albert_zh
1.0.0
Una implementación de un Lite Bert para representaciones de lenguaje de aprendizaje auto-supervisado con TensorFlow
Albert se basa en Bert, pero con algunas mejoras. Logra la actuación de última generación en los puntos de referencia principales con un 30% de parámetros menos.
Para Albert_Base_ZH solo tiene diez parámetros porcentuales en comparación con el modelo Bert original, y se conserva la precisión principal.
Ahora está disponible una versión diferente del modelo previamente capacitado de Albert, incluidos TensorFlow, Pytorch y Keras.
Modelo de Albert previamente capacitado en un corpus chino masivo: menos parámetros y mejores resultados. Los modelos pequeños previamente capacitados también pueden ganar 13 tareas de PNL, y las tres principales transformaciones de Albert alcanzan la parte superior del punto de referencia de pegamento
CLUEAI Toolkit: tres líneas de código, personalice una API NLP en tres minutos (aprendizaje de muestra cero)

Una comparación detallada de los efectos del modelo en 10 conjuntos de datos, 9 modelos de referencia y ejecución de un solo clic, ver Benchmark de pistas
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1. Albert_tiny_zh, Albert_tiny_zh (entrenando más largo, acumulando 2 mil millones de muestras para aprender), tamaño de archivo 16m, el parámetro es 4m
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. Albert_tiny_google_zh (aprendizaje acumulativo de mil millones de muestras, versión de Google), tamaño del modelo 16m, el rendimiento es consistente con Albert_tiny_Zh
1.2. albert_small_google_zh (aprendizaje acumulativo de mil millones de muestras, versión de Google),
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
2. Albert_large_Zh, cantidad de parámetros, número de capas 24, el tamaño del archivo es de 64 m
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3. Albert_base_zh (se capacitaron 150 millones adicionales de casos, es decir, 36k pasos * Batch_Size 4096); Albert_base_zh (versión de experiencia de modelo pequeño), cantidad de parámetros 12m, número de capas 12, el tamaño es de 40 m
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. Albert_xlarge_ZH_177K; Albert_xlarge_ZH_183K (Prueba prioritaria) Cantidad del parámetro, número de capas 24, el tamaño del archivo es de 230 m
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
Confiando en Huggingface-Transformers 2.2.2, los modelos anteriores se pueden llamar fácilmente.
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
La lista correspondiente de MODEL_NAME es la siguiente:
| Nombre del modelo | Model_name |
|---|---|
| albert_tiny_google_zh | Voidful/Albert_chinese_Tiny |
| albert_small_google_zh | Voidful/Albert_Chinese_Small |
| albert_base_zh (de Google) | Voidful/Albert_chinese_Base |
| Albert_large_Zh (de Google) | Voidful/Albert_chinese_Large |
| Albert_xlarge_Zh (de Google) | Voidful/Albert_chinese_xlarge |
| Albert_xxlarge_Zh (de Google) | voidful/albert_chinese_xxlarge |
Más ejemplos de uso de Albert a través de Transformers
Ejecutar el siguiente comando Ejecute el siguiente comando. El proyecto tiene automáticamente un archivo de texto de ejemplo (data/news_zh_1.txt)
bash create_pretrain_data.sh
Si tiene muchos archivos de texto, puede generar múltiples archivos de formatos específicos pasando parámetros (TFRecords)
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
Use python3 + tensorflow 1.x
por ejemplo, TensorFlow 1.4 o 1.5
Tome el uso de Albert_Base para las tareas LCQMC como ejemplo. La tarea LCQMC es hacer predicciones de similitud de texto en un conjunto de datos de descripción coloquial.
Usaremos un conjunto de datos LCQMC para ajustar, es el corpus de lenguaje oral, se usa para entrenar y predecir la similitud semántica de un par de oraciones.
Descargue el conjunto de datos LCQMC, que contiene conjuntos de capacitación, validación y prueba. El conjunto de capacitación contiene 240,000 pares de oraciones chinas con descripciones coloquiales, con etiquetas de 1 o 0. 1 es una similitud semántica de oraciones, y 0 es semántica diferente.
Haga ajuste fino en el conjunto de datos LCQMC ejecutando el siguiente comando:
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03: Agregue la versión de Google de Albert_Small, Albert_tiny;
Agregue el método para implementar ABLERT_TINY en dispositivos móviles con solo 0.1 segundos de tiempo de inferencia para la longitud de secuencia 128, 60m memoria ******
***** 2019-10-30: Agregue una guía simple sobre la conversión del modelo a tensorflow lite para la implementación de borde *****
***** 2019-10-15: Albert_tiny_zh, 10 veces más rápido que Bert Base para entrenamiento e inferencia, la precisión permanece *****
***** 2019-10-07: Más modelos de Albert *****
Agregar Albert_XLarge_Zh; albert_base_zh_additional_steps, entrenamiento con más instancias
***** 2019-10-04: Las versiones de Pytorch y Keras de Albert fueron apoyadas *****
A. Convertir a la versión de Pytorch y hacer sus tareas a través de Albert_Pytorch
B. Cargue el modelo previamente capacitado con keras usando una línea de códigos a través de Bert4keras
C.Use Albert con TensorFlow 2.0: Use o cargue el modelo previamente capacitado con TF2.0 a través de Bert-For-TF2
Liberando Albert_XLarge el 6 de octubre
***** 2019-10-02: Albert_large_ZH, Albert_Base_Zh *****
RELESE ALBERT_BASE_ZH con solo el 10% de parámetros de Bert_Base, un modelo pequeño (40m) y el entrenamiento puede ser muy rápido.
Conelado Albert_large_Zh con solo el 16% de parámetros de Bert_Base (64m)
***** 2019-09-28: Códigos y funciones de prueba *****
Agregar códigos y funciones de prueba para tres cambios principales de Albert de Bert
El modelo Albert es una versión mejorada de Bert. A diferencia de otros modelos recientes del arte, esta vez es un modelo pequeño previamente capacitado, con mejores resultados y menos parámetros.
Ha realizado tres cambios en Bert tres cambios principales de Albert de Bert:
1) parametrización integrada factorizada de parámetros de vector de incrustación de palabras
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) compartir parámetros de capa cruzada
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) Pérdida de coherencia de la tarea de continuidad del párrafo.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
Otros cambios:
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
30G Corpus chino, más de 10 mil millones de caracteres chinos, incluidas múltiples enciclopedias, noticias y comunidades interactivas.
La longitud de secuencia previamente capacitada secuence_length se establece en 512, el lote de lotes es 4096 y el entrenamiento genera 350 millones de datos de entrenamiento (instancia); Cada modelo capacitará a 125k pasos por defecto, y Albert_xxLarge estará entrenado por más tiempo.
A modo de comparación, el pre-entrenamiento de Roberta_ZH generó 250 millones de datos de entrenamiento con una longitud de secuencia de 256. Dado que el pre-entrenamiento de Albert_ZH genera más datos de entrenamiento y utiliza longitudes de secuencia más largas,
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
El entrenamiento usa TPU V3 POD, estamos usando V3-256, que contiene 32 V3-8. Cada máquina V3-8 contiene 128 g de memoria de video.
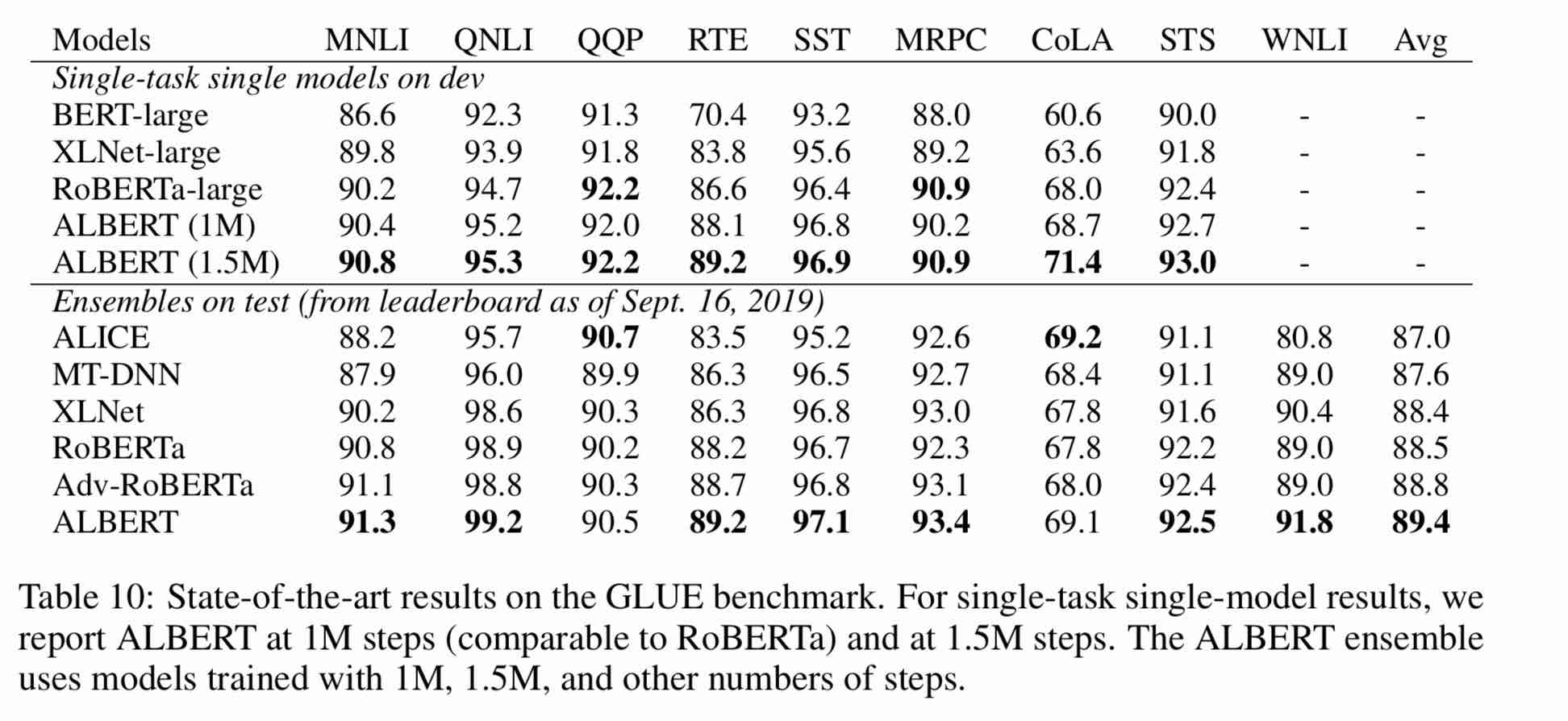
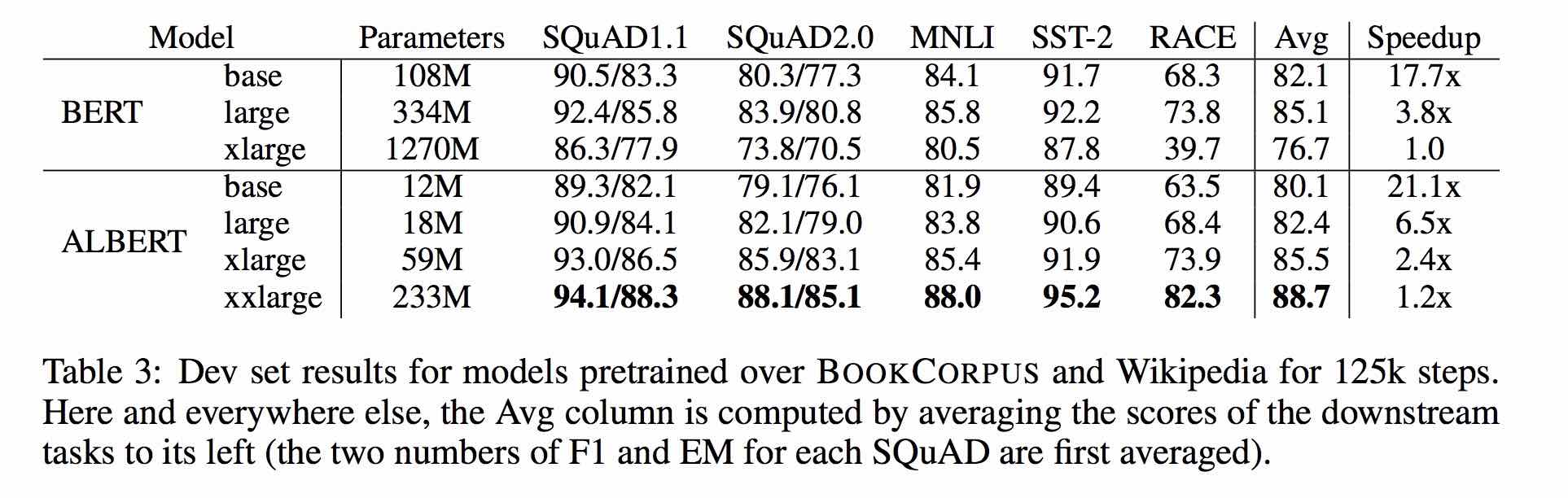
| Modelo | Conjunto de desarrollo (Dev) | Conjunto de prueba (prueba) |
|---|---|---|
| Bert | 89.4 (88.4) | 86.9 (86.4) |
| Ernie | 89.8 (89.6) | 87.2 (87.0) |
| Bert-wwm | 89.4 (89.2) | 87.0 (86.8) |
| Bert-wwm-ext | - | - |
| Rober-zh-base | 88.7 | 87.0 |
| ROBERTA-ZH-LARGE | 89.9 (89.6) | 87.2 (86.7) |
| ROBERTA-ZH-LARGE (20W_STEPS) | 89.7 | 87.0 |
| Albert-zh pequeño | - | 85.4 |
| Albert-Zh-Small | - | 86.0 |
| Albert-Zh-Small (Pytorch) | - | 86.8 |
| Albert-zh-base-addicional-36K-passs | 87.8 | 86.3 |
| Albert-zh-base | 87.2 | 86.3 |
| Albert-Large | 88.7 | 87.1 |
| Albert-xlarge | 87.3 | 87.7 |
Nota: Solo ejecuté Albert-Xlarge una vez, y el efecto puede mejorarse
| Modelo | Conjunto de desarrollo | Set de prueba |
|---|---|---|
| Bert | 77.8 (77.4) | 77.8 (77.5) |
| Ernie | 79.7 (79.4) | 78.6 (78.2) |
| Bert-wwm | 79.0 (78.4) | 78.2 (78.0) |
| Bert-wwm-ext | 79.4 (78.6) | 78.7 (78.3) |
| XLNET | 79.2 | 78.7 |
| Rober-zh-base | 79.8 | 78.8 |
| ROBERTA-ZH-LARGE | 80.2 (80.0) | 79.9 (79.5) |
| Albert-base | 77.0 | 77.1 |
| Albert-Large | 78.0 | 77.5 |
| Albert-xlarge | ? | ? |
Nota: Bert-WWM-EXT proviene de aquí; XLNet viene de aquí; ROBERTA-ZH-BASE se refiere al modelo chino de Roberta de 12 capas
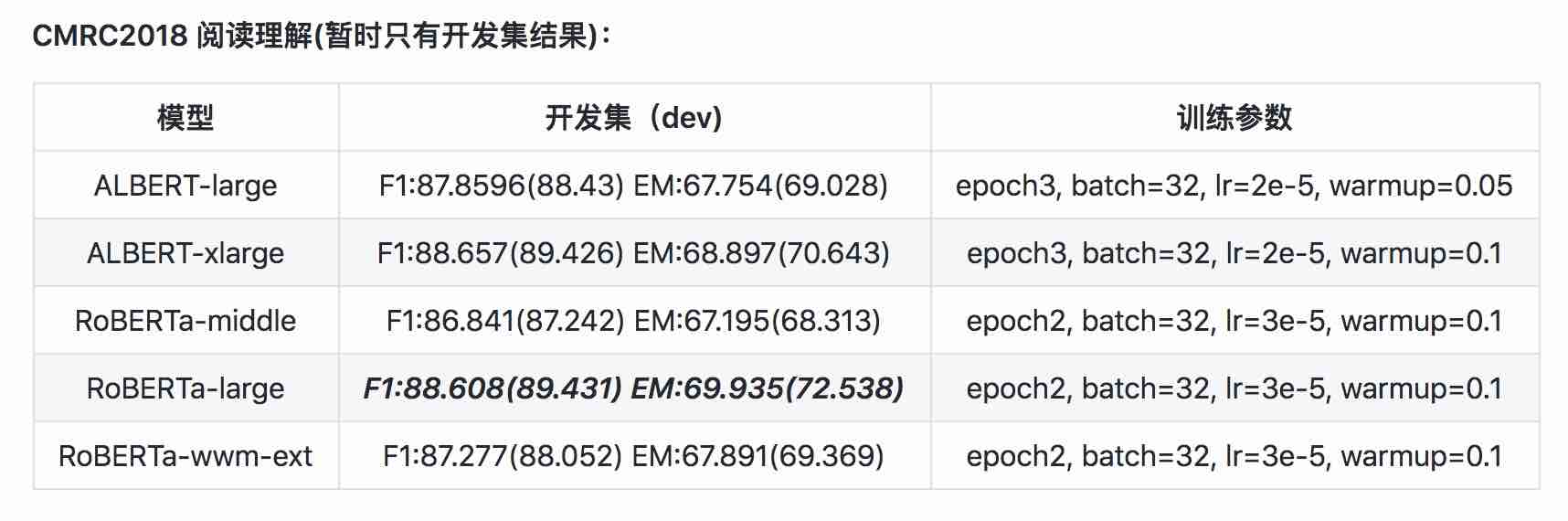
| Modelo | MLM EVALA ACC | SOP Eval ACC | Entrenamiento (horas) | EVELA DE Pérdida |
|---|---|---|---|---|
| albert_zh_base | 79.1% | 99.0% | 6h | 1.01 |
| albert_zh_large | 80.9% | 98.6% | 22.5h | 0.93 |
| albert_zh_xlarge | ? | ? | 53h (estimado) | ? |
| albert_zh_xxlarge | ? | ? | 106h (estimado) | ? |
Nota:? Será reemplazado pronto
Pruebe los principales puntos de mejora ejecutando los siguientes comandos, incluidos, entre otros, la factorización de los parámetros del vector de incrustación de palabras, el intercambio de parámetros de la capa cruzada, las tareas de continuidad del párrafo, etc.
python test_changes.py
Aquí presentamos principalmente la conversión del formato del modelo TFLITE y las pruebas de rendimiento. Después de convertir al modelo TFLITE, sobre cómo usar el modelo en el lado móvil, puede consultar la página completa del Tutorial del Caso de Desarrollo de Aplicaciones Android/IOS proporcionada por TFLITE. Esta página actualmente contiene dos casos de Android: clasificación de texto y preguntas y respuestas de texto.
El siguiente es un ejemplo para introducir la conversión del formato del modelo TFLITE y las pruebas de rendimiento:
Asegúrese de tener> = 1.14 1.x instalado para usar la herramienta Freeze_Graph ya que se elimina de 2.x Distribución
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
Vamos a usar el nuevo convertidor experimental TF-> TFlite que se distribuye con la construcción nocturna TensorFlow.
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
Vea aquí para obtener detalles sobre las herramientas de referencia de rendimiento en TFLITE. Por ejemplo: después de construir el binario de herramienta de referencia para un teléfono Android, haga lo siguiente para tener una idea de cómo funciona el modelo TFLITE en el teléfono
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
En un teléfono Android con el SoC SD845 de Qualcomm, a través de la herramienta de referencia anterior, a partir de 2019/11/01, la latencia de inferencia es de ~ 120 ms con este modelo TFLite convertido usando 4 hilos en la CPU, y el uso de la memoria es de ~ 60 MB para el modelo durante la inferencia. Tenga en cuenta que el rendimiento mejorará aún más con las futuras optimizaciones de implementación de Tflite.
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
Usando Albert_Pytorch
Bert4keras se adapta a Albert, que puede cargar con éxito el peso de Albert_Zh. Solo necesita agregar Albert = True a la función load_preetrainse_model.
Modelo de carga previamente capacitada con Bert4keras
bert-por-tf2
Descripción de la función: Los usuarios pueden usar este ejemplo para comprender cómo cargar el conjunto de capacitación para lograr un juicio de similitud de texto corto en función de la entrada del usuario. Según este código, puede expandir de manera flexible el programa a servicios de fondo o agregar clasificación de texto y otros ejemplos.
Código involucrado: Simility.py, args.py
paso:
1. Use este modelo para entrenar la similitud de texto y guardar el archivo del modelo en el directorio correspondiente.
2. Según la situación real, modifique los parámetros en Args.py. Los parámetros son los siguientes:
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )La estructura del archivo en este ejemplo es:
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. Modifique la palabra de entrada del usuario
Abra Simility.py y el siguiente código en la parte inferior:
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])donde sim.start_model () representa el modelo de carga, y la entrada de sim.predict_sentences es una serie de tuplas, y la tupla contiene dos elementos, oraciones que deben juzgarse de manera similar.
4. Ejecute el archivo Python: Simility.py
| Sistema | Longitud de SEQ | Tamaño de lote máximo |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - | - |
Si tiene alguna pregunta, puede plantear un problema o enviarme un correo electrónico: [email protected];
Actualmente, cómo usar la versión Pytorch de Albert aún no está clara, si sabe cómo hacerlo, simplemente envíenos un correo electrónico o abra un problema.
También puede enviar una solicitud de extracción para informar su rendimiento en su tarea o agregar métodos sobre cómo cargar modelos para Pytorch, etc.
Si tiene ideas para generar el mejor modelo chino de pre-entrenamiento de rendimiento, hágamelo saber.
Bright Liang Xu, Albert_Zh, (2019), Repositorio de Github, https://github.com/brightmart/albert_zh
1. Albert: A Lite Bert para el aprendizaje auto-supervisado de las representaciones del idioma
2. Bert: pretruamiento de transformadores bidireccionales profundos para la comprensión del lenguaje
3. Spanbert: Mejora de la capacitación al representar y predecir los tramos
4. Roberta: un enfoque de pre -proyenamiento de Bert optimizado robusto
5. Optimización de lotes grandes para el aprendizaje profundo: capacitación Bert en 76 minutos (cordero)
6. Optimizador de cordero, versión TensorFlow
7. Los modelos pequeños previamente capacitados también pueden ganar 13 tareas de PNL, y las tres principales transformaciones de Albert alcanzan la parte superior del punto de referencia de pegamento
8. Albert_pytorch
9. Cargue a Albert con keras
10. Cargue Albert con TF2.0
11. Repo de Albert de Google
12. Evaluación de referencia de tareas chino-vergés: tareas múltiples disponibles públicamente, modelos de referencia, evaluación extensa y comparación de efectos


