albert_zh
1.0.0
Tensorflowを使用した自己学習学習言語表現のためのLite Bertの実装
アルバートはバートに基づいていますが、いくつかの改善があります。メインベンチマークで最先端のパフォーマンスを達成し、30%のパラメーターが少なくなります。
albert_base_zhの場合、元のBertモデルの比較して10パーセントパラメーターしかあり、主な精度が保持されます。
Tensorflow、Pytorch、Kerasを含む中国語のアルバートの事前訓練モデルのさまざまなバージョンが現在入手可能です。
大規模な中国のコーパスに関する事前に訓練されたアルバートモデル:パラメーターが少なく、より良い結果。事前に訓練された小さなモデルも13のNLPタスクを獲得でき、アルバートの3つの主要な変換は接着剤ベンチマークの最上部に到達します
clueaiツールキット:3行のコード、3分でNLP APIをカスタマイズします(サンプル学習ゼロ)

10のデータセット、9つのベースラインモデル、およびワンクリック実行のモデル効果の詳細な比較、Clue Benchmarkを参照してください
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1。ALBERT_TINY_ZH、ALBERT_TINY_ZH(より長くトレーニング、学習するために20億サンプルの蓄積)、ファイルサイズ16m、パラメーターは4mです
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1。 albert_tiny_google_zh(10億サンプルの累積学習、Googleバージョン)、モデルサイズ16m、パフォーマンスはalbert_tiny_zhと一致しています
1.2。 albert_small_google_zh(10億サンプルの累積学習、Googleバージョン)、
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
2。ALBERT_LARGE_ZH、パラメーター数量、レイヤー数24、ファイルサイズは64mです
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3。ALBERT_BASE_ZH(追加の1億5,000万インスタンスが訓練されました。つまり、36Kステップ * batch_size 4096)。 albert_base_zh(小さなモデルエクスペリエンスバージョン)、パラメーター数量12m、レイヤー数12、サイズは40mです
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4。ALBERT_XLARGE_ZH_177K; albert_xlarge_zh_183k(優先試行)パラメーター数、レイヤー数24、ファイルサイズは230mです
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
Huggingface-Transformers 2.2.2に依存すると、上記のモデルを簡単に呼び出すことができます。
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
MODEL_NAMEの対応するリストは次のとおりです。
| モデル名 | model_name |
|---|---|
| albert_tiny_google_zh | voidful/albert_chinese_tiny |
| albert_small_google_zh | voidful/albert_chinese_small |
| albert_base_zh(Googleから) | voidful/albert_chinese_base |
| albert_large_zh(Googleから) | voidful/albert_chinese_large |
| albert_xlarge_zh(Googleから) | voidful/albert_chinese_xlarge |
| albert_xxlarge_zh(Googleから) | voidful/albert_chinese_xxlarge |
Transformersを介してAlbertを使用するより多くの例
次のコマンドを実行します。次のコマンドを実行します。プロジェクトには自動的にテキストファイルの例があります(data/news_zh_1.txt)
bash create_pretrain_data.sh
多くのテキストファイルがある場合は、パラメーター(tfrecords)を渡すことで、特定の形式の複数のファイルを生成できます。
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
python3 + tensorflow 1.xを使用します
たとえば、Tensorflow 1.4または1.5
例として、LCQMCタスクにalbert_baseを使用してください。 LCQMCタスクは、口語の説明データセットでテキストの類似性予測を行うことです。
微調整にはLCQMCデータセットを使用します。これは口頭言語コーパスであり、一対の文のセマンティックな類似性をトレーニングおよび予測するために使用されます。
トレーニング、検証、テストセットを含むLCQMCデータセットをダウンロードします。トレーニングセットには、1または0。1のラベルを持つ口語的な説明を含む240,000の中国の文のペアが含まれています。
次のコマンドを実行して、LCQMCデータセットで微調整します。
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03:albert_smallのGoogleバージョン、albert_tiny;
メソッドを追加して、シーケンス長128、60mメモリのために0.1秒の推論時間のみでモバイルデバイスにablert_tinyを展開する******
***** 2019-10-30:エッジ展開用のモデルをTensorflow Liteに変換することに関する簡単なガイドを追加*****
***** 2019-10-15:Albert_tiny_zh、トレーニングと推論のためにBert Baseの10倍速い、精度は残っています*****
***** 2019-10-07:アルバートのモデル*****
albert_xlarge_zh; albert_base_zh_additional_steps、より多くのインスタンスでトレーニング
***** 2019-10-04:AlbertのPytorchとKerasバージョンがサポートされていました*****
A.Pytorchバージョンにコンバートし、albert_pytorchを介してタスクを実行します
b。bert4kerasを介して1つのコードを使用して、事前に訓練されたモデルをKerasでロードします
Tensorflow 2.0を使用したC.Albertを使用:Bert-For-TF2を介してTF2.0を使用して事前訓練を受けたモデルを使用またはロードする
10月6日にalbert_xlargeをリリースします
***** 2019-10-02:albert_large_zh、albert_base_zh *****
BERT_BASEのパラメーターが10%しかないALBERT_BASE_ZH、小さなモデル(40m)とトレーニングは非常に高速になる可能性があります。
bert_base(64m)のパラメーターが16%しかないrelased albert_large_zh
***** 2019-09-28:コードとテスト機能*****
BertからのAlbertの3つの主要な変更のコードとテスト機能を追加する
Albert Modelは、Bertの改良版です。アートの他の最近のモデルとは異なり、今回は事前に訓練された小さなモデルであり、より良い結果とパラメーターが少なくなります。
BertのAlbertの3つの主要な変更に3つの変更を加えました。
1)単語埋め込みベクトルパラメーターの埋め込みパラメーター化を因数分解します
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2)クロスレイヤーパラメーター共有
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3)段落連続性タスク間文間コヒーレンス損失。
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
その他の変更:
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
30gの中国のコーパス、複数の百科事典、ニュース、インタラクティブなコミュニティを含む100億人以上の漢字。
事前に訓練されたシーケンス長シーケンス_Lengthは512に設定され、Batch batch_sizeは4096で、トレーニングは3億5,000万のトレーニングデータ(インスタンス)を生成します。各モデルはデフォルトで125Kステップをトレーニングし、Albert_XXLARGEはより長くトレーニングされます。
比較のために、Roberta_Zhプリトレーニングは、256のシーケンス長で2億5,000万トレーニングデータを生成しました。Albert_Zhプレトレーニングはより多くのトレーニングデータを生成し、より長いシーケンス長を使用しているため、
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
トレーニングはTPU V3 PODを使用し、32 V3-8を含むV3-256を使用しています。各V3-8マシンには、128gのビデオメモリが含まれています。
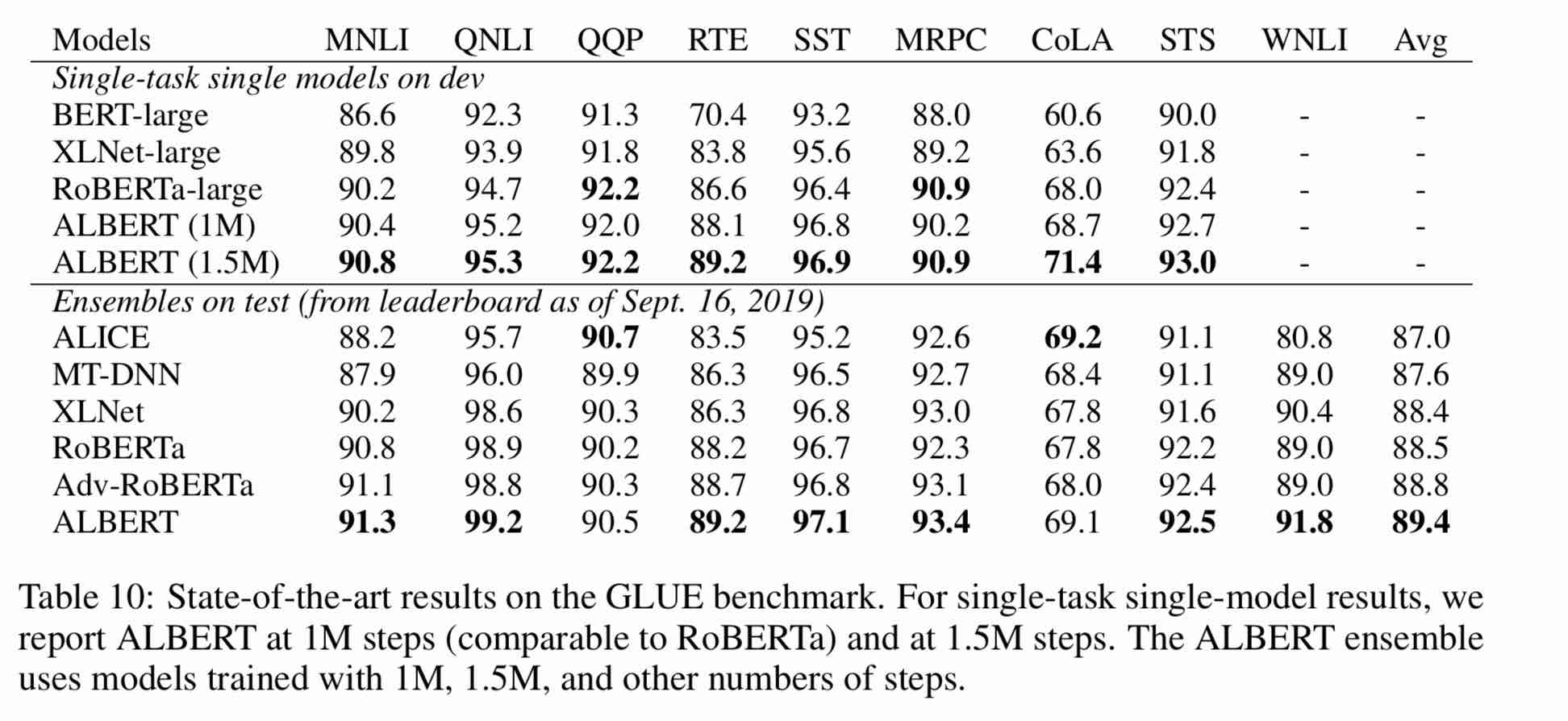
| モデル | 開発セット(開発) | テストセット(テスト) |
|---|---|---|
| バート | 89.4(88.4) | 86.9(86.4) |
| アーニー | 89.8(89.6) | 87.2(87.0) |
| bert-wwm | 89.4(89.2) | 87.0(86.8) |
| bert-wwm-ext | - | - |
| Roberta-Zh-base | 88.7 | 87.0 |
| ロベルタ・ザ・ラージ | 89.9(89.6) | 87.2(86.7) |
| roberta-zh-large(20w_steps) | 89.7 | 87.0 |
| アルバートzh-tiny | - | 85.4 |
| アルバート・zhsmall | - | 86.0 |
| Albert-Zh-Small(Pytorch) | - | 86.8 |
| Albert-Zh-Base-Additional-36Kステップ | 87.8 | 86.3 |
| Albert-Zh-Base | 87.2 | 86.3 |
| アルバート・ラージ | 88.7 | 87.1 |
| Albert-Xlarge | 87.3 | 87.7 |
注:Albert-Xlargeを一度だけ実行しましたが、効果が改善される可能性があります
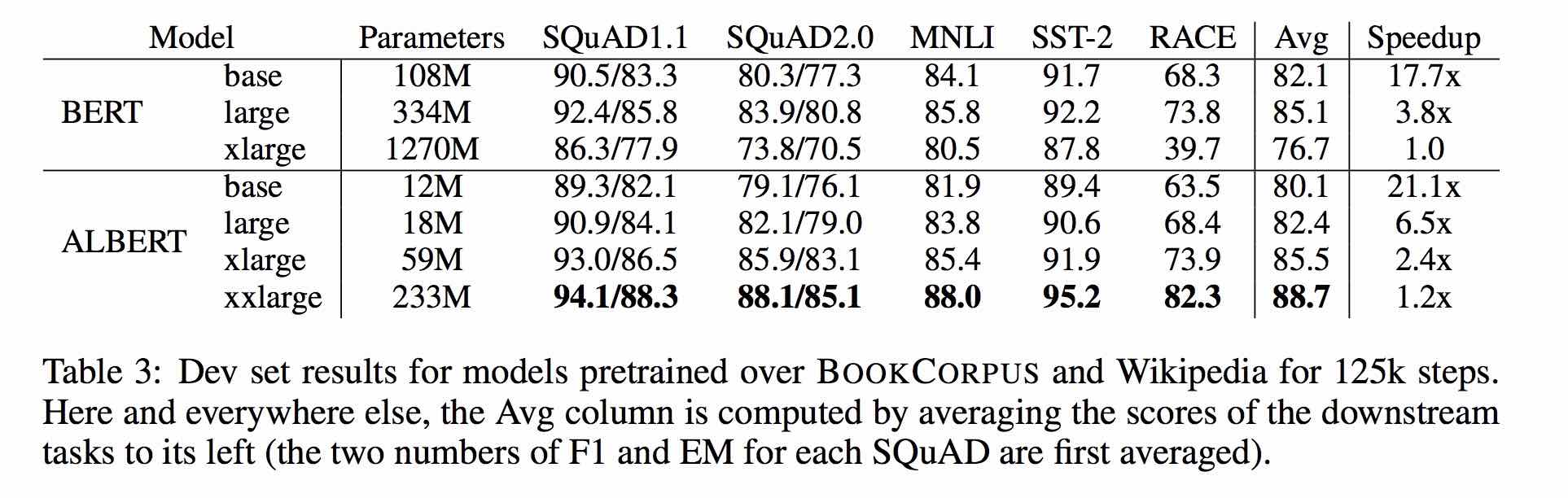
| モデル | 開発セット | テストセット |
|---|---|---|
| バート | 77.8(77.4) | 77.8(77.5) |
| アーニー | 79.7(79.4) | 78.6(78.2) |
| bert-wwm | 79.0(78.4) | 78.2(78.0) |
| bert-wwm-ext | 79.4(78.6) | 78.7(78.3) |
| xlnet | 79.2 | 78.7 |
| Roberta-Zh-base | 79.8 | 78.8 |
| ロベルタ・ザ・ラージ | 80.2(80.0) | 79.9(79.5) |
| アルバートベース | 77.0 | 77.1 |
| アルバート・ラージ | 78.0 | 77.5 |
| Albert-Xlarge | ? | ? |
注:bert-wwm-extはここから来ます。 xlnetはここから来ます。 Roberta-Zh-Baseは、12層のRoberta Chinese Modelを指します
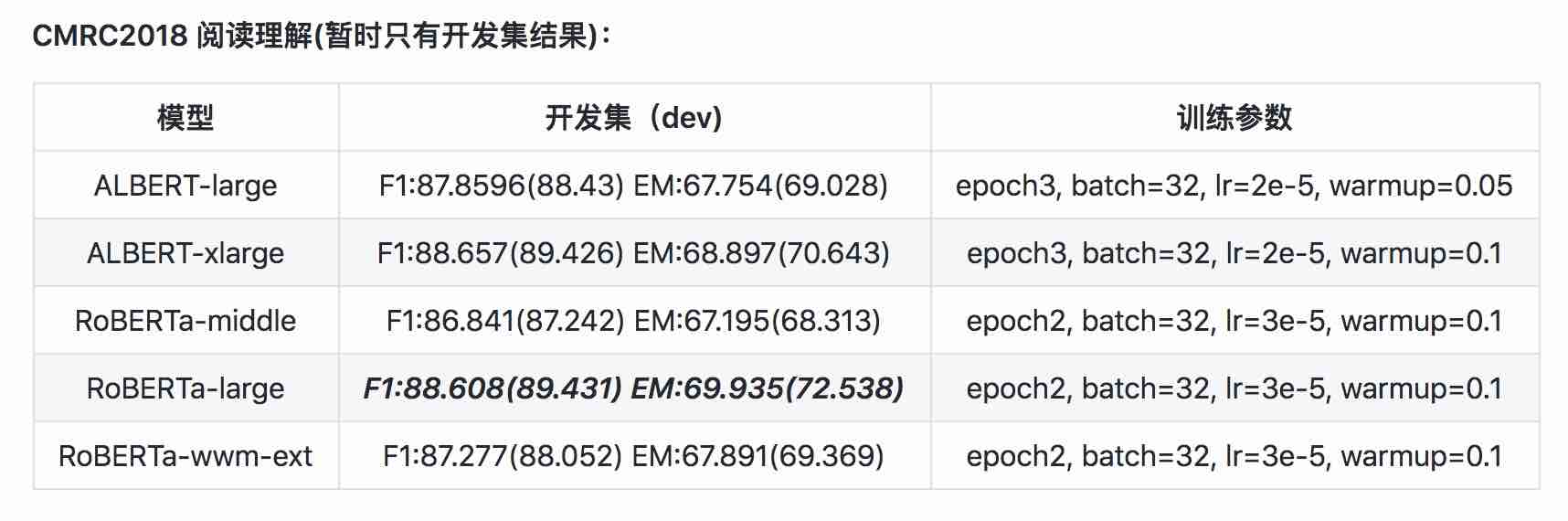
| モデル | MLM Eval Acc | SOP Eval Acc | トレーニング(時間) | 損失評価 |
|---|---|---|---|---|
| albert_zh_base | 79.1% | 99.0% | 6H | 1.01 |
| albert_zh_large | 80.9% | 98.6% | 22.5H | 0.93 |
| albert_zh_xlarge | ? | ? | 53H(推定) | ? |
| albert_zh_xxlarge | ? | ? | 106h(推定) | ? |
注記:?すぐに交換されます
単語の埋め込みベクターパラメーター、クロスレイヤーパラメーター共有、段落の連続性タスクなどの因数分解を含むがこれらに限定されない、次のコマンドを実行して、主な改善点をテストします。
python test_changes.py
ここでは、主にTfliteモデル形式の変換とパフォーマンステストを導入します。 Tfliteモデルに変換した後、モバイル側でモデルを使用する方法については、Tfliteが提供する完全なAndroid/iOSアプリケーション開発ケースチュートリアルページを参照できます。このページには現在、2つのAndroidケースが含まれています。テキスト分類とテキストQ&A。
以下は、Tfliteモデル形式の変換とパフォーマンステストを導入する例です。
> = 1.14 1.xをインストールして、2.xディストリビューションから削除されているため、freze_graphツールを使用するようにインストールしてください
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
Tensorflow Nightly Buildに分布する新しい実験TF-> Tfliteコンバーターを使用します。
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
Tfliteのパフォーマンスベンチマークツールの詳細については、こちらをご覧ください。たとえば、Android電話用のベンチマークツールバイナリを構築した後、Tfliteモデルが電話でどのように機能するかについてのアイデアを取得するために、次のことを行います。
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
QualcommのSD845 SoCを備えたAndroid電話では、上記のベンチマークツールを介して、2019/11/01年の時点で、CPU上の4つのスレッドを使用してこの変換されたTfliteモデルを使用して〜120msであり、推論中のモデルのメモリ使用量は60MBです。将来のTFLITE実装の最適化により、パフォーマンスがさらに向上することに注意してください。
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
albert_pytorchを使用します
Bert4Kerasは、Albert_Zhの重量を正常にロードできるAlbertに適応します。 load_pretrained_model関数にalbert = trueを追加するだけです。
BERT4KERASで事前に訓練されたモデルをロードします
bert-for-tf2
関数の説明:ユーザーはこの例を使用して、トレーニングセットをロードする方法を理解して、ユーザーの入力に基づいて短いテキストの類似性判断を達成することができます。このコードに基づいて、プログラムをバックグラウンドサービスに柔軟に拡張したり、テキスト分類やその他の例を追加したりできます。
関与するコード:類似性、args.py
ステップ:
1.このモデルを使用してテキストの類似性をトレーニングし、モデルファイルを対応するディレクトリに保存します。
2。実際の状況によると、args.pyのパラメーターを変更します。パラメーターは次のとおりです。
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )この例のファイル構造は次のとおりです。
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3.ユーザー入力ワードを変更します
類似性を開き、次のコードを下にあります。
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])ここで、sim.start_model()は負荷モデルを表し、sim.predict_sentencesの入力はタプルの配列であり、タプルには2つの要素が含まれています。
4。Pythonファイルを実行:類似性。py
| システム | seqの長さ | 最大バッチサイズ |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - | - |
質問がある場合は、問題を提起するか、メールを送信してください:[email protected];
現在、AlbertのPytorchバージョンの使用方法はまだ明確ではありません。その方法を知っていれば、電子メールを送信するか、問題を開いてください。
また、タスクのパフォーマンスを報告するためにプルリクエストを送信したり、Pytorchなどのモデルをロードする方法に関する方法を追加したりすることもできます。
トレーニング前の中国のモデルを生成するためのアイデアがある場合は、お知らせください。
Bright Liang Xu、Albert_Zh、(2019)、Github Repository、https://github.com/brightmart/albert_zh
1。アルバート:言語表現の自己監視学習のためのライトバート
2。バート:言語理解のための深い双方向変圧器の事前訓練
3。Spanbert:スパンを表現および予測することにより、トレーニング前の改善
4。Roberta:堅牢に最適化されたBert Pretrainingアプローチ
5。深い学習のための大規模なバッチ最適化:76分でバートをトレーニングする(子羊)
6。ラムオプティマイザー、TensorFlowバージョン
7.事前に訓練された小さなモデルも13のNLPタスクを獲得することができ、アルバートの3つの主要な変換は接着剤ベンチマークの最上部に到達します
8。ALBERT_PYTORCH
9.アルバートをケラスでロードします
10。アルバートをTF2.0でロードします
11。GoogleのAlbertのレポ
12。中国の接着剤と中国のタスクベンチマーク評価:公開されている複数のタスク、ベースラインモデル、広範な評価と効果の比較


