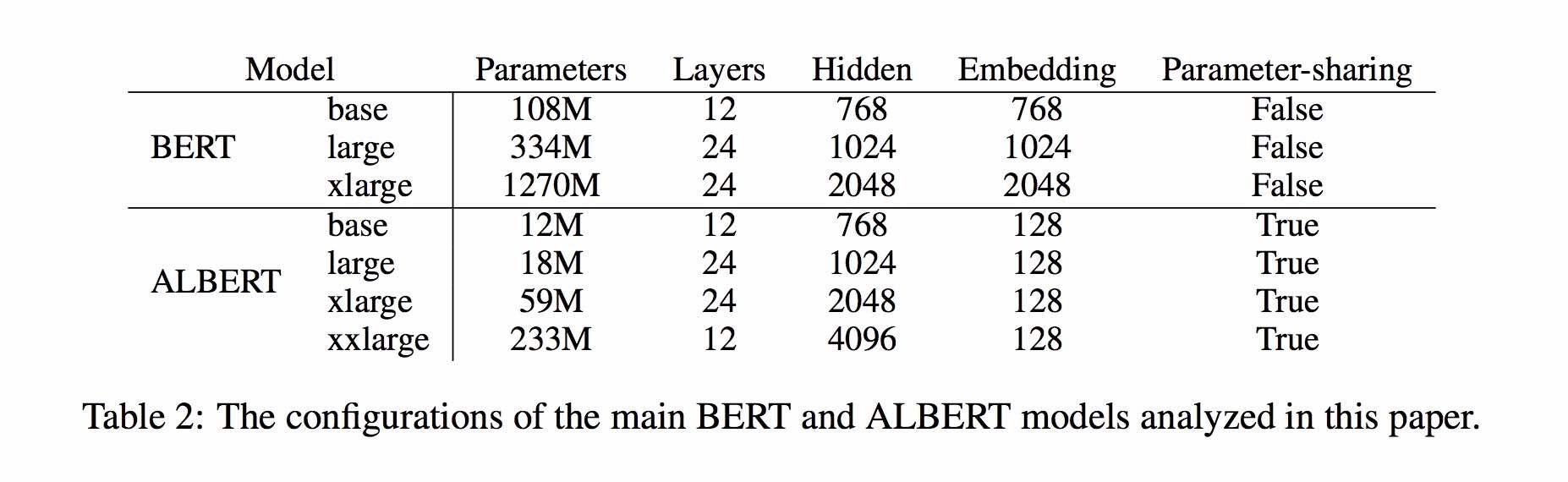
albert_zh
1.0.0
تنفيذ لايت بيرت لتمثيل لغة التعلم الخاضعة للرقابة مع TensorFlow
يعتمد ألبرت على بيرت ، ولكن مع بعض التحسينات. إنه يحقق أداءً أحدث الأداء على المعايير الرئيسية مع معلمات 30 ٪ أقل.
بالنسبة إلى Albert_base_zh ، فإنه يحتوي فقط على عشرة نسبة مئوية مقارنة بنموذج BERT الأصلي ، ويتم الاحتفاظ بالدقة الرئيسية.
نسخة مختلفة من نموذج ألبرت قبل التدريب للصينيين ، بما في ذلك TensorFlow و Pytorch و Keras ، متاح الآن.
نموذج ألبرت الذي تم تدريبه مسبقًا على مجموعة صينية ضخمة: عدد أقل من المعلمات ونتائج أفضل. يمكن للموديلات الصغيرة التي تم تدريبها مسبقًا الفوز بمهام NLP 13 ، وتصل التحولات الرئيسية الثلاثة لألبرت إلى قمة معيار الغراء
مجموعة أدوات Clueai: ثلاثة أسطر من التعليمات البرمجية ، تخصيص واجهة برمجة تطبيقات NLP في ثلاث دقائق (تعليم عينة صفر)

مقارنة مفصلة لتأثيرات النموذج على 10 مجموعات بيانات ، 9 نماذج أساسية ، ونقرة واحدة ، راجع دليل الدليل
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1. Albert_tiny_zh ، Albert_tiny_zh (التدريب لفترة أطول ، يتراكم 2 مليار عينة للتعلم) ، حجم الملف 16M ، المعلمة هي 4M
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. Albert_tiny_google_zh (التعلم التراكمي لـ 1 مليار عينة ، إصدار Google) ، حجم النموذج 16M ، الأداء يتوافق مع Albert_tiny_zh
1.2. albert_small_google_zh (التعلم التراكمي لـ 1 مليار عينة ، إصدار Google) ،
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
2. Albert_large_zh ، كمية المعلمة ، عدد الطبقات 24 ، حجم الملف هو 64 م
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3. albert_base_zh (تم تدريب 150 مليون حالة إضافية ، أي 36k خطوات * batch_size 4096) ؛ albert_base_zh (إصدار تجربة نموذج صغير) ، كمية المعلمة 12m ، عدد الطبقات 12 ، الحجم هو 40 مترًا
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. albert_xlarge_zh_177k ؛ albert_xlarge_zh_183k (أولوية المحاولة) كمية المعلمة ، عدد الطبقات 24 ، حجم الملف هو 230 متر
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
بالاعتماد على محولات Luggingface 2.2.2 ، يمكن استدعاء النماذج المذكورة أعلاه بسهولة.
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
القائمة المقابلة لـ MODEL_NAME هي كما يلي:
| اسم النموذج | model_name |
|---|---|
| albert_tiny_google_zh | voidful/albert_chinese_tiny |
| albert_small_google_zh | voidful/albert_chinese_small |
| albert_base_zh (من Google) | voidful/albert_chinese_base |
| Albert_large_zh (من Google) | voidful/albert_chinese_large |
| Albert_xlarge_zh (من Google) | voidful/albert_chinese_xlarge |
| Albert_xxlarge_zh (من Google) | voidful/albert_chinese_xxlarge |
المزيد من الأمثلة على استخدام ألبرت من خلال المحولات
تشغيل الأمر التالي تشغيل الأمر التالي. يحتوي المشروع تلقائيًا على ملف نصي مثال (بيانات/news_zh_1.txt)
bash create_pretrain_data.sh
إذا كان لديك العديد من الملفات النصية ، فيمكنك إنشاء ملفات متعددة من تنسيقات محددة عن طريق تمرير المعلمات (tfrecords)
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
استخدم Python3 + Tensorflow 1.x
مثل Tensorflow 1.4 أو 1.5
خذ باستخدام albert_base لمهام LCQMC كمثال. تتمثل مهمة LCQMC في جعل تنبؤات تشابه النص على مجموعة بيانات الوصف العام.
سنستخدم مجموعة بيانات LCQMC للضبط ، وهي مجموعة من اللغة الفموية ، وتستخدم لتدريب والتنبؤ بالتشابه الدلالي لزوج من الجمل.
قم بتنزيل مجموعة بيانات LCQMC ، والتي تحتوي على مجموعات التدريب والتحقق من الصحة والاختبار. تحتوي مجموعة التدريب على 240،000 زوج من الجملة الصينية مع أوصاف عامية ، مع ملصقات من 1 أو 0. 1 هو التشابه الدلالي الجملة ، و 0 يختلف الدلالي.
قم بالضبط على مجموعة بيانات LCQMC عن طريق تشغيل الأمر التالي:
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03: إضافة إصدار Google من Albert_small ، Albert_tiny ؛
أضف طريقة لنشر ABLERT_TINY على الأجهزة المحمولة مع وقت استنتاج 0.1 ثانية فقط لطول التسلسل 128 ، ذاكرة 60M ******
***** 2019-10-30: أضف دليلًا بسيطًا حول تحويل النموذج إلى Tensorflow Lite لنشر الحافة *****
***** 2019-10-15: Albert_tiny_zh ، بسرعة 10 مرات من قاعدة Bert للتدريب والاستدلال ، تظل الدقة *****
***** 2019-10-07: المزيد من نماذج ألبرت *****
إضافة albert_xlarge_zh ؛ albert_base_zh_additional_steps ، التدريب بمزيد من الحالات
***** 2019-10-04: تم دعم إصدارات Pytorch و Keras من Albert *****
A.Convert إلى إصدار Pytorch وقم بمهامك من خلال Albert_pytorch
B. تحميل نموذج مسبق مع keras باستخدام سطر واحد من الرموز من خلال Bert4keras
C. Use Albert مع TensorFlow 2.0: استخدام أو تحميل نموذج تدريب مسبقًا مع TF2.0 من خلال Bert-For-TF2
إطلاق albert_xlarge في السادس من أكتوبر
***** 2019-10-02: albert_large_zh ، albert_base_zh *****
تملي Albert_base_zh مع 10 ٪ فقط من معلمات Bert_Base ، يمكن أن يكون نموذج صغير (40 مترًا) والتدريب سريعًا للغاية.
Relared Albert_large_zh مع 16 ٪ فقط من معلمات Bert_Base (64 م)
***** 2019-09-28: الرموز ووظائف الاختبار *****
إضافة الرموز ووظائف الاختبار لثلاثة تغييرات رئيسية لألبرت من بيرت
نموذج ألبرت هو نسخة محسنة من Bert. على عكس النماذج الحديثة الأخرى للفن ، فإن هذه المرة هي نموذج صغير تم تدريبه مسبقًا ، مع نتائج أفضل وأقل من المعلمات.
لقد أجرت ثلاثة تغييرات على Bert ثلاثة تغييرات رئيسية لألبرت من Bert:
1) المعلمة المدمجة المعتمدة لمعلمات ناقلات تضمين الكلمات
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) مشاركة المعلمات عبر الطبقة
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) خسارة التماسك في استمرارية الفقرة.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
تغييرات أخرى:
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
30G الصينية مجموعة ، أكثر من 10 مليارات حرف صيني ، بما في ذلك موسوعات متعددة ، الأخبار ، والمجتمعات التفاعلية.
يتم تعيين تسلسل طول التسلسل المدربين قبل التدريب على 512 ، و Batch Batch_size هو 4096 ، ويولد التدريب 350 مليون بيانات تدريب (مثيل) ؛ سيقوم كل طراز بتدريب 125 كيلو خطوة افتراضيًا ، وسيتم تدريب Albert_xxlarge لفترة أطول.
للمقارنة ، أنشأ Roberta_zh التدريبي مسبقًا 250 مليون بيانات تدريب بطول تسلسل قدره 256. نظرًا لأن التدريب قبل Albert_ZH يولد المزيد من بيانات التدريب ويستخدم أطوال تسلسل أطول ،
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
يستخدم التدريب TPU V3 ، نحن نستخدم V3-256 ، والذي يحتوي على 32 V3-8S. يحتوي كل جهاز V3-8 على 128 جرام من ذاكرة الفيديو.
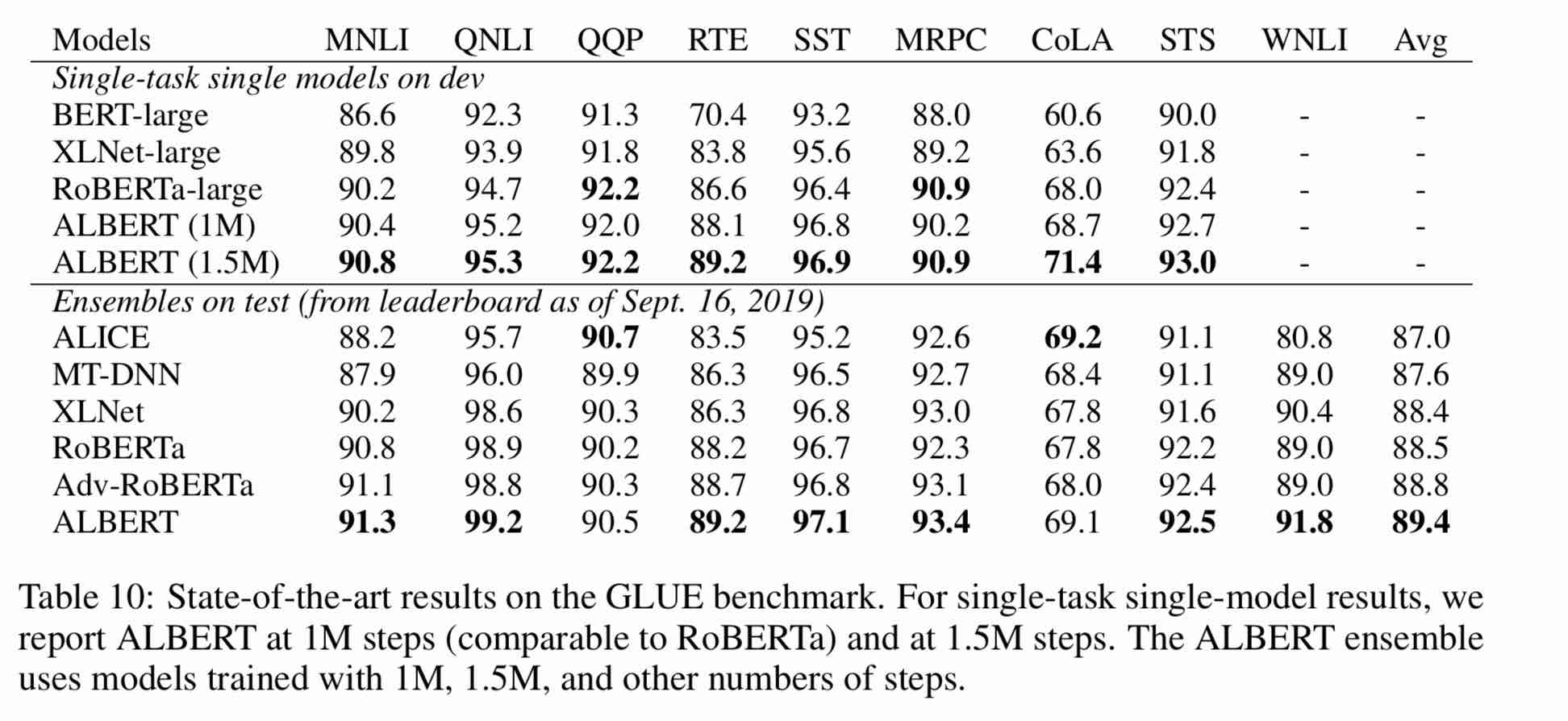
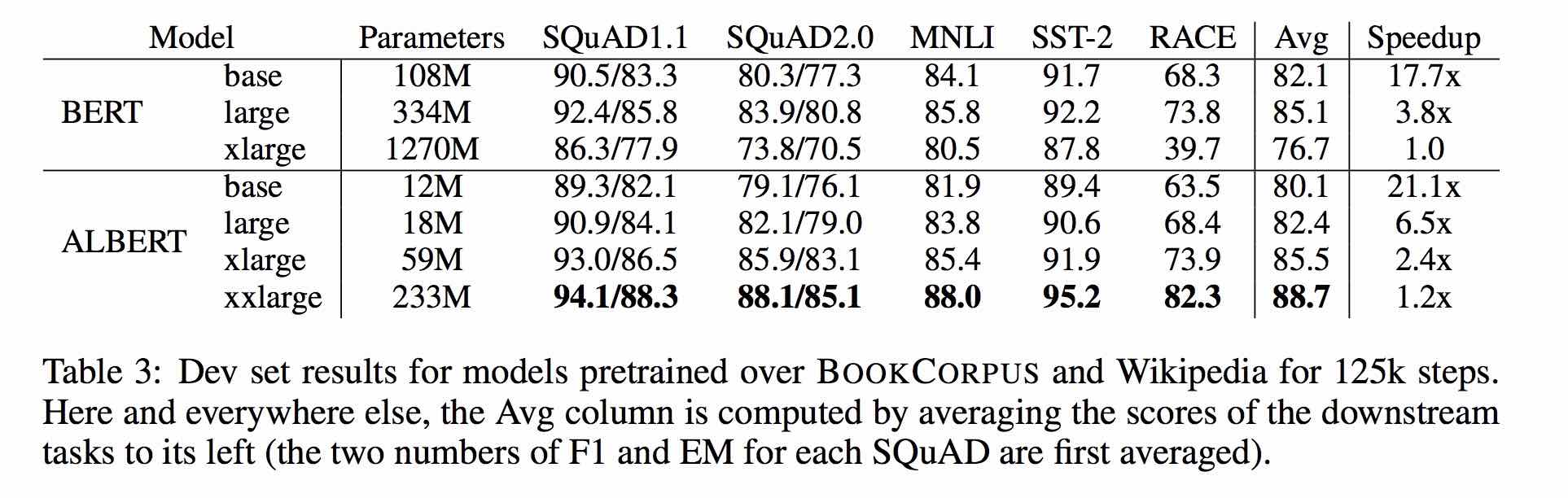
| نموذج | مجموعة التنمية (DEV) | مجموعة الاختبار (اختبار) |
|---|---|---|
| بيرت | 89.4 (88.4) | 86.9 (86.4) |
| إرني | 89.8 (89.6) | 87.2 (87.0) |
| بيرت وود | 89.4 (89.2) | 87.0 (86.8) |
| بيرت-WWM-EXT | - | - |
| روبرتا Zh-base | 88.7 | 87.0 |
| Roberta-Zh-Large | 89.9 (89.6) | 87.2 (86.7) |
| Roberta-Zh-Large (20W_Steps) | 89.7 | 87.0 |
| ألبرت زي تيني | - | 85.4 |
| Albert-Zh-Small | - | 86.0 |
| Albert-Zh-Small (Pytorch) | - | 86.8 |
| Albert-Zh-Base-Additional-36k-Steps | 87.8 | 86.3 |
| ألبرت Zh-base | 87.2 | 86.3 |
| ألبرت لارج | 88.7 | 87.1 |
| Albert-Xlarge | 87.3 | 87.7 |
ملاحظة: لقد ركضت فقط ألبرت Xlarge مرة واحدة ، وقد يتم تحسين التأثير
| نموذج | مجموعة التنمية | مجموعة الاختبار |
|---|---|---|
| بيرت | 77.8 (77.4) | 77.8 (77.5) |
| إرني | 79.7 (79.4) | 78.6 (78.2) |
| بيرت وود | 79.0 (78.4) | 78.2 (78.0) |
| بيرت-WWM-EXT | 79.4 (78.6) | 78.7 (78.3) |
| xlnet | 79.2 | 78.7 |
| روبرتا Zh-base | 79.8 | 78.8 |
| Roberta-Zh-Large | 80.2 (80.0) | 79.9 (79.5) |
| ألبرت-قاع | 77.0 | 77.1 |
| ألبرت لارج | 78.0 | 77.5 |
| Albert-Xlarge | ؟ | ؟ |
ملاحظة: يأتي Bert-WWM-Mex من هنا ؛ XLNET يأتي من هنا. يشير Roberta-Zh-Base إلى نموذج روبرتا الصيني المكون من 12 طبقة
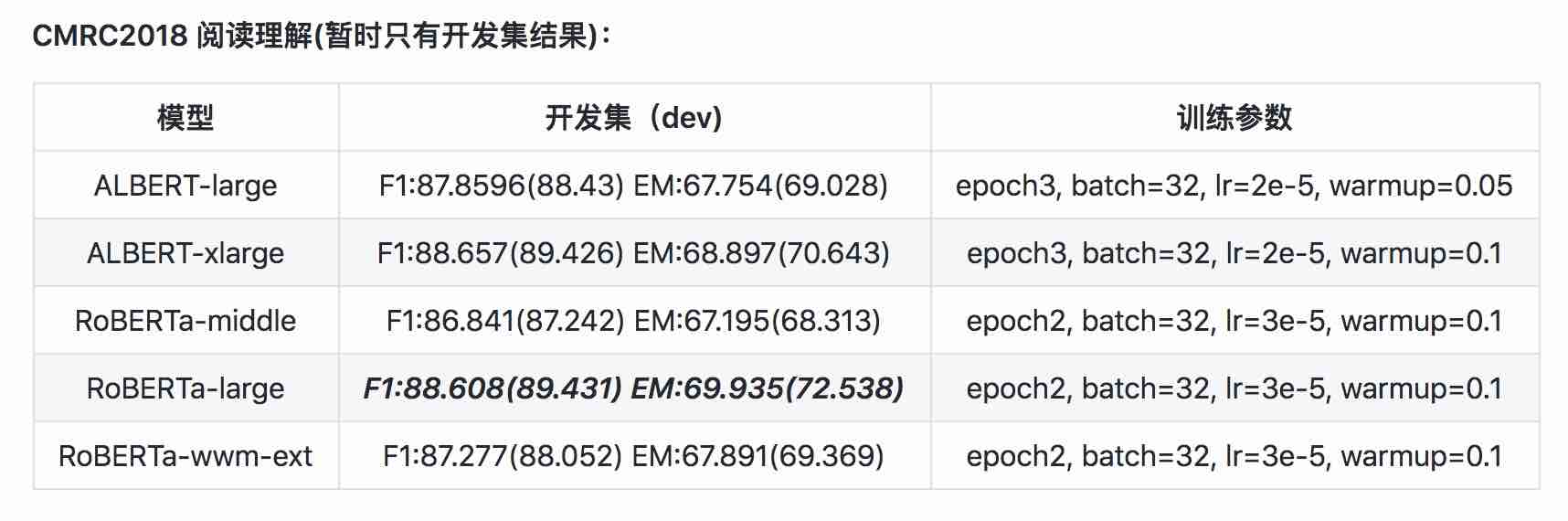
| نموذج | MLM eval acc | SOP eval acc | التدريب (ساعات) | فقدان الخسارة |
|---|---|---|---|---|
| Albert_zh_base | 79.1 ٪ | 99.0 ٪ | 6H | 1.01 |
| Albert_zh_large | 80.9 ٪ | 98.6 ٪ | 22.5H | 0.93 |
| Albert_zh_xlarge | ؟ | ؟ | 53H (المقدر) | ؟ |
| albert_zh_xxlarge | ؟ | ؟ | 106H (المقدر) | ؟ |
ملحوظة:؟ سيتم استبداله قريبًا
اختبر نقاط التحسين الرئيسية من خلال تشغيل الأوامر التالية ، بما في ذلك على سبيل المثال لا الحصر ، معلمة معلمات ناقلات تضمين الكلمات ، ومشاركة معلمات الطبقة عبر الطبقة ، ومهام استمرارية الفقرة ، إلخ.
python test_changes.py
هنا نقدم بشكل أساسي تحويل تنسيق نموذج Tflite واختبار الأداء. بعد التحويل إلى طراز Tflite ، لكيفية استخدام النموذج على جانب الهاتف المحمول ، يمكنك الرجوع إلى صفحة تعليمية تطوير تطبيق Android/iOS الكاملة التي توفرها Tflite. تحتوي هذه الصفحة حاليًا على حالتين Android: تصنيف النص ونص Q&A.
فيما يلي مثال لتقديم تحويل تنسيق نموذج Tflite واختبار الأداء:
تأكد من تثبيت> = 1.14 1.x مثبتة لاستخدام أداة freeze_graph حيث تتم إزالتها من توزيع 2.x
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
سوف نستخدم محول TF-> التجريبي الجديد TF-Tflite الذي يتم توزيعه مع بناء TensorFlow الليلي.
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
انظر هنا للحصول على تفاصيل حول الأدوات القياسية للأداء في Tflite. على سبيل المثال: بعد إنشاء أداة Benchmark Binary لهاتف Android ، قم بما يلي للحصول على فكرة عن كيفية أداء طراز Tflite على الهاتف
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
على هاتف Android w/ Qualcomm's SD845 SOC ، عبر الأداة القياسية المذكورة أعلاه ، اعتبارًا من 2019/11/01 ، يكون زمن الاستدلال ~ 120ms w/ هذا نموذج Tflite المحول باستخدام 4 مؤشرات ترابط على وحدة المعالجة المركزية ، واستخدام الذاكرة ~ 60 ميجابايت للنموذج أثناء الاستدلال. لاحظ أن الأداء سيتحسن مع تحسينات تنفيذ Tflite المستقبلية.
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
باستخدام Albert_pytorch
يتكيف Bert4keras مع Albert ، والذي يمكنه بنجاح تحميل وزن Albert_zh. تحتاج فقط إلى إضافة Albert = True إلى وظيفة LOAD_PREREDENT_MODEL.
تحميل نموذج مسبق المدرب مع Bert4keras
Bert-for-TF2
وصف الوظيفة: يمكن للمستخدمين استخدام هذا المثال لفهم كيفية تحميل مجموعة التدريب لتحقيق حكم تشابه نص قصير استنادًا إلى مدخلات المستخدم. استنادًا إلى هذا الرمز ، يمكنك توسيع البرنامج بمرونة إلى خدمات الخلفية أو إضافة تصنيف النص والأمثلة الأخرى.
الرمز المعني: التشابه .Py ، args.py
خطوة:
1. استخدم هذا النموذج لتدريب تشابه النص وحفظ ملف النموذج إلى الدليل المقابل.
2. وفقا للوضع الفعلي ، قم بتعديل المعلمات في args.py. المعلمات كما يلي:
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )بنية الملف في هذا المثال هي:
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. قم بتعديل كلمة إدخال المستخدم
افتح التشابه .Py ، والرمز التالي في الأسفل:
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])حيث يمثل Sim.Start_Model () نموذج التحميل ، ومدخلات sim.predict_sentences هي مجموعة من tuples ، ويحتوي tuple على عنصرين ، جمل يجب الحكم عليها.
4. تشغيل ملف Python: التشابه.
| نظام | طول SEQ | حجم الدُفعة القصوى |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - | - |
إذا كان لديك أي سؤال ، فيمكنك إثارة مشكلة ، أو إرسال بريد إلكتروني لي: [email protected] ؛
في الوقت الحالي ، لم يكن كيفية استخدام إصدار Pytorch من Albert واضحًا بعد ، إذا كنت تعرف كيفية القيام بذلك ، ما عليك سوى إرسال بريد إلكتروني إلينا أو فتح مشكلة.
يمكنك أيضًا إرسال طلب السحب للإبلاغ عن أدائك في مهمتك أو إضافة طرق حول كيفية تحميل النماذج لـ Pytorch وما إلى ذلك.
إذا كان لديك أفكار لتوليد أفضل نموذج للأداء قبل تدريب الصينية ، فيرجى إخبارنا أيضًا بذلك.
Bright Liang Xu ، Albert_zh ، (2019) ، github ropository ، https://github.com/brightmart/albert_zh
1. ألبرت: بيرت لايت للتعلم الخاضع للرقابة لتمثيل اللغة
2. بيرت: قبل التدريب من محولات ثنائية الاتجاه العميقة لفهم اللغة
3. Spanbert: تحسين التدريب المسبق من خلال تمثيل الفترات والتنبؤ بها
4.
5. تحسين الدُفعة الكبيرة للتعلم العميق: تدريب بيرت في 76 دقيقة (لحم الضأن)
6. Lamb Optimizer ، إصدار TensorFlow
7. يمكن للموديلات الصغيرة التي تم تدريبها مسبقًا الفوز بمهام NLP 13 ، وتصل التحولات الرئيسية الثلاثة لألبرت إلى قمة معيار الغراء
8. Albert_Pytorch
9. تحميل ألبرت مع keras
10. تحميل ألبرت مع TF2.0
11. ريبو ألبرت من جوجل
12. تقييم المهام الصينية الصينية الصينية: مهام متعددة متاحة للجمهور ، نماذج أساسية ، تقييم مكثف ومقارنة التأثير


