albert_zh
1.0.0
Реализация Lite Bert для самоотверженных представлений об обучении с TensorFlow
Альберт основан на Берте, но с некоторыми улучшениями. Он достигает современной производительности на основных критериях с 30% параметрами меньше.
Для albert_base_zh у него есть только десять процентных параметров по сравнению с исходной моделью BERT, и основная точность сохраняется.
В настоящее время доступна различная версия предварительно обученной модели Albert для китайцев, включая Tensorflow, Pytorch и Keras.
Предварительно обученная модель Альберта по массовому китайскому корпусу: меньше параметров и лучшие результаты. Предварительно обученные небольшие модели также могут выиграть 13 задач NLP, а три основные преобразования Альберта достигают вершины клея.
Clueai Toolkit: три строки кода, настройте API NLP за три минуты (нулевое обучение образца)

Подробное сравнение эффектов модели на 10 наборах данных, 9 базовых моделей и пробега на одном клике, см. Cline Tenchmark
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1. Albert_tiny_zh, albert_tiny_zh (обучение дольше, накапливание 2 миллиарда образцов для изучения), размер файла 16M, параметр 4M
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. albert_tiny_google_zh (аккумулятивное обучение из 1 миллиарда образцов, версия Google), размер модели 16M, производительность соответствует Albert_tiny_zh
1.2. albert_small_google_zh (аккумулятивное обучение 1 миллиарда образцов, версия Google),
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
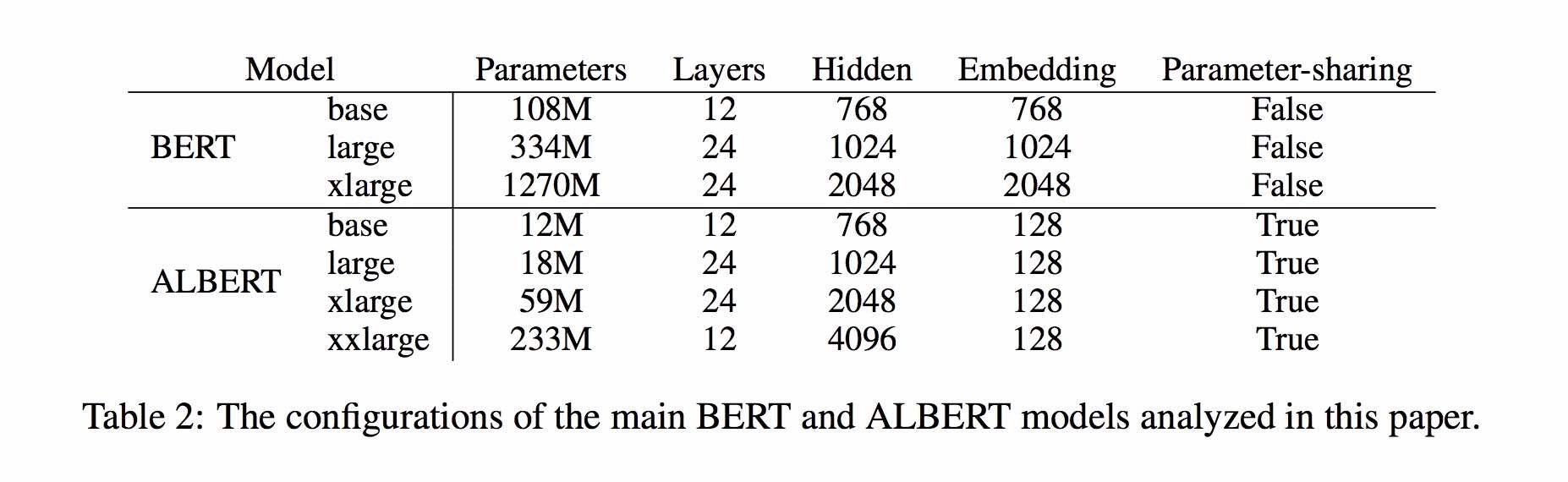
2. albert_large_zh, количество параметров, количество слоев 24, размер файла - 64 м
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3. albert_base_zh (было обучено дополнительные 150 миллионов случаев, то есть 36 тысячи шагов * batch_size 4096); albert_base_zh (версия малого модели), количество параметров 12 м, количество слоев 12, размер 40 м.
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. albert_xlarge_zh_177k; albert_xlarge_zh_183k (priority try) Количество параметров, количество слоев 24, размер файла составляет 230 м
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
Полагаясь на Huggingface-Transformers 2.2.2, приведенные выше модели можно легко вызвать.
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
Соответствующий список MODEL_NAME заключается в следующем:
| Название модели | Model_name |
|---|---|
| albert_tiny_google_zh | voidful/albert_chinese_tiny |
| albert_small_google_zh | voidful/albert_chinese_small |
| albert_base_zh (из Google) | voidful/albert_chinese_base |
| albert_large_zh (из Google) | voidful/albert_chinese_large |
| albert_xlarge_zh (из Google) | voidful/albert_chinese_xlarge |
| albert_xxlarge_zh (из Google) | voidful/albert_chinese_xxlarge |
Больше примеров использования Альберта через трансформаторы
Запустите следующую команду. Запустите следующую команду. Проект автоматически имеет пример текстового файла (data/news_zh_1.txt)
bash create_pretrain_data.sh
Если у вас много текстовых файлов, вы можете сгенерировать несколько файлов определенных форматов, передавая параметры (tfrecords)
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
Используйте python3 + tensorflow 1.x
например, TensorFlow 1,4 или 1,5
Возьмите с помощью ALBERT_BASE для задач LCQMC в качестве примера. Задача LCQMC состоит в том, чтобы сделать прогнозы сходства текста в наборе данных разговорного описания.
Мы будем использовать набор данных LCQMC для тонкой настройки, это пероральный язык, он используется для обучения и прогнозирования семантического сходства пары предложений.
Загрузите набор данных LCQMC, который содержит обучение, проверку и наборы тестов. Учебный набор содержит 240 000 пары предложений китайского предложения с разговорными описаниями, с этикетками 1 или 0. 1 - семантическое сходство предложения, а 0 - семантическое отличное.
Делайте тонкую настройку на наборе данных LCQMC, выполнив следующую команду:
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03: Добавить Google версию Albert_small, Albert_tiny;
Добавить метод для развертывания ABLERT_TINY в мобильные устройства с только 0,1 секундным временем вывода для длины последовательности 128, 60M памяти ******
***** 2019-10-30: добавьте простое руководство по преобразованию модели в Tensorflow Lite для развертывания Edge *****
***** 2019-10-15: albert_tiny_zh, в 10 раз быстро, чем база Bert для обучения и вывода, точность остается *****
***** 2019-10-07: больше моделей Альберта *****
добавить albert_xlarge_zh; albert_base_zh_additional_steps, обучение с большим количеством экземпляров
***** 2019-10-04: Pytorch и Keras версии Альберта были поддержаны *****
A.convert to Pytorch версии и выполняйте свои задачи через albert_pytorch
B. Загрузить предварительно обученную модель с керами, используя одну линию кодов через Bert4keras
C. Используйте Albert с Tensorflow 2.0: используйте или загруженную модель с TF2.0 через BERT-FOR-TF2
Выпуск albert_xlarge 6 октября
***** 2019-10-02: albert_large_zh, albert_base_zh *****
Релеванная albert_base_zh с только 10% параметров bert_base, небольшая модель (40 м) и обучение может быть очень быстро.
RELASED ALBERT_LARGE_ZH с только 16% параметров BERT_BASE (64M)
***** 2019-09-28: коды и тестовые функции *****
Добавьте коды и функции тестирования для трех основных изменений Albert от Bert
Модель Альберта - это улучшенная версия Берта. В отличие от других недавних моделей искусства, на этот раз это предварительно обученная небольшая модель, с лучшими результатами и меньшим количеством параметров.
Он сделал три изменения в Берт три основных изменения Альберта от Берта:
1) Факторизированная встроенная параметризация параметров вектора встраивания слов
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) Обмен параметрами межслойных параметров
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) Задача непрерывности абзаца в межплементных потери когерентности.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
Другие изменения:
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
30G Китайский корпус, более 10 миллиардов китайских иероглифы, в том числе несколько энциклопедий, новости и интерактивные сообщества.
Предварительно обученная последовательность последовательности. Каждая модель по умолчанию будет обучать 125K шагов, а albert_xxlarge будет обучаться дольше.
Для сравнения, предварительное обучение Roberta_ZH сгенерировало 250 миллионов учебных данных с длиной последовательности 256. Поскольку предварительное обучение Albert_ZH генерирует больше учебных данных и использует более длительные длины последовательности,
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
Обучение использует POD TPU V3, мы используем V3-256, который содержит 32 V3-8. Каждая машина V3-8 содержит 128 г видео памяти.
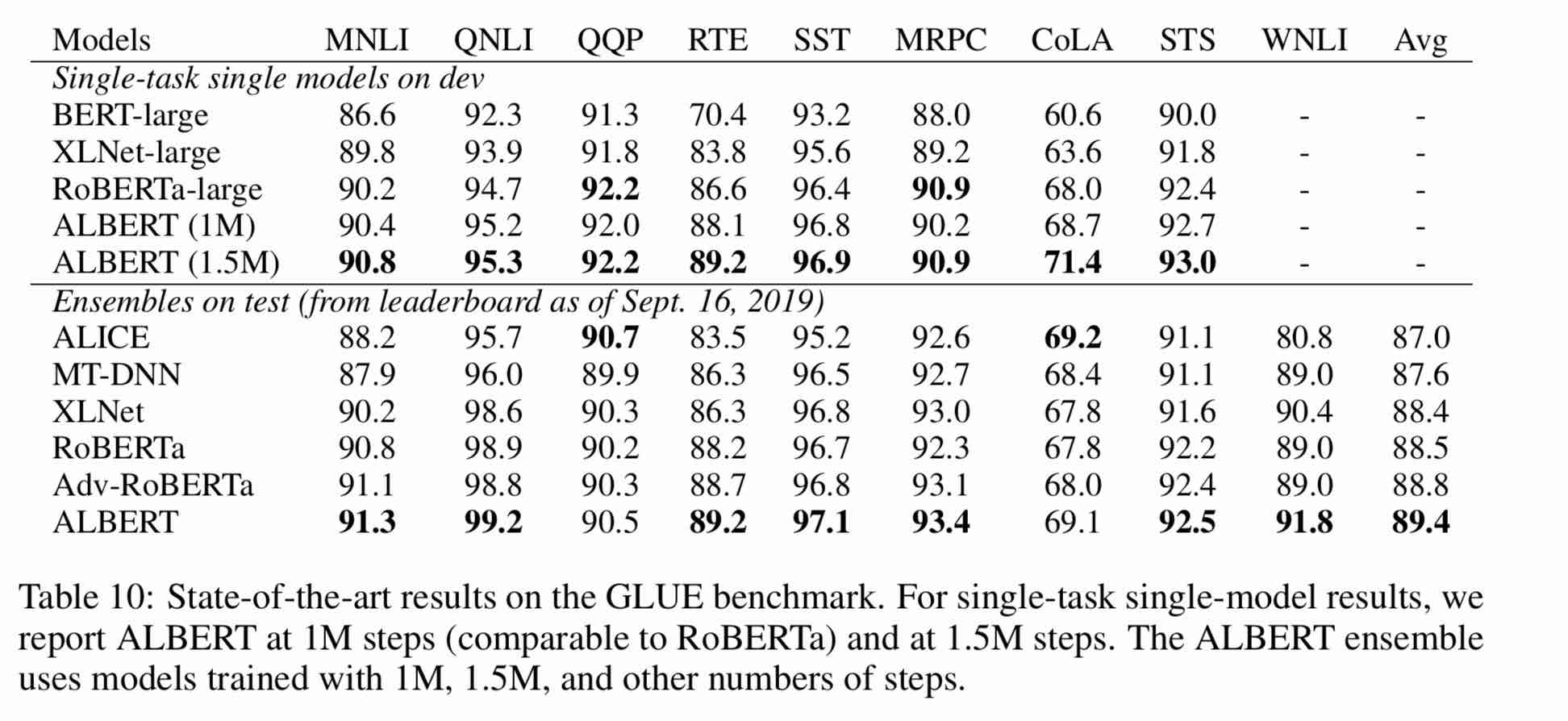
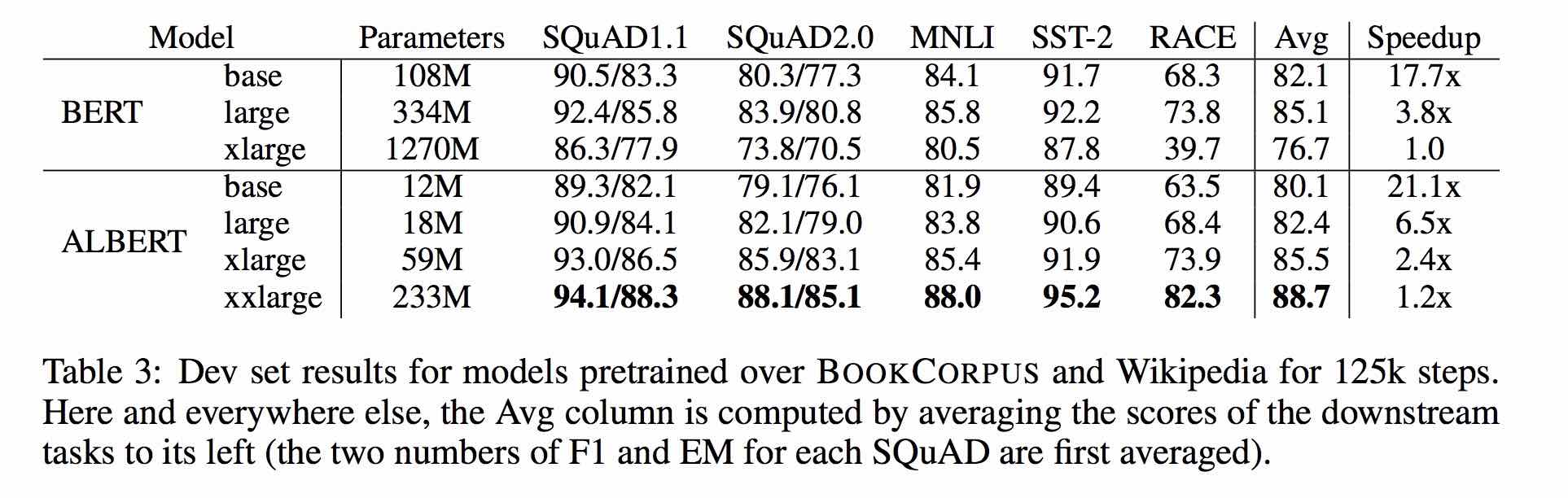
| Модель | Набор разработки (DEV) | Тестовый набор (тест) |
|---|---|---|
| БЕРТ | 89,4 (88,4) | 86,9 (86,4) |
| ЭРНИ | 89,8 (89,6) | 87,2 (87,0) |
| Берт-УВМ | 89,4 (89,2) | 87,0 (86,8) |
| Bert-WWM-Ext | - | - |
| Роберта-ZH-баз | 88.7 | 87.0 |
| Роберта-ЗХ-Лардж | 89,9 (89,6) | 87,2 (86,7) |
| Roberta-ZH-Large (20W_STEPS) | 89,7 | 87.0 |
| Альберт-ZH-Нижний | - | 85,4 |
| Альберт-ZH-Small | - | 86.0 |
| Albert-ZH-Small (Pytorch) | - | 86.8 |
| Albert-ZH-Base-Additional-36K-шаги | 87.8 | 86.3 |
| Альберт-ZH-баз | 87.2 | 86.3 |
| Альберт-широкий | 88.7 | 87.1 |
| Альберт-Хларж | 87.3 | 87.7 |
Примечание: я запустил Albert-xlarge только один раз, и эффект может быть улучшен
| Модель | Разработка набора | Тестовый набор |
|---|---|---|
| БЕРТ | 77,8 (77,4) | 77,8 (77,5) |
| ЭРНИ | 79,7 (79,4) | 78,6 (78,2) |
| Берт-УВМ | 79,0 (78,4) | 78,2 (78,0) |
| Bert-WWM-Ext | 79,4 (78,6) | 78,7 (78,3) |
| Xlnet | 79,2 | 78.7 |
| Роберта-ZH-баз | 79,8 | 78.8 |
| Роберта-ЗХ-Лардж | 80.2 (80,0) | 79,9 (79,5) |
| Альберт-баз | 77.0 | 77.1 |
| Альберт-широкий | 78.0 | 77.5 |
| Альберт-Хларж | ? | ? |
Примечание: BERT-WWM-EXT выходит отсюда; Xlnet выходит отсюда; Роберта-ZH-баз относится к 12-слойной модели Роберты Китая
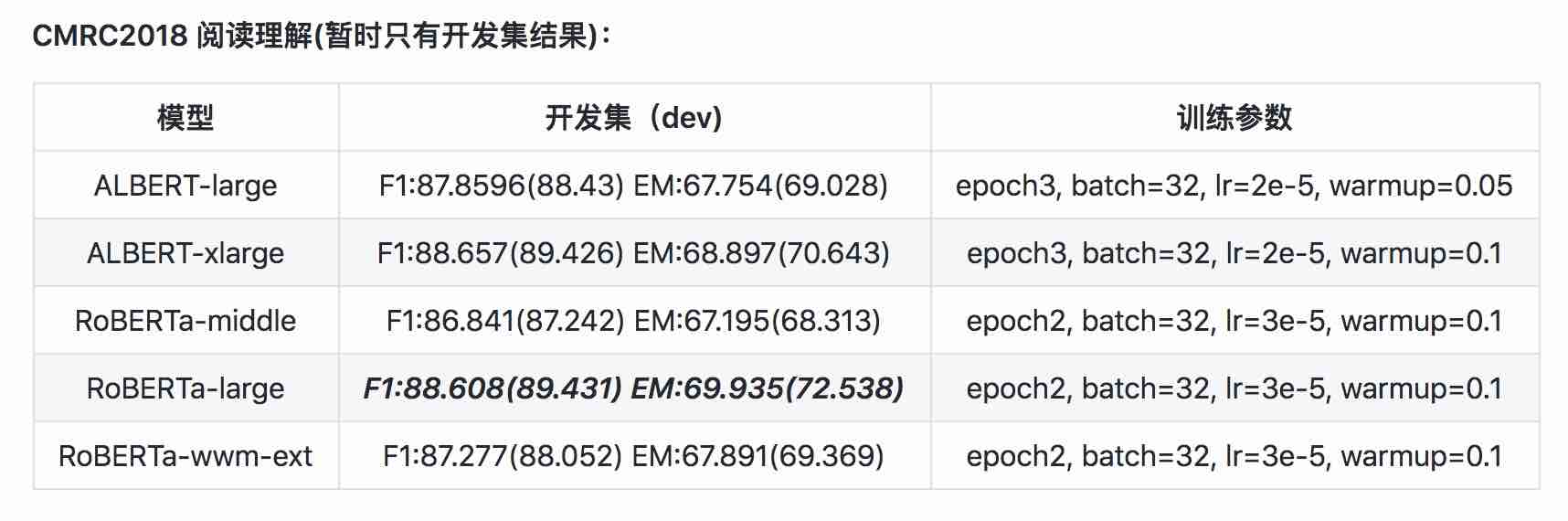
| Модель | MLM Eval Acc | SOP Eval Acc | Обучение (часы) | Потеря |
|---|---|---|---|---|
| albert_zh_base | 79,1% | 99,0% | 6H | 1.01 |
| albert_zh_large | 80,9% | 98,6% | 22,5H | 0,93 |
| albert_zh_xlarge | ? | ? | 53H (по оценкам) | ? |
| albert_zh_xxlarge | ? | ? | 106h (по оценкам) | ? |
Примечание:? Скоро будет заменен
Проверьте основные точки улучшения, запустив следующие команды, включая, но не ограничиваясь факторизацией параметров вектора встраивания слов, совместного использования параметров, задач непрерывности параграфа и т. Д.
python test_changes.py
Здесь мы в основном представляем преобразование формата модели TFLITE и тестирование производительности. После преобразования в Tflite Model, для того, как использовать модель на мобильной стороне, вы можете обратиться к полной странице учебного положения для разработки приложений Android/iOS, предоставленной Tflite. Эта страница в настоящее время содержит два случая Android: текстовая классификация и текстовые вопросы и ответы.
Ниже приведен пример для представления преобразования формата модели TFLITE и тестирования производительности:
Убедитесь, что можно было установить> = 1.14 1.x для использования инструмента freeze_graph, когда он удален из 2.x распределения
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
Мы собираемся использовать новый экспериментальный преобразователь TFLITE, который распространяется с ночной сборкой TensorFlow.
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
См. Здесь для получения подробной информации о инструментах Bethencmmark в Tflite. Например: после создания Benchmark Tool Binary для телефона Android, сделайте следующее, чтобы получить представление о том, как модель TFLITE работает на телефоне
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
На телефоне Android с SD845 SOC от Qualcomm с помощью вышеуказанного эталонного инструмента по состоянию на 2019/11/11/01 задержка вывода составляет ~ 120 мс с этой конвертированной моделью TFLITE с использованием 4 потоков на процессоре, а использование памяти составляет ~ 60 МБ для модели во время вывода. Обратите внимание, что производительность улучшится с будущими оптимизацией реализации TFLITE.
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
Используя albert_pytorch
Bert4keras адаптируется к Альберту, который может успешно загрузить вес albert_zh. Вам нужно только добавить albert = true к функции LOAD_PRETRIND_MODEL.
Загрузите предварительно обученную модель с Bert4keras
Bert-for-TF2
Описание функции: Пользователи могут использовать этот пример, чтобы понять, как загрузить обучающий набор для достижения суждения о сходстве короткого текста на основе ввода пользователя. На основе этого кода вы можете гибко расширить программу в фоновые службы или добавить классификацию текста и другие примеры.
Код вовлечен: searnity.py, args.py
шаг:
1. Используйте эту модель, чтобы обучить сходство текста и сохранить файл модели в соответствующий каталог.
2. Согласно фактической ситуации, измените параметры в args.py. Параметры следующие:
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )Структура файла в этом примере:
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. Измените слово пользовательского ввода
Open SANESITY.PY и следующий код внизу:
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])где sim.start_model () представляет модель загрузки, а вход Sim.predict_sentences - это массив кортежей, а кортеж содержит два элемента, предложения, которые необходимо судить аналогично.
4. Запустите файл Python: searnity.py
| Система | Длина SEQ | Максимальный размер партии |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - | - |
Если у вас есть какие -либо вопросы, вы можете поднять проблему или отправить мне электронное письмо: [email protected];
В настоящее время как использовать версию Albert Pytorch, пока неясно, если вы знаете, как это сделать, просто напишите нам или откройте проблему.
Вы также можете отправить запрос на то, чтобы сообщить о своей производительности по вашей задаче или добавить методы, как загружать модели для Pytorch и так далее.
Если у вас есть идеи для создания лучшей производительности, предварительно обучающей китайскую модель, пожалуйста, дайте мне знать.
Bright Liang Xu, Albert_ZH, (2019), репозиторий GitHub, https://github.com/brightmart/albert_zh
1. Альберт: Lite Bert для самоотверженного изучения языковых представлений
2. Берт: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка
3. Spanbert: улучшение предварительного обучения, представляя и прогнозируя пролеты
4. Роберта: надежно оптимизированный подход Bert Pretristing
5. Большая оптимизация партии для глубокого обучения: обучение BERT за 76 минут (ягненка)
6. Оптимизатор ягненка, версия Tensorflow
7. Предварительно обученные небольшие модели также могут выиграть 13 задач NLP, а три основные преобразования Альберта достигают вершины клея.
8. albert_pytorch
9. Загрузите Альберт керасом
10. Загрузите Альберт с TF2.0
11. Репо Альберт из Google
12. Китайский сгибал-китайский эталонный эталон Оценка: общедоступные множественные задачи, базовые модели, обширная оценка и сравнение эффектов


