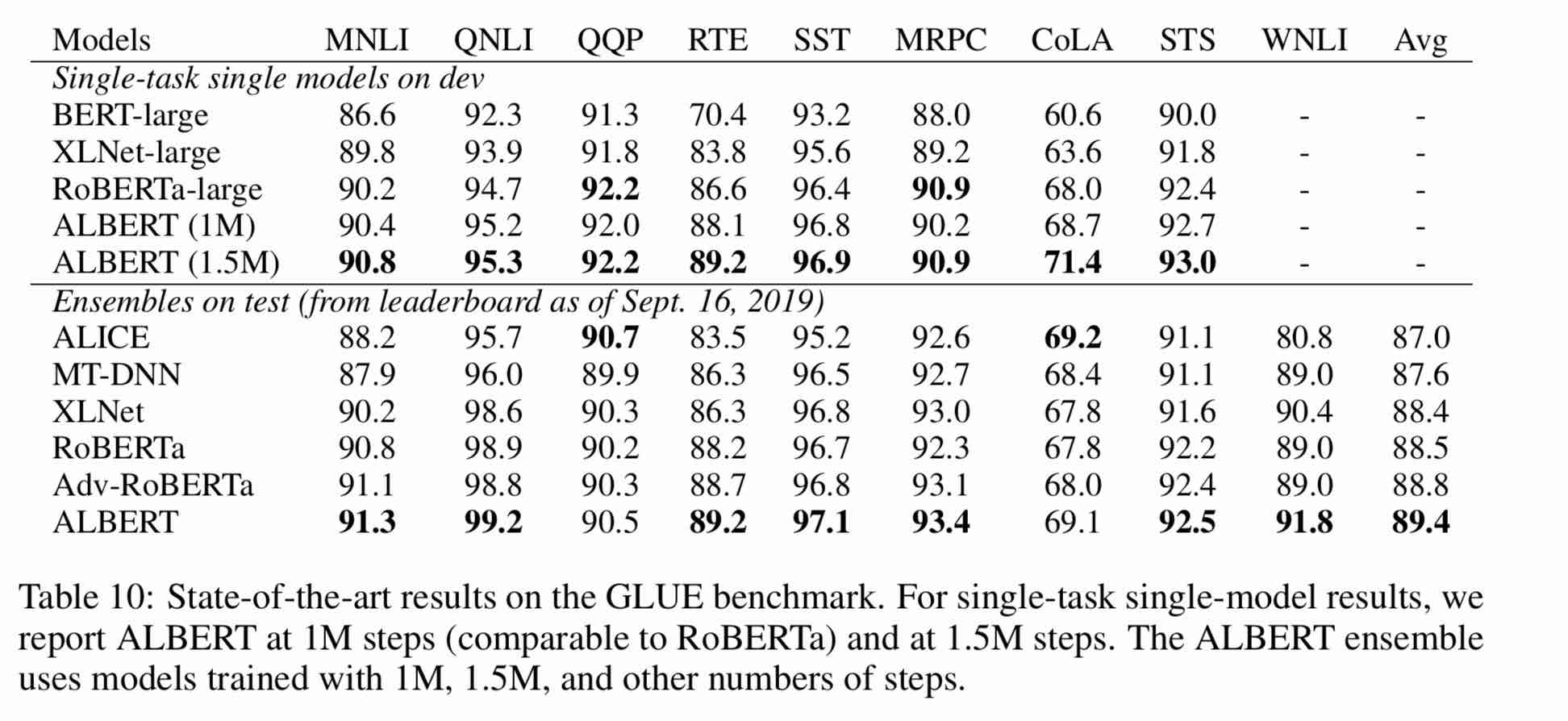
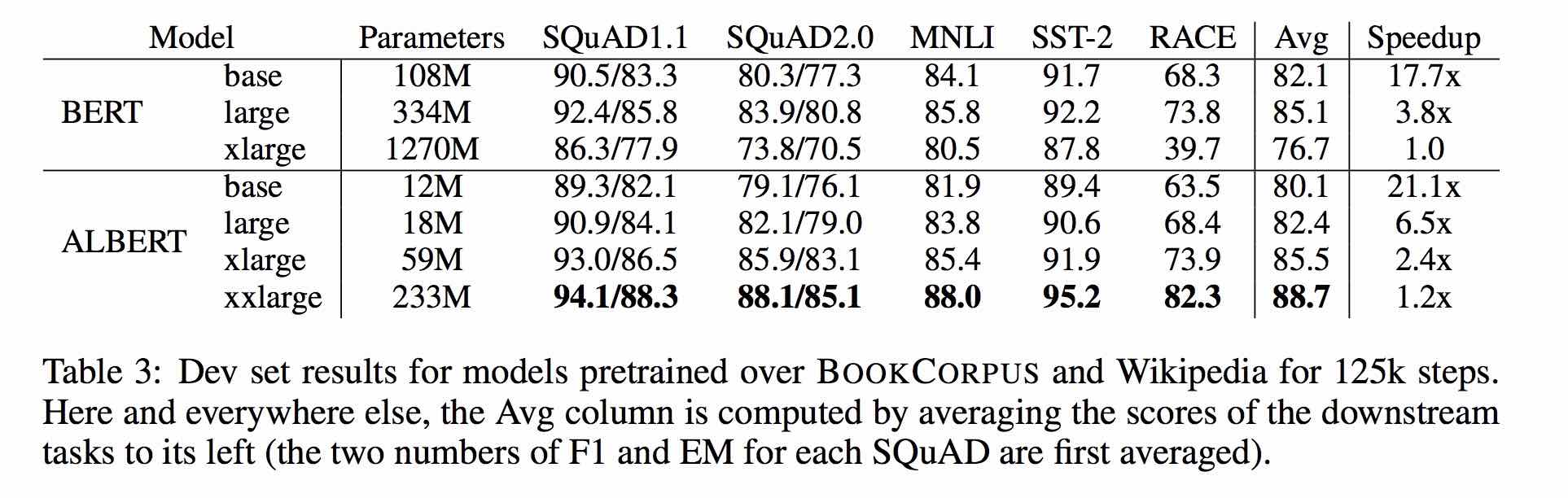
1. Albert: A Lite Bert pour l'apprentissage auto-supervisé des représentations de la langue
2. Bert: pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage
3. Spanbert: Amélioration de la pré-formation en représentant et prédisant les portées
4. Roberta: une approche de pré-formation de Bert optimisée à optimisation robuste
5. Optimisation des lots importants pour l'apprentissage en profondeur: formation Bert en 76 minutes (agneau)
6. Optimiseur d'agneau, version tensorflow
7. Les petits modèles pré-formés peuvent également gagner 13 tâches NLP, et les trois transformations majeures d'Albert atteignent le sommet de la référence à colle
8. Albert_Pytorch
9. Chargez Albert avec Keras
10. Chargez Albert avec TF2.0
11. Repo d'Albert de Google
12. Évaluation de référence des tâches de ChineseGlue-Chinese: Tâches multiples accessibles au public, modèles de référence, évaluation approfondie et comparaison des effets


