albert_zh
1.0.0
Uma implementação de um Lite Bert para representações de idiomas de aprendizagem auto-supervisionadas com Tensorflow
Albert é baseado em Bert, mas com algumas melhorias. Ele atinge a performance de última geração nos principais benchmarks com 30% de parâmetros menos.
Para Albert_base_zh, possui apenas dez parâmetros percentuais em comparação do modelo BERT original e a precisão principal é mantida.
Versão diferente do modelo pré-treinado de Albert para chinês, incluindo Tensorflow, Pytorch e Keras, está disponível agora.
Modelo Albert pré-treinado em corpus chinês maciço: menos parâmetros e melhores resultados. Os pequenos modelos pré-treinados também podem ganhar 13 tarefas de NLP, e as três principais transformações de Albert atingem o topo da referência de cola
CLUEAI Toolkit: Três linhas de código, personalize uma API NLP em três minutos (aprendizado de amostra zero)

Uma comparação detalhada dos efeitos do modelo em 10 conjuntos de dados, 9 modelos de linha de base e execução com um clique, veja a referência da pista
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1. Albert_tiny_zh, albert_tiny_zh (treinando mais, acumulando 2 bilhões de amostras para aprender), tamanho do arquivo 16m, o parâmetro é 4m
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. Albert_tiny_google_zh (aprendizado acumulativo de 1 bilhão de amostras, versão do Google), tamanho do modelo 16m, o desempenho é consistente com albert_tiny_zh
1.2. Albert_small_google_zh (aprendizado acumulativo de 1 bilhão de amostras, versão do Google),
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
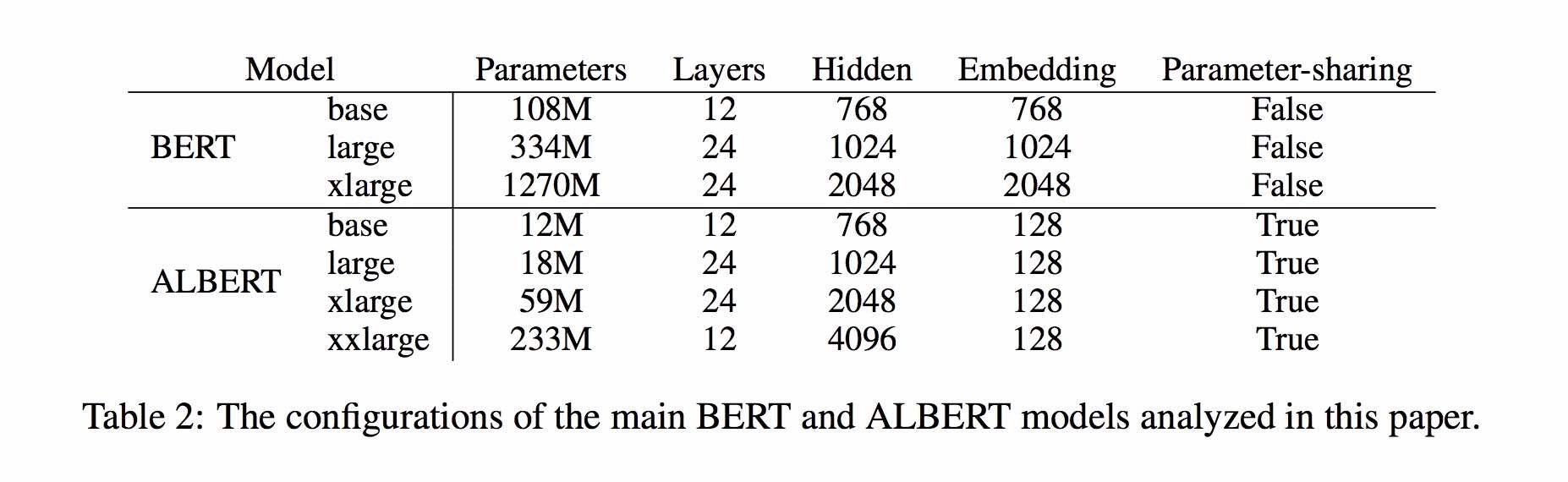
2. Albert_large_zh, quantidade de parâmetros, número de camadas 24, tamanho do arquivo é 64m
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3. Albert_base_zh (mais 150 milhões de instâncias foram treinadas, ou seja, 36k etapas * Batch_size 4096); ALBERT_BASE_ZH (Versão de Experiência em Modelo Pequeno), Quantidade de Parâmetro 12m, Número de Camadas 12, Tamanho é 40m
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. Albert_xlarge_zh_177k; ALBERT_XLARGE_ZH_183K (TRIMENTO PRIORIDADE) Quantidade de parâmetro, número de camadas 24, o tamanho do arquivo é 230M
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
Baseando-se em Huggingface-Transformers 2.2.2, os modelos acima podem ser facilmente chamados.
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
A lista correspondente de MODEL_NAME é a seguinte:
| Nome do modelo | Model_name |
|---|---|
| Albert_tiny_google_zh | anulado/albert_chinese_tiny |
| ALBERT_SMALL_GOOGLE_ZH | angustiante/albert_chinese_small |
| Albert_base_zh (do Google) | anulado/albert_chinese_base |
| Albert_large_zh (do Google) | anulado/albert_chinese_large |
| Albert_xlarge_zh (do Google) | Vazio/albert_chinese_xlarge |
| Albert_xxlarge_zh (do Google) | anulado/albert_chinese_xxlarge |
Mais exemplos de uso de Albert através de Transformers
Execute o seguinte comando execute o seguinte comando. O projeto tem um exemplo de texto de texto (dados/news_zh_1.txt)
bash create_pretrain_data.sh
Se você tiver muitos arquivos de texto, poderá gerar vários arquivos de formatos específicos, passando em parâmetros (TFRecords)
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
Use python3 + tensorflow 1.x
Por exemplo, Tensorflow 1.4 ou 1.5
Tome usando as tarefas Albert_base para LCQMC como exemplo. A tarefa LCQMC é fazer previsões de similaridade de texto em um conjunto de dados de descrição coloquial.
Usaremos o conjunto de dados LCQMC para ajuste fino, é corpus de linguagem oral, é usado para treinar e prever a similaridade semântica de um par de frases.
Faça o download do conjunto de dados LCQMC, que contém conjuntos de treinamento, validação e teste. O conjunto de treinamento contém 240.000 pares de frases chinesas com descrições coloquiais, com rótulos de 1 ou 0. 1 é a similaridade semântica da sentença e 0 é semântica diferente.
Faça o ajuste fino no conjunto de dados LCQMC executando o seguinte comando:
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03: Adicione a versão do Google de Albert_small, Albert_tiny;
Adicione o método para implantar o ablert_tiny em dispositivos móveis com apenas 0,1 segundo tempo de inferência para o comprimento da sequência 128, 60m de memória ********
******* 2019-10-30: Adicione um guia simples sobre a conversão do modelo em Tensorflow Lite para implantação de borda *****
******* 2019-10-15: Albert_tiny_zh, 10 vezes rápido que a base de Bert para treinamento e inferência, a precisão permanece *****
***** 07-10-07: Mais modelos de Albert *****
adicione albert_xlarge_zh; Albert_base_zh_additional_steps, treinando com mais instâncias
******* 2019-10-04: As versões Pytorch e Keras de Albert foram suportadas *****
A.Convert para a versão Pytorch e faça suas tarefas através de Albert_pytorch
B.Load modelo pré-treinado com Keras usando uma linha de códigos através do Bert4keras
C.Use Albert com Tensorflow 2.0: Use ou carregue o modelo pré-treinado com TF2.0 através do Bert-For-Tf2
Lançamento Albert_xlarge no dia 6 de outubro
***** 02-10-02: Albert_large_zh, Albert_base_zh *****
RELESED ALBERT_BASE_ZH Com apenas 10% de parâmetros de bert_base, um modelo pequeno (40m) e treinamento pode ser muito rápido.
Relassado Albert_large_ZH com apenas 16% de parâmetros de bert_base (64m)
***** 2019-09-28: Códigos e funções de teste *******
Adicione códigos e funções de teste para três principais mudanças de Albert de Bert
O modelo Albert é uma versão aprimorada do Bert. Ao contrário de outros modelos recentes da arte, desta vez é um modelo pequeno pré-treinado, com melhores resultados e menos parâmetros.
Ele fez três alterações para Bert três principais mudanças de Albert de Bert:
1) Parametrização incorporada fatorizada de parâmetros vetoriais de incorporação de palavras
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) compartilhamento de parâmetros de camada cruzada
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) Tarefa de continuidade do parágrafo Perda de coerência da inter-sentença.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
Outras mudanças:
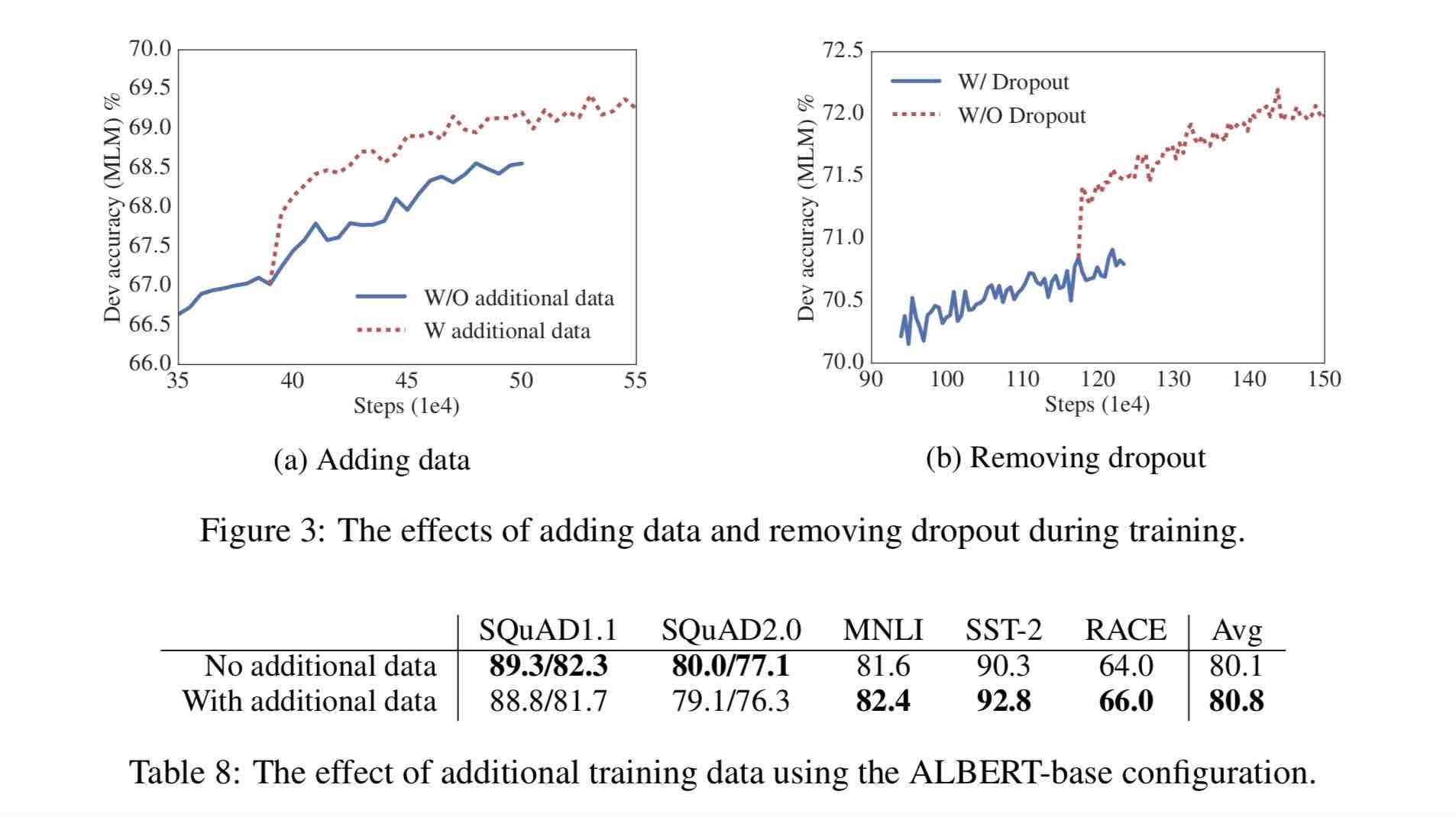
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
30g corpus chinês, mais de 10 bilhões de caracteres chineses, incluindo múltiplas enciclopédias, notícias e comunidades interativas.
O comprimento da sequência pré-treinado sequence_length é definido como 512, o lote em lote é 4096 e o treinamento gera 350 milhões de dados de treinamento (instância); Cada modelo treinará 125k etapas por padrão, e Albert_xxlarge será treinado por mais tempo.
Para comparação, Roberta_ZH pré-treinamento gerou 250 milhões de dados de treinamento com um comprimento de sequência de 256. Como o pré-treinamento de Albert_ZH gera mais dados de treinamento e usa comprimentos de sequência mais longos,
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
O treinamento usa o POD TPU V3, estamos usando a V3-256, que contém 32 V3-8S. Cada máquina V3-8 contém 128g de memória de vídeo.
| Modelo | Conjunto de Desenvolvimento (Dev) | Conjunto de testes (teste) |
|---|---|---|
| Bert | 89,4 (88,4) | 86,9 (86,4) |
| Ernie | 89,8 (89,6) | 87.2 (87,0) |
| Bert-wwm | 89.4 (89,2) | 87.0 (86,8) |
| Bert-wwm-ext | - | - |
| Roberta-Zh-Base | 88.7 | 87.0 |
| Roberta-Zh-Large | 89,9 (89,6) | 87.2 (86,7) |
| Roberta-Zh-Large (20W_STEPS) | 89.7 | 87.0 |
| Albert-Zh Tiny | - | 85.4 |
| Albert-Zh-Small | - | 86.0 |
| Albert-Zh-Small (Pytorch) | - | 86.8 |
| Albert-Zh-Base-Addicional-36K-Steps | 87.8 | 86.3 |
| Albert-Zh-Base | 87.2 | 86.3 |
| Albert-Large | 88.7 | 87.1 |
| Albert-Xlarge | 87.3 | 87.7 |
Nota: Eu só corri Albert-Xlarge uma vez, e o efeito pode ser melhorado
| Modelo | Conjunto de desenvolvimento | Conjunto de testes |
|---|---|---|
| Bert | 77,8 (77.4) | 77,8 (77,5) |
| Ernie | 79,7 (79,4) | 78.6 (78.2) |
| Bert-wwm | 79,0 (78.4) | 78.2 (78.0) |
| Bert-wwm-ext | 79.4 (78.6) | 78.7 (78.3) |
| Xlnet | 79.2 | 78.7 |
| Roberta-Zh-Base | 79.8 | 78.8 |
| Roberta-Zh-Large | 80,2 (80,0) | 79,9 (79,5) |
| Albert-Base | 77.0 | 77.1 |
| Albert-Large | 78.0 | 77.5 |
| Albert-Xlarge | ? | ? |
Nota: Bert-Wwm-EXT vem daqui; XLNET vem daqui; Roberta-Zh-Base refere-se ao modelo chinês Roberta de 12 camadas
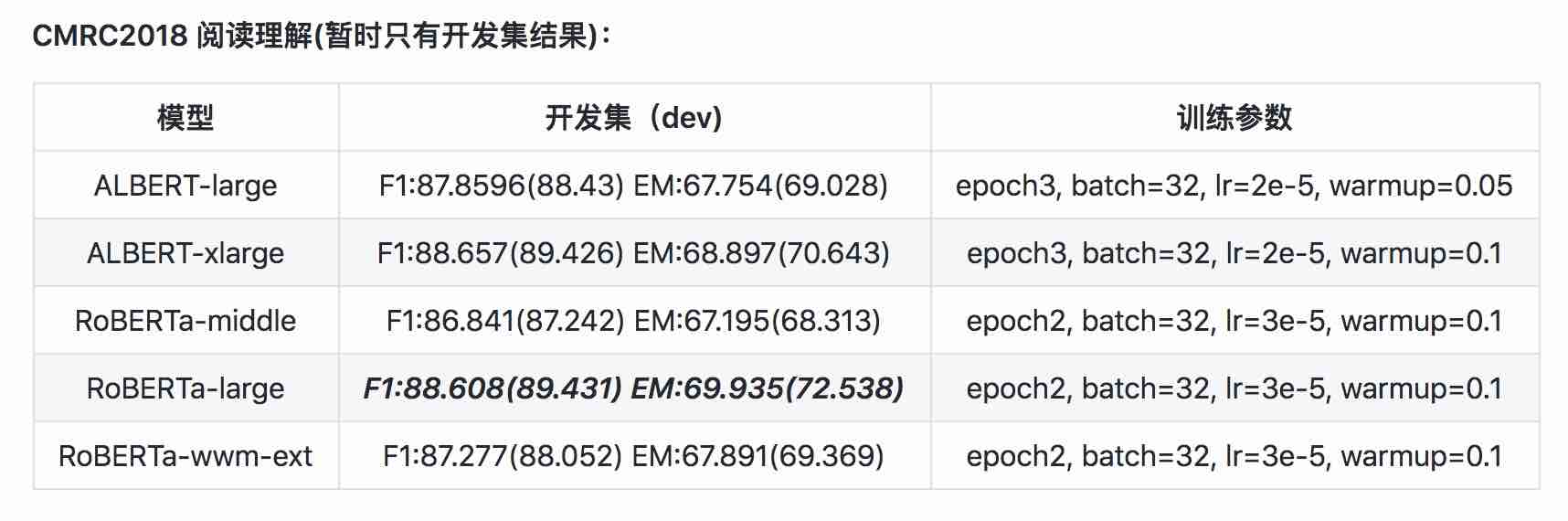
| Modelo | MLM Eval ACC | SOP avaliar acc | Treinamento (horas) | Perda Eval |
|---|---|---|---|---|
| ALBERT_ZH_BASE | 79,1% | 99,0% | 6h | 1.01 |
| ALBERT_ZH_LARGE | 80,9% | 98,6% | 22.5h | 0,93 |
| ALBERT_ZH_XLARGE | ? | ? | 53h (estimado) | ? |
| ALBERT_ZH_XXLARGE | ? | ? | 106h (estimado) | ? |
Observação:? Será substituído em breve
Teste os principais pontos de melhoria, executando os seguintes comandos, incluindo, entre outros, a fatoração de parâmetros vetoriais de incorporação de palavras, compartilhamento de parâmetros de camada cruzada, tarefas de continuidade de parágrafos, etc.
python test_changes.py
Aqui, apresentamos principalmente a conversão de formato de modelo Tflite e testes de desempenho. Depois de converter para o modelo Tflite, para usar o modelo no lado móvel, você pode consultar a página Tutorial completa do Caso de Desenvolvimento de Aplicativos Android/IOS fornecida pelo Tflite. Atualmente, esta página contém dois casos do Android: classificação de texto e perguntas e respostas de texto.
A seguir, é apresentado um exemplo para introduzir a conversão de formato de modelo Tflite e testes de desempenho:
Certifique -se de ter> = 1,14 1.x instalado para usar a ferramenta Freeze_graph, conforme é removido da distribuição 2.x
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
Vamos usar o novo conversor experimental TF-> tflite que é distribuído com a construção noturna do TensorFlow.
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
Veja aqui para obter detalhes sobre as ferramentas de referência de desempenho no Tflite. Por exemplo: depois de construir o binário da ferramenta de referência para um telefone Android, faça o seguinte para ter uma idéia de como o modelo Tflite se executa no telefone
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
Em um telefone Android com o SOC SD845 da Qualcomm, através da ferramenta de benchmark acima, a partir de 2019/11/01, a latência de inferência é de ~ 120ms com esse modelo Tflite convertido usando 4 threads na CPU e o uso da memória é ~ 60 MB para o modelo durante a conferência. Observe que o desempenho melhorará ainda mais com futuras otimizações de implementação do Tflite.
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
Usando Albert_pytorch
O Bert4keras se adapta a Albert, que pode carregar com sucesso o peso de Albert_zh. Você só precisa adicionar Albert = true à função load_pretringen_model.
Carregar modelo pré-treinado com Bert4keras
bert-for-tf2
Função Descrição: os usuários podem usar este exemplo para entender como carregar o conjunto de treinamento para obter um julgamento de similaridade de texto curto com base na entrada do usuário. Com base nesse código, você pode expandir o programa de forma flexível para serviços em segundo plano ou adicionar classificação de texto e outros exemplos.
Código envolvido: similarity.py, args.py
etapa:
1. Use este modelo para treinar a similaridade do texto e salvar o arquivo de modelo no diretório correspondente.
2. De acordo com a situação real, modifique os parâmetros em args.py. Os parâmetros são os seguintes:
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )A estrutura do arquivo neste exemplo é:
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. Modifique a palavra de entrada do usuário
Abra a similaridade.py e o código a seguir na parte inferior:
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])Onde o SIM.START_MODEL () representa o modelo de carregamento, e a entrada de sim.predict_sentenc é uma matriz de tuplas, e a tupla contém dois elementos, sentenças que precisam ser julgadas semelhantes.
4. Execute o arquivo python: similarity.py
| Sistema | Comprimento seq | Tamanho máximo em lote |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - | - |
Se você tiver alguma dúvida, pode levantar um problema ou enviar -me um e -mail: [email protected];
Atualmente, como usar a versão Pytorch do Albert ainda não está claro, se você souber fazer isso, basta enviar um email ou abrir um problema.
Você também pode enviar uma solicitação de puxar para relatar seu desempenho em sua tarefa ou adicionar métodos sobre como carregar modelos para Pytorch e assim por diante.
Se você tiver idéias para gerar o melhor modelo chinês pré-treinamento de melhor desempenho, entre em contato também.
Bright Liang Xu, Albert_ZH, (2019), Repositório Github, https://github.com/brightmart/albert_zh
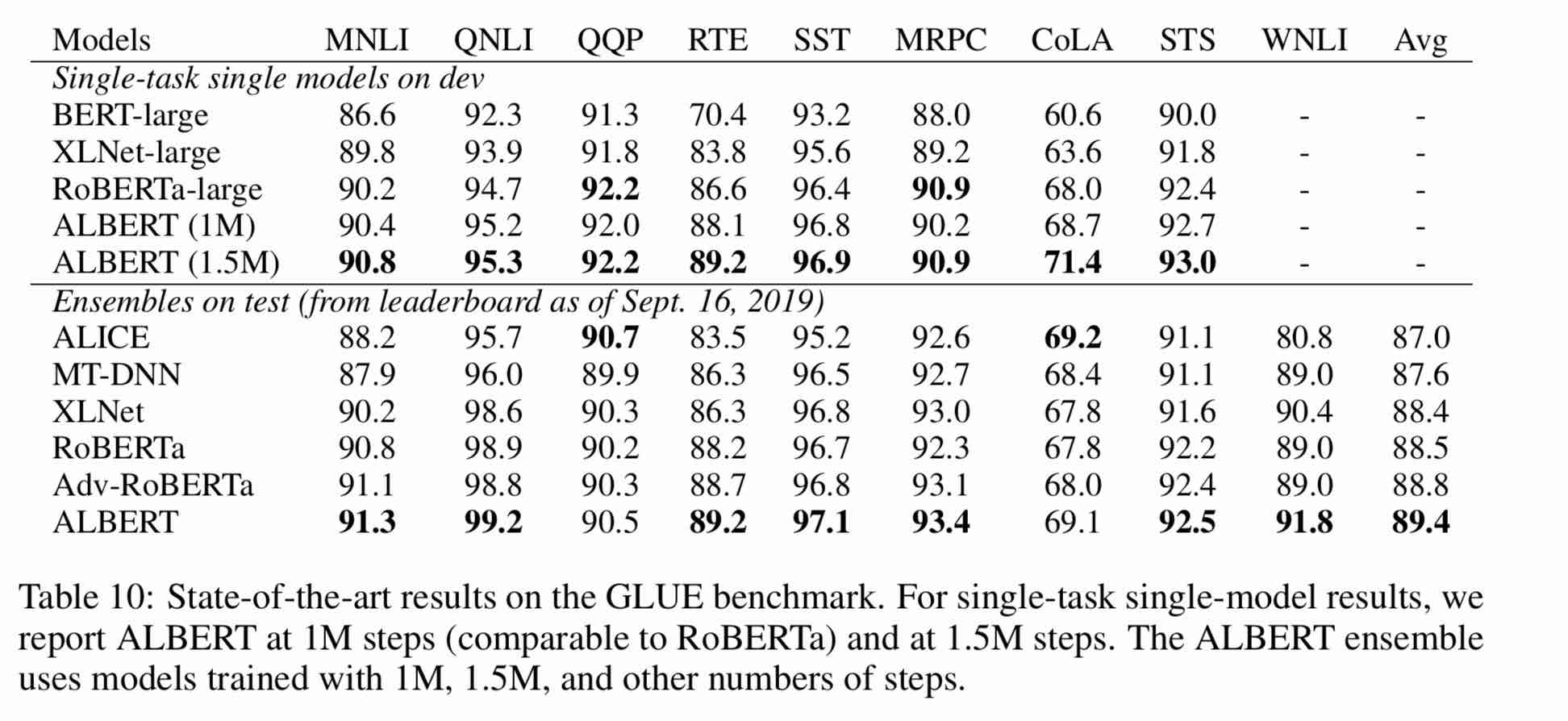
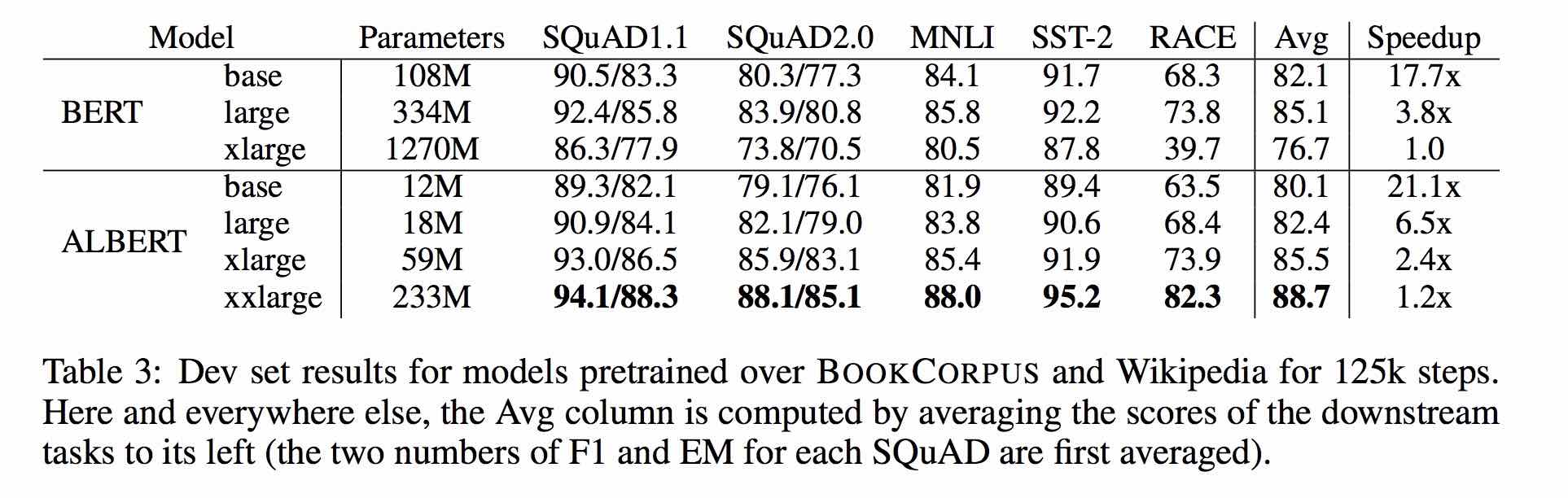
1. Albert: Um Lite Bert para o aprendizado auto-supervisionado de representações de idiomas
2. Bert: pré-treinamento de transformadores bidirecionais profundos para entendimento de idiomas
3. Spanbert: Melhorando o pré-treinamento, representando e prevendo vãos
4. Roberta: Uma abordagem de pré -treinamento de Bert robustamente otimizada
5. Grande otimização em lote para aprendizado profundo: treinamento Bert em 76 minutos (cordeiro)
6. Otimizador de cordeiro, versão tensorflow
7. Modelos pequenos pré-treinados também podem ganhar 13 tarefas de NLP, e as três principais transformações de Albert atingem o topo da referência de cola
8. Albert_pytorch
9. Carregue Albert com Keras
10. Carregue Albert com TF2.0
11. Repo de Albert do Google
12. Avaliação de benchmark de tarefas chinesas chinesas: várias tarefas publicamente disponíveis, modelos de linha de base, avaliação extensiva e comparação de efeitos


