albert_zh
1.0.0
Tensorflow를 사용한 자기 감독 학습 언어 표현을위한 라이트 버트 구현
Albert는 Bert를 기반으로하지만 약간의 개선이 있습니다. 30% 매개 변수로 메인 벤치 마크에서 최첨단 공연을 달성합니다.
Albert_base_zh의 경우 원래 Bert 모델과 비교하여 10 % 매개 변수 만 있으며 주요 정확도는 유지됩니다.
Tensorflow, Pytorch 및 Keras를 포함한 Albert의 미리 훈련 된 모델의 다양한 버전을 현재 사용할 수 있습니다.
대규모 중국 코퍼스에서 미리 훈련 된 Albert 모델 : 매개 변수가 적고 결과가 더 적습니다. 미리 훈련 된 작은 모델은 13 개의 NLP 작업을 이길 수 있으며 Albert의 3 가지 주요 변환은 접착제 벤치 마크의 최상위에 도달합니다.
Clueai 툴킷 : 3 줄의 코드 라인, 3 분 안에 NLP API를 사용자 정의합니다 (제로 샘플 학습)

10 개의 데이터 세트, 9 개의 기준선 모델 및 원 클릭 실행에 대한 모델 효과에 대한 자세한 비교, Clue Benchmark 참조
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
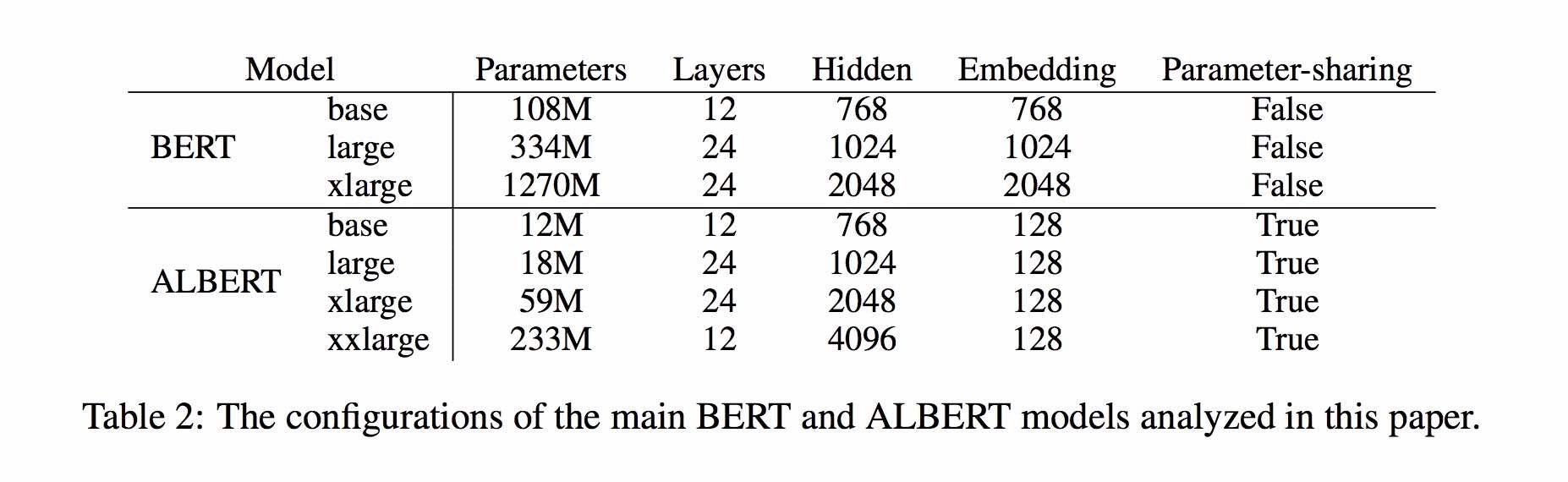
1. Albert_tiny_ZH, Albert_tiny_ZH (더 긴 훈련, 학습 할 20 억 샘플 축적), 파일 크기 16m, 매개 변수는 4m입니다.
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. albert_tiny_google_zh (10 억 샘플의 축적 학습, Google 버전), 모델 크기 16m, 성능은 Albert_tiny_zh와 일치합니다.
1.2. Albert_small_google_ZH (10 억 샘플의 축적 학습, Google 버전),
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
2. Albert_large_ZH, 매개 변수 수량, 레이어 수 24, 파일 크기는 64m입니다.
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3. ALBERT_BASE_ZH (추가 1 억 5 천만 인스턴스가 훈련되었습니다. 즉, 36K 단계 * Batch_size 4096); albert_base_zh (작은 모델 경험 버전), 매개 변수 수량 12m, 레이어 수 12, 크기는 40m입니다.
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. Albert_xlarge_ZH_177K; Albert_xlarge_zh_183k (우선 순위 시도) 매개 변수 수량, 레이어 수 24, 파일 크기는 230m입니다.
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
Huggingface-Transformers 2.2.2에 의존하면 위의 모델을 쉽게 호출 할 수 있습니다.
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
MODEL_NAME 의 해당 목록은 다음과 같습니다.
| 모델 이름 | model_name |
|---|---|
| albert_tiny_google_zh | voidful/albert_chinese_tiny |
| albert_small_google_zh | voidful/albert_chinese_small |
| Albert_base_ZH (Google에서) | voidful/albert_chinese_base |
| Albert_large_ZH (Google에서) | voidful/albert_chinese_large |
| Albert_Xlarge_ZH (Google에서) | voidful/albert_chinese_xlarge |
| albert_xxlarge_zh (Google에서) | voidful/albert_chinese_xxlarge |
변압기를 통해 Albert를 사용하는 더 많은 예
다음 명령 실행 실행 다음 명령을 실행하십시오. 프로젝트에는 자동으로 예제 텍스트 파일이 있습니다 (data/news_zh_1.txt)
bash create_pretrain_data.sh
텍스트 파일이 많으면 매개 변수 (tfrecords)를 전달하여 특정 형식의 여러 파일을 생성 할 수 있습니다.
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
Python3 + Tensorflow 1.x를 사용하십시오
예를 들어 Tensorflow 1.4 또는 1.5
LCQMC 작업에 Albert_Base를 사용하여 예를 들어 보겠습니다. LCQMC 작업은 구어체 설명 데이터 세트에서 텍스트 유사성 예측을 만드는 것입니다.
우리는 미세 조정을 위해 LCQMC 데이터 세트를 사용하고, 구두 언어 코퍼스이며, 한 쌍의 문장의 의미 론적 유사성을 훈련시키고 예측하는 데 사용됩니다.
교육, 검증 및 테스트 세트가 포함 된 LCQMC 데이터 세트를 다운로드하십시오. 훈련 세트에는 구어체 설명이있는 240,000 개의 중국 문장 쌍이 포함되어 있으며, 1 또는 0.1의 레이블은 문장 의미 론적 유사성이며 0은 의미 론적 다릅니다.
다음 명령을 실행하여 LCQMC 데이터 세트에서 미세 조정을 수행하십시오.
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03 : Albert_Small, Albert_tiny의 Google 버전 추가;
시퀀스 길이 128, 60m 메모리에 대한 0.1 초 추론 시간으로 모바일 장치에 ABLERT_TINY를 배포하는 방법 추가 ******
***** 2019-10-30 : 모델 배치를 위해 모델을 Tensorflow Lite로 변환하는 것에 대한 간단한 안내서 추가 *****
***** 2019-10-15 : Albert_tiny_ZH, 훈련 및 추론을위한 Bert 기반보다 10 배 빠른 속도로 정확도가 남아 있습니다 *****
***** 2019-10-07 : Albert의 더 많은 모델 *****
Albert_xlarge_zh를 추가하십시오. Albert_base_zh_additional_steps, 더 많은 인스턴스를 가진 훈련
***** 2019-10-04 : Albert의 Pytorch 및 Keras 버전이 지원되었습니다 *****
A.Convert to Pytorch 버전으로 Albert_PyTorch를 통해 작업을 수행하십시오.
B. Bert4keras를 통해 한 줄의 코드를 사용하여 Keras를 사용하여 미리 훈련 된 모델로드
C. Tensorflow 2.0을 사용하여 Albert를 사용하십시오 : TF2.0을 통해 Bert-for-TF2를 통해 미리 훈련 된 모델 사용 또는로드
10 월 6 일에 Albert_Xlarge를 출시합니다
***** 2019-10-02 : Albert_large_ZH, Albert_Base_ZH *****
BERT_BASE의 10% 매개 변수만으로 Albert_Base_ZH와 관련하여 작은 모델 (40m) 및 훈련이 매우 빠를 수 있습니다.
BERT_BASE (64M)의 16% 매개 변수로 Albert_Large_ZH를 상환했습니다.
***** 2019-09-28 : 코드 및 테스트 기능 *****
Bert에서 Albert의 세 가지 주요 변경 사항에 대한 코드 및 테스트 기능 추가
Albert 모델은 개선 된 Bert 버전입니다. 다른 최근의 예술 모델과 달리, 이번에는 미리 훈련 된 작은 모델이며 더 나은 결과와 더 적은 매개 변수가 있습니다.
Bert에서 Albert의 3 가지 주요 변화를 Bert에 세 가지 변경했습니다.
1) 단어 임베딩 벡터 파라미터의 인자 화 된 임베디드 매개 변수화
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) 크로스 레이어 매개 변수 공유
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) 단락 연속성 작업 간 중단 일관성 손실.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
기타 변경 사항 :
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
여러 백과 사전, 뉴스 및 대화 형 커뮤니티를 포함하여 30 억 개 이상의 한국자.
미리 훈련 된 시퀀스 길이 시퀀스 _length는 512로 설정되고, 배치 Batch_size는 4096이며, 훈련은 3 억 5 천만 개의 교육 데이터 (인스턴스)를 생성합니다. 각 모델은 기본적으로 125k 단계를 훈련 시키며 Albert_xxlarge는 더 오래 훈련됩니다.
비교를 위해 Roberta_ZH 사전 훈련은 시퀀스 길이가 256 인 2 억 5 천만 교육 데이터를 생성했습니다. Albert_ZH 사전 훈련은 더 많은 훈련 데이터를 생성하고 더 긴 시퀀스 길이를 사용하기 때문에,
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
교육을 사용하여 TPU V3 POD를 사용합니다. 32 V3-8을 포함하는 V3-256을 사용하고 있습니다. 각 V3-8 기계에는 128g의 비디오 메모리가 포함되어 있습니다.
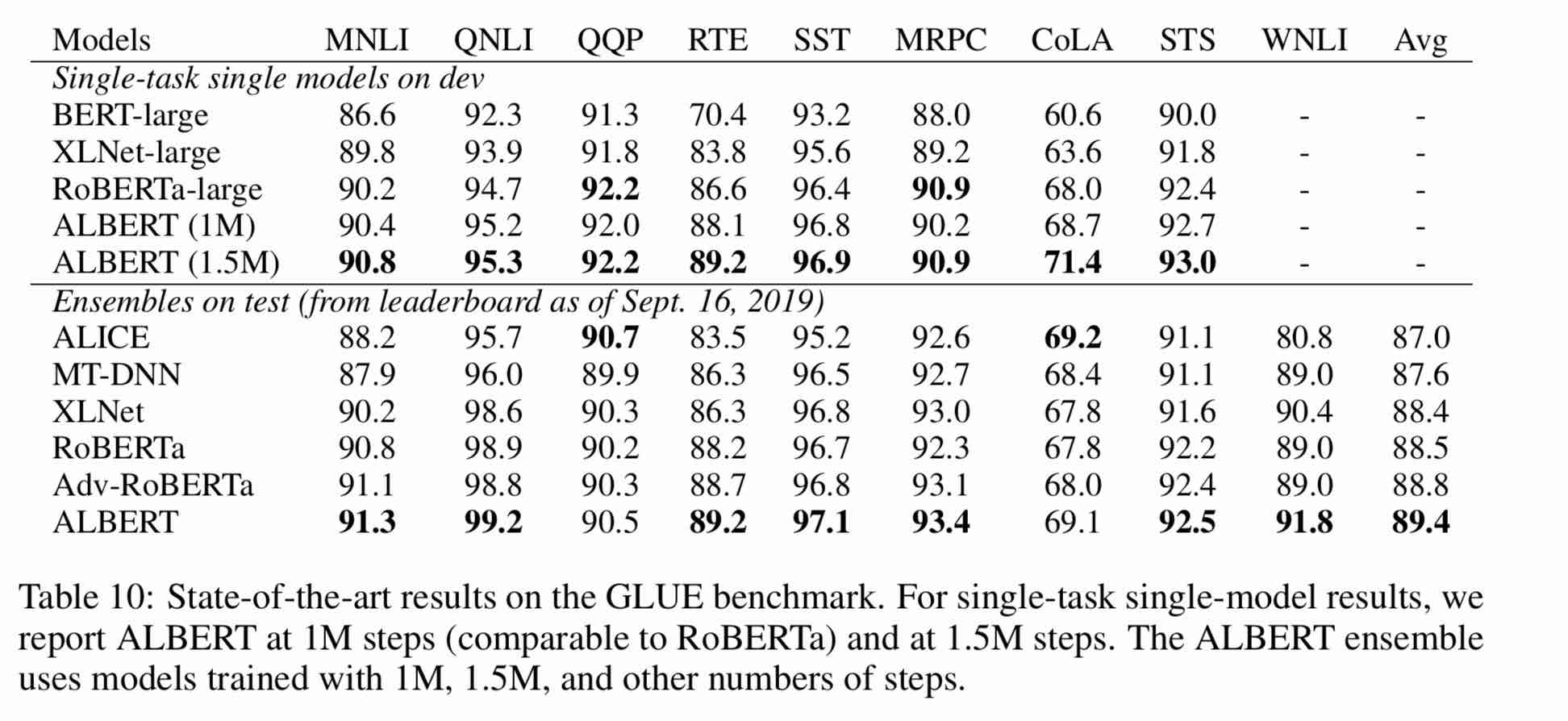
| 모델 | 개발 세트 (DEV) | 테스트 세트 (테스트) |
|---|---|---|
| 버트 | 89.4 (88.4) | 86.9 (86.4) |
| 어니 | 89.8 (89.6) | 87.2 (87.0) |
| Bert-WWM | 89.4 (89.2) | 87.0 (86.8) |
| Bert-WWM-EXT | - | - |
| Roberta-Zh-Base | 88.7 | 87.0 |
| Roberta-Zh-Large | 89.9 (89.6) | 87.2 (86.7) |
| Roberta-Zh-Large (20w_steps) | 89.7 | 87.0 |
| Albert-Zh-Tiny | - | 85.4 |
| Albert-Zh Small | - | 86.0 |
| Albert-Zh-Small (Pytorch) | - | 86.8 |
| Albert-Zh-Base-Additional-36K 단계 | 87.8 | 86.3 |
| Albert-Zh-Base | 87.2 | 86.3 |
| 앨버트-레이지 | 88.7 | 87.1 |
| Albert-Xlarge | 87.3 | 87.7 |
참고 : Albert-Xlarge 만 한 번만 운영했는데 그 효과가 향상 될 수 있습니다.
| 모델 | 개발 세트 | 테스트 세트 |
|---|---|---|
| 버트 | 77.8 (77.4) | 77.8 (77.5) |
| 어니 | 79.7 (79.4) | 78.6 (78.2) |
| Bert-WWM | 79.0 (78.4) | 78.2 (78.0) |
| Bert-WWM-EXT | 79.4 (78.6) | 78.7 (78.3) |
| xlnet | 79.2 | 78.7 |
| Roberta-Zh-Base | 79.8 | 78.8 |
| Roberta-Zh-Large | 80.2 (80.0) | 79.9 (79.5) |
| 앨버트베이스 | 77.0 | 77.1 |
| 앨버트-레이지 | 78.0 | 77.5 |
| Albert-Xlarge | ? | ? |
참고 : Bert-WWM-EXT는 여기에서 나옵니다. xlnet은 여기에서 온다. Roberta-Zh-Base는 12 층 Roberta Chinese 모델을 말합니다
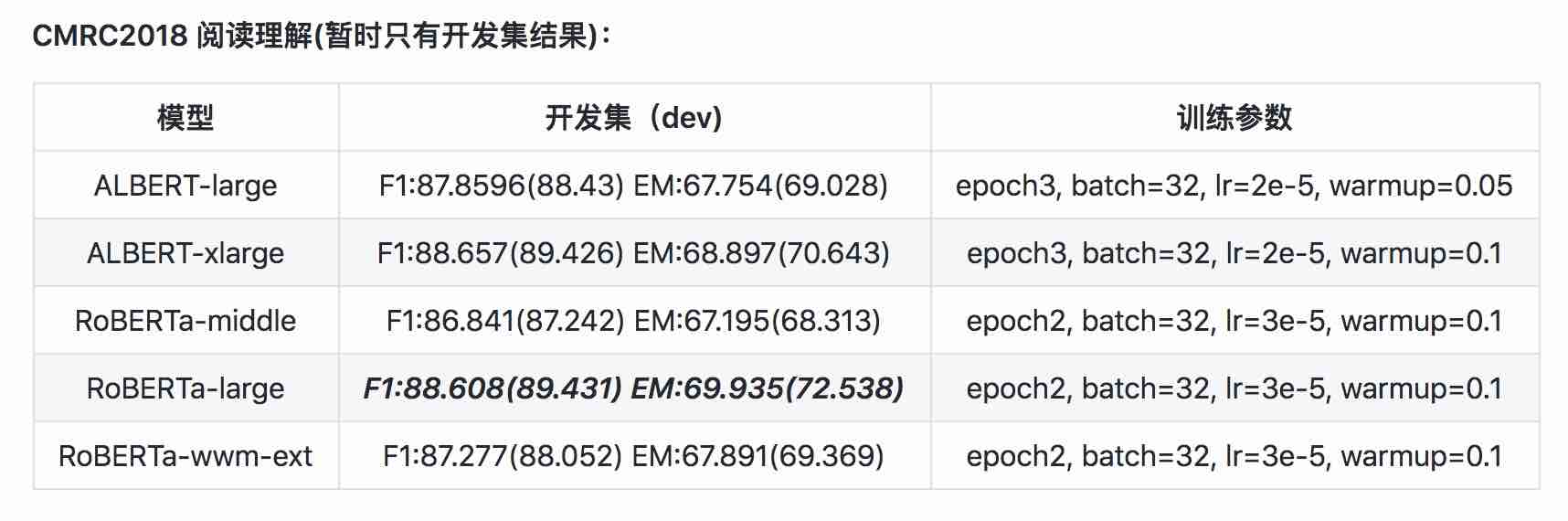
| 모델 | MLM Eval Acc | SOP Eval Acc | 훈련 (시간) | 손실 평가 |
|---|---|---|---|---|
| Albert_ZH_Base | 79.1% | 99.0% | 6H | 1.01 |
| Albert_ZH_LARGE | 80.9% | 98.6% | 22.5h | 0.93 |
| Albert_ZH_XLARGE | ? | ? | 53H (추정) | ? |
| Albert_ZH_XXLARGE | ? | ? | 106H (추정) | ? |
메모:? 곧 교체 될 예정입니다
단어 임베딩 벡터 매개 변수의 인수화, 크로스 레이어 매개 변수 공유, 단락 연속성 작업 등을 포함하여 다음 명령을 실행하여 주요 개선 사항을 테스트하십시오.
python test_changes.py
여기서 우리는 주로 tflite 모델 형식 변환 및 성능 테스트를 소개합니다. TFLITE 모델로 변환 한 후 모바일 측면의 모델을 사용하는 방법은 TFLITE에서 제공하는 완전한 Android/iOS 응용 프로그램 개발 사례 자습서 페이지를 참조 할 수 있습니다. 이 페이지에는 현재 텍스트 분류 및 텍스트 Q & A의 두 가지 Android 사례가 포함되어 있습니다.
다음은 Tflite 모델 형식 변환 및 성능 테스트를 소개하는 예입니다.
freeze_graph 도구가 2.x 배포에서 제거 될 때 Freeze_graph 도구를 사용하도록 설치된> = 1.14 1.x가 있는지 확인하십시오.
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
우리는 Tensorflow Nightly 빌드와 함께 배포 된 새로운 실험 TF-> Tflite 변환기를 사용할 것입니다.
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
TFLITE의 성능 벤치 마크 도구에 대한 자세한 내용은 여기를 참조하십시오. 예를 들어 : Android 폰용 벤치 마크 도구 바이너리를 구축 한 후 다음을 수행하여 TFLITE 모델이 전화에서 어떻게 수행되는지에 대한 아이디어를 얻으십시오.
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
Qualcomm의 SD845 SOC가있는 안드로이드 폰에서 위의 벤치 마크 도구를 통해 2019/11/01 기준으로 추론 대기 시간은 CPU에서 4 개의 스레드를 사용 하여이 변환 된 TFLITE 모델이없는 ~ 120ms이며, 메모리 사용량은 추론 중 모델의 경우 ~ 60MB입니다. 향후 TFLITE 구현 최적화로 성능이 더욱 향상됩니다.
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
Albert_pytorch 사용
Bert4keras는 Albert에 적응하여 Albert_ZH의 무게를 성공적으로로드 할 수 있습니다. load_pretraind_model 함수에 albert = true 만 추가하면됩니다.
Bert4keras로 미리 훈련 된 모델을로드하십시오
Bert-for-TF2
기능 설명 : 사용자는이 예제를 사용하여 사용자 입력을 기반으로 짧은 텍스트 유사성 판단을 달성하기 위해 교육 세트를로드하는 방법을 이해할 수 있습니다. 이 코드를 기반으로 프로그램을 배경 서비스로 유연하게 확장하거나 텍스트 분류 및 기타 예제를 추가 할 수 있습니다.
관련된 코드 : 유사성 .py, args.py
단계:
1.이 모델을 사용하여 텍스트 유사성을 교육하고 모델 파일을 해당 디렉토리에 저장하십시오.
2. 실제 상황에 따라 args.py에서 매개 변수를 수정하십시오. 매개 변수는 다음과 같습니다.
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )이 예제의 파일 구조는 다음과 같습니다.
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. 사용자 입력 단어를 수정하십시오
Open emiiletity.py 및 하단의 다음 코드 :
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])여기서 sim.start_model ()은 로딩 모델을 나타내고 sim.predict_sentences의 입력은 튜플의 배열이며 튜플에는 두 가지 요소가 포함되어 있습니다.
4. Python 파일 실행 : 유사성 .py
| 체계 | 서열 길이 | 최대 배치 크기 |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - | - |
질문이 있으시면 문제를 제기하거나 이메일을 보낼 수 있습니다 : [email protected];
현재 Pytorch 버전의 Albert를 사용하는 방법은 아직 명확하지 않습니다.이를 수행하는 방법을 알고 있다면 이메일을 보내거나 문제를여십시오.
또한 풀 요청을 보내서 작업에 대한 성능을보고하거나 Pytorch의 모델을로드하는 방법에 대한 메소드를 추가 할 수 있습니다.
최고의 성능 사전 훈련 중국 모델을 생성하기위한 아이디어가 있다면 알려주십시오.
Bright Liang XU, Albert_ZH, (2019), Github Repository, https://github.com/brightmart/albert_zh
1. Albert : 언어 표현에 대한 자기 감독 학습을위한 라이트 버트
2. Bert : 언어 이해를위한 깊은 양방향 변압기의 사전 훈련
3. Spanbert : 스팬을 나타내고 예측하여 사전 훈련 개선
4. Roberta : 강력하게 최적화 된 Bert 프리 트레인 접근법
5. 딥 러닝을위한 대형 배치 최적화 : 76 분 안에 훈련 버트 (Lamb)
6. Lamb Optimizer, Tensorflow 버전
7. 미리 훈련 된 소규모 모델도 13 개의 NLP 작업을 이길 수 있으며 Albert의 3 가지 주요 변환은 접착제 벤치 마크의 최상위에 도달합니다.
8. Albert_pytorch
9. Keras와 함께 Albert를로드하십시오
10. TF2.0으로 Albert를로드하십시오
11. Google에서 Albert의 Repo
12. ChineseGlue-Chinese 작업 벤치 마크 평가 : 공개적으로 이용 가능한 여러 작업, 기준선 모델, 광범위한 평가 및 효과 비교


