albert_zh
1.0.0
Implementasi Lite Bert untuk representasi bahasa pembelajaran sendiri dengan TensorFlow
Albert didasarkan pada Bert, tetapi dengan beberapa perbaikan. Ini mencapai kinerja canggih pada tolok ukur utama dengan parameter 30% lebih sedikit.
Untuk Albert_Base_Zh hanya memiliki sepuluh parameter persentase dibandingkan dengan model Bert asli, dan akurasi utama dipertahankan.
Versi berbeda dari model pra-terlatih Albert untuk Cina, termasuk TensorFlow, Pytorch dan Keras, tersedia sekarang.
Model Albert pra-terlatih pada korpus Cina besar-besaran: lebih sedikit parameter dan hasil yang lebih baik. Model kecil pra-terlatih juga dapat memenangkan 13 tugas NLP, dan tiga transformasi utama Albert mencapai bagian atas tolok ukur lem
Clueai Toolkit: Tiga Baris Kode, Kustomisasi API NLP dalam tiga menit (Pembelajaran Sampel Nol)

Perbandingan terperinci dari efek model pada 10 set data, 9 model baseline, dan satu klik, lihat Petunjuk Petunjuk
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1. Albert_tiny_zh, albert_tiny_zh (pelatihan lebih panjang, mengumpulkan 2 miliar sampel untuk dipelajari), ukuran file 16m, parameter adalah 4m
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. albert_tiny_google_zh (pembelajaran akumulatif dari 1 miliar sampel, versi Google), ukuran model 16m, kinerja konsisten dengan albert_tiny_zh
1.2. albert_small_google_zh (pembelajaran akumulatif dari 1 miliar sampel, versi Google),
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
2. Albert_large_zh, jumlah parameter, jumlah lapisan 24, ukuran file adalah 64m
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3. Albert_base_zh (tambahan 150 juta instance dilatih, mis. Langkah 36K * Batch_Size 4096); albert_base_zh (versi pengalaman model kecil), kuantitas parameter 12m, jumlah lapisan 12, ukuran adalah 40m
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. Albert_xlarge_zh_177k; albert_xlarge_zh_183k (prioritas coba) Jumlah parameter, jumlah lapisan 24, ukuran file adalah 230m
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
Mengandalkan pelukan-transformer face 2.2.2, model di atas dapat dengan mudah dipanggil.
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
Daftar MODEL_NAME yang sesuai adalah sebagai berikut:
| Nama model | Model_name |
|---|---|
| albert_tiny_google_zh | batal/albert_chinese_tiny |
| albert_small_google_zh | batal/albert_chinese_small |
| albert_base_zh (dari google) | batal/albert_chinese_base |
| Albert_large_zh (dari Google) | batal/albert_chinese_large |
| albert_xlarge_zh (dari google) | batal/albert_chinese_xlarge |
| albert_xxlarge_zh (dari google) | batal/albert_chinese_xxlarge |
Lebih banyak contoh menggunakan Albert melalui transformator
Jalankan perintah berikut, jalankan perintah berikut. Proyek secara otomatis memiliki contoh file teks (data/news_zh_1.txt)
bash create_pretrain_data.sh
Jika Anda memiliki banyak file teks, Anda dapat menghasilkan beberapa file dari format tertentu dengan meneruskan parameter (Tfrecords)
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
Gunakan Python3 + TensorFlow 1.x
misalnya TensorFlow 1.4 atau 1.5
Ambil menggunakan Albert_Base untuk tugas LCQMC sebagai contoh. Tugas LCQMC adalah membuat prediksi kesamaan teks pada dataset deskripsi sehari -hari.
Kami akan menggunakan dataset LCQMC untuk menyempurnakan, ini adalah corpus bahasa oral, digunakan untuk melatih dan memprediksi kesamaan semantik dari sepasang kalimat.
Unduh dataset LCQMC, yang berisi set pelatihan, validasi, dan tes. Set pelatihan berisi 240.000 pasangan kalimat Cina dengan deskripsi sehari -hari, dengan label 1 atau 0. 1 adalah kalimat kesamaan semantik, dan 0 adalah semantik berbeda.
Lakukan penyesuaian pada dataset LCQMC dengan menjalankan perintah berikut:
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03: Tambahkan versi Google dari Albert_small, Albert_tiny;
Tambahkan metode untuk menggunakan ablert_tiny ke perangkat seluler dengan hanya 0,1 waktu inferensi detik untuk panjang urutan 128, 60m memori ******
***** 2019-10-30: Tambahkan panduan sederhana tentang mengubah model ke tensorflow lite untuk penyebaran tepi *****
***** 2019-10-15: albert_tiny_zh, 10 kali cepat dari base Bert untuk pelatihan dan inferensi, akurasi tetap *****
***** 2019-10-07: Lebih Banyak Model Albert *****
Tambahkan Albert_xlarge_zh; albert_base_zh_additional_steps, pelatihan dengan lebih banyak contoh
***** 2019-10-04: Versi Pytorch dan Keras dari Albert didukung *****
A. Konversi ke versi pytorch dan lakukan tugas Anda melalui Albert_Pytorch
B. Muat model pra-terlatih dengan keras menggunakan satu baris kode melalui BerT4keras
C.Eing Albert dengan TensorFlow 2.0: Gunakan atau memuat model pra-terlatih dengan TF2.0 melalui BERT-FOR-TF2
Melepaskan Albert_xlarge pada 6 Oktober
***** 2019-10-02: albert_large_zh, albert_base_zh *****
Relesed albert_base_zh dengan hanya 10% parameter Bert_base, model kecil (40m) & pelatihan bisa sangat cepat.
Relas albert_large_zh dengan hanya 16% parameter Bert_base (64m)
***** 2019-09-28: Fungsi Kode dan Tes *****
Tambahkan kode dan fungsi tes untuk tiga perubahan utama Albert dari Bert
Model Albert adalah versi yang lebih baik dari Bert. Tidak seperti model seni terbaru lainnya, kali ini adalah model kecil pra-terlatih, dengan hasil yang lebih baik dan lebih sedikit parameter.
Ini telah membuat tiga perubahan pada Bert tiga perubahan utama Albert dari Bert:
1) Parameterisasi tertanam yang dimasukkan dari parameter vektor embedding kata
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) Berbagi parameter silang
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) Paragraf Kontinuitas Tugas Kehilangan Koherensi Antar-Kataran.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
Perubahan lainnya:
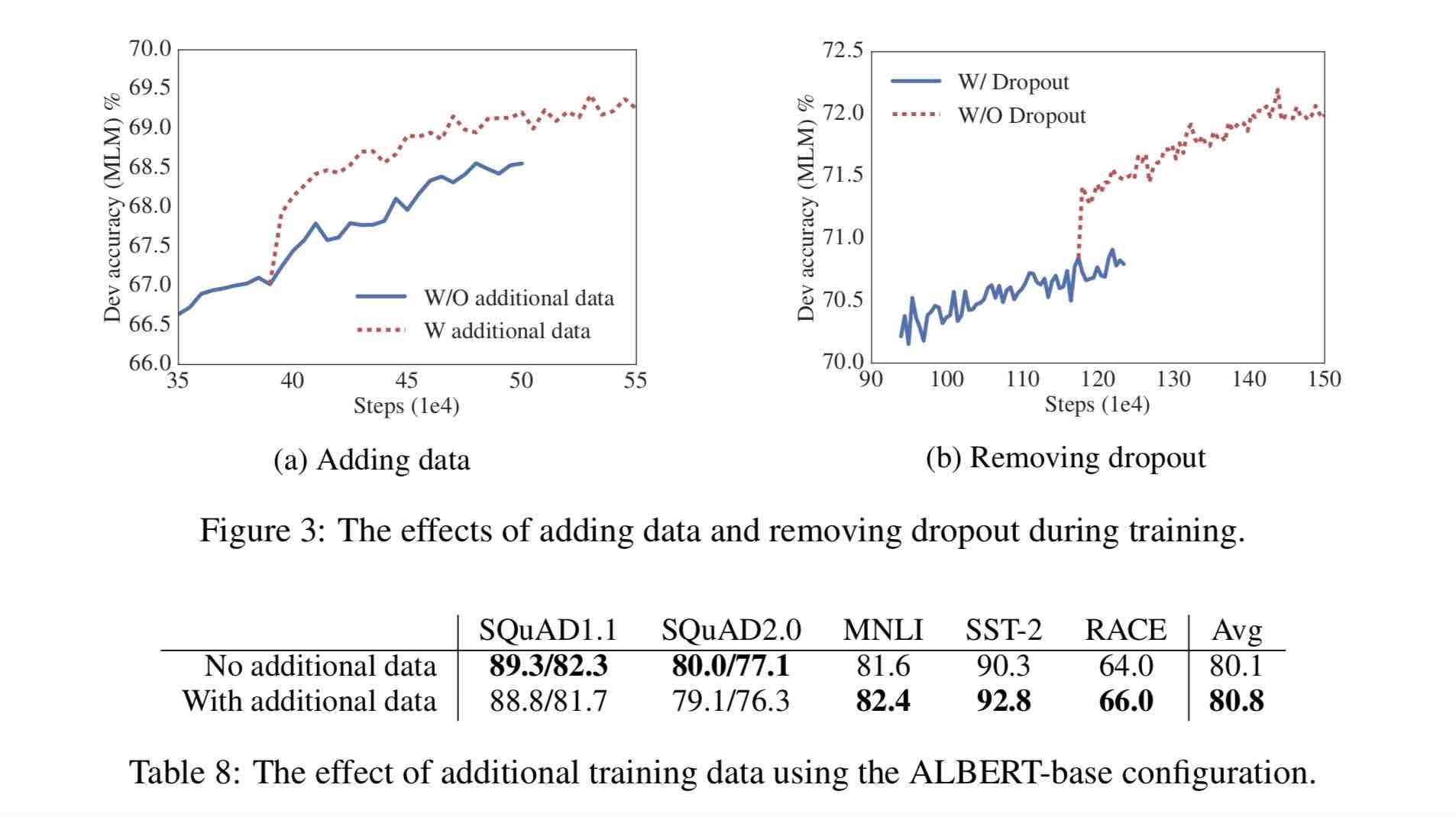
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
30G Corpus Cina, lebih dari 10 miliar karakter Cina, termasuk beberapa ensiklopedi, berita, dan komunitas interaktif.
Panjang urutan pra-terlatih Sequence_length diatur ke 512, batch batch_size adalah 4096, dan pelatihan menghasilkan 350 juta data pelatihan (contoh); Setiap model akan melatih langkah 125k secara default, dan Albert_xxlarge akan dilatih lebih lama.
Sebagai perbandingan, Roberta_Zh pra-pelatihan menghasilkan 250 juta data pelatihan dengan panjang urutan 256. Karena pra-pelatihan Albert_Zh menghasilkan lebih banyak data pelatihan dan menggunakan panjang urutan yang lebih lama,
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
Pelatihan menggunakan pod TPU V3, kami menggunakan V3-256, yang berisi 32 V3-8s. Setiap mesin V3-8 berisi 128g memori video.
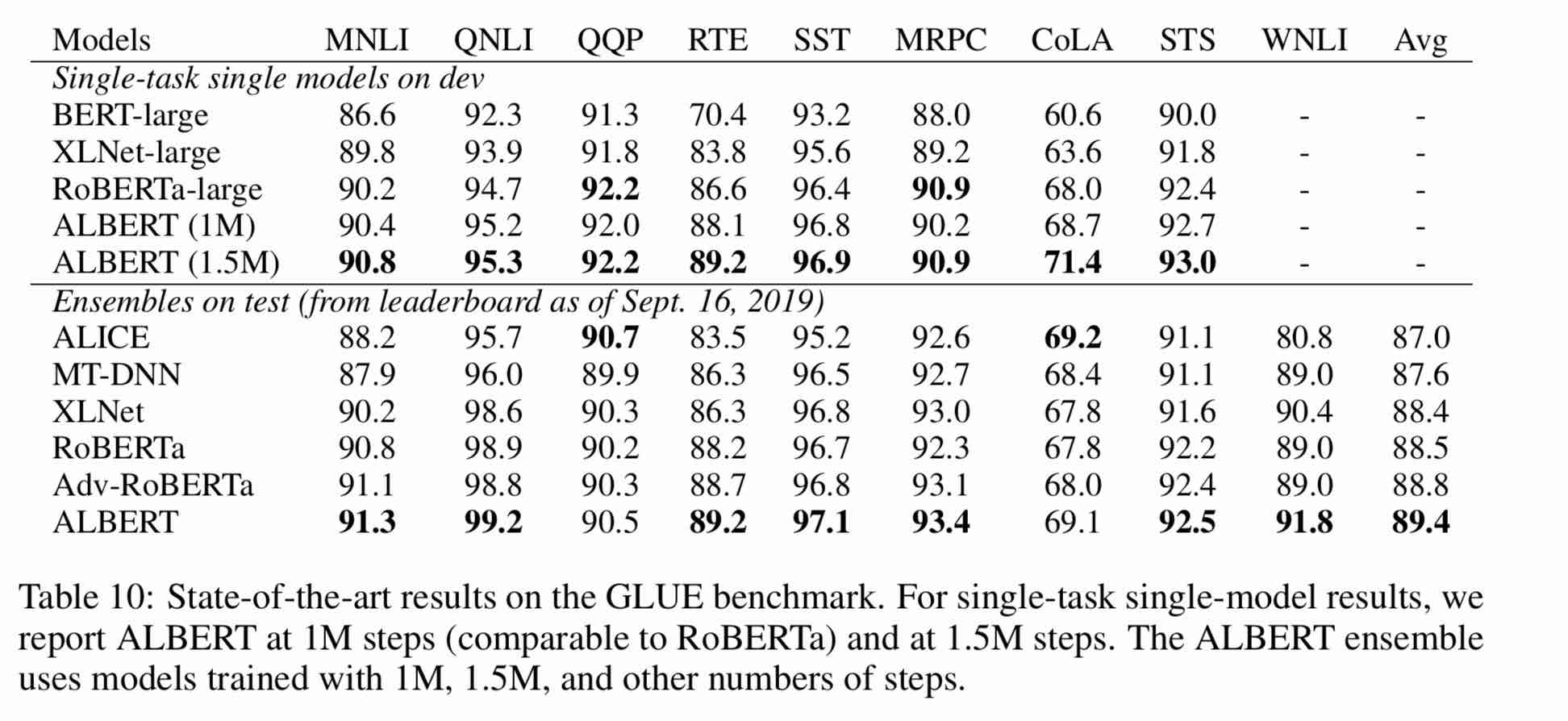
| Model | Set pengembangan (dev) | Set tes (tes) |
|---|---|---|
| Bert | 89.4 (88.4) | 86.9 (86.4) |
| Ernie | 89.8 (89.6) | 87.2 (87.0) |
| Bert-WWM | 89.4 (89.2) | 87.0 (86.8) |
| BERT-WWM-EXT | - | - |
| Roberta-Zh-Base | 88.7 | 87.0 |
| Roberta-Zh-Large | 89.9 (89.6) | 87.2 (86.7) |
| Roberta-Zh-Large (20W_Steps) | 89.7 | 87.0 |
| Albert-Zh-Tiny | - | 85.4 |
| Albert-Zh-Small | - | 86.0 |
| Albert-Zh-Small (Pytorch) | - | 86.8 |
| Albert-Zh-Base-Additional-36K-Steps | 87.8 | 86.3 |
| Albert-Zh-Base | 87.2 | 86.3 |
| Albert-Large | 88.7 | 87.1 |
| Albert-Xlarge | 87.3 | 87.7 |
Catatan: Saya hanya menjalankan Albert-Xlarge sekali, dan efeknya dapat ditingkatkan
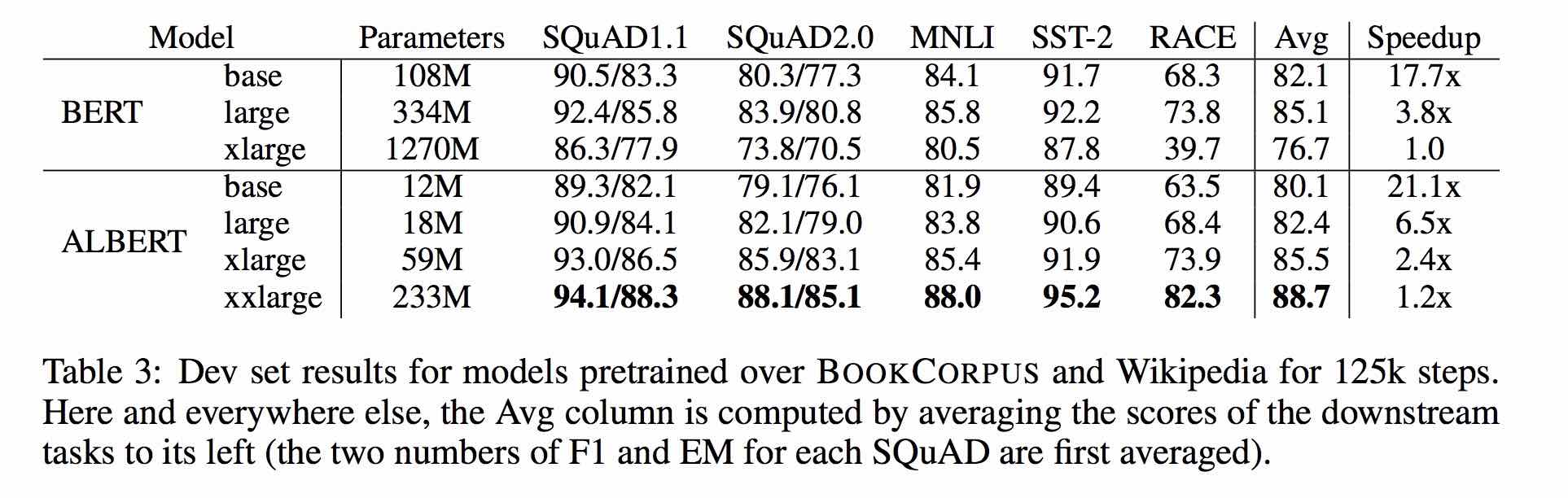
| Model | Set pengembangan | Set tes |
|---|---|---|
| Bert | 77.8 (77.4) | 77.8 (77.5) |
| Ernie | 79.7 (79.4) | 78.6 (78.2) |
| Bert-WWM | 79.0 (78.4) | 78.2 (78.0) |
| BERT-WWM-EXT | 79.4 (78.6) | 78.7 (78.3) |
| Xlnet | 79.2 | 78.7 |
| Roberta-Zh-Base | 79.8 | 78.8 |
| Roberta-Zh-Large | 80.2 (80.0) | 79.9 (79.5) |
| Albert-base | 77.0 | 77.1 |
| Albert-Large | 78.0 | 77.5 |
| Albert-Xlarge | ? | ? |
Catatan: Bert-wwm-ext berasal dari sini; Xlnet datang dari sini; Roberta-ZH-Base mengacu pada model 12-lapis Roberta Chinese
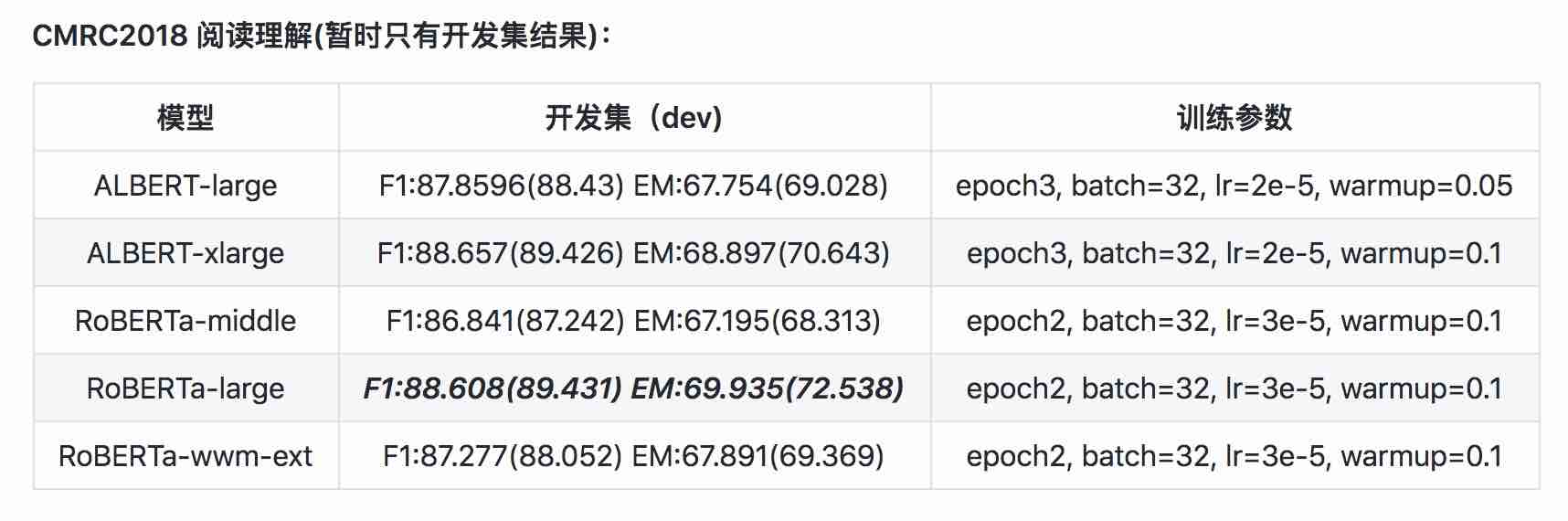
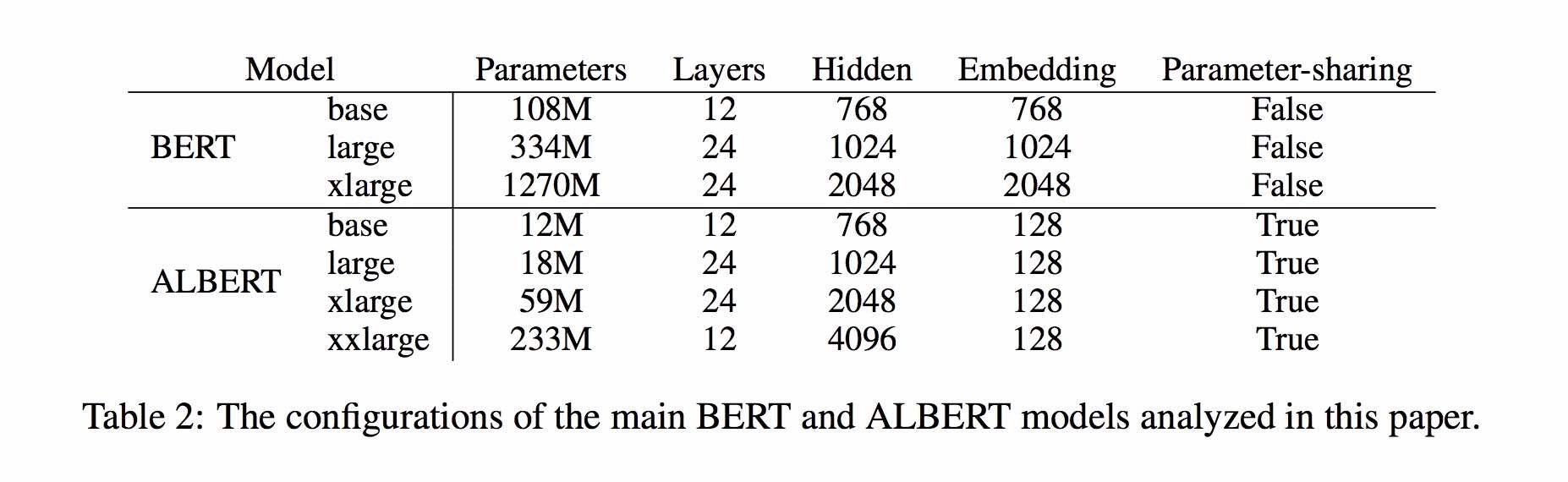
| Model | MLM Eval Acc | SOP EVAL ACC | Pelatihan (jam) | Evaluasi kerugian |
|---|---|---|---|---|
| albert_zh_base | 79,1% | 99,0% | 6h | 1.01 |
| albert_zh_large | 80,9% | 98,6% | 22.5H | 0.93 |
| albert_zh_xlarge | ? | ? | 53H (diperkirakan) | ? |
| albert_zh_xxlarge | ? | ? | 106h (diperkirakan) | ? |
Catatan:? Akan segera diganti
Uji titik peningkatan utama dengan menjalankan perintah berikut, termasuk tetapi tidak terbatas pada faktorisasi parameter vektor embedding kata, berbagi parameter cross-layer, tugas kontinuitas paragraf, dll.
python test_changes.py
Di sini kami terutama memperkenalkan konversi format model TFLITE dan pengujian kinerja. Setelah mengonversi ke model TFLITE, untuk cara menggunakan model di sisi seluler, Anda dapat merujuk pada halaman tutorial pengembangan aplikasi Android/iOS lengkap yang disediakan oleh TFLITE. Halaman ini saat ini berisi dua kasus Android: Klasifikasi Teks dan Tanya Jawab Teks.
Berikut ini adalah contoh untuk memperkenalkan konversi format model TFLITE dan pengujian kinerja:
Pastikan untuk memiliki> = 1.14 1.x terpasang untuk menggunakan alat freeze_graph saat dihapus dari distribusi 2.x
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
Kami akan menggunakan konverter eksperimental TF-> TFLITE yang baru didistribusikan dengan TensorFlow Nightly Build.
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
Lihat di sini untuk detail tentang alat benchmark kinerja di tflite. Misalnya: Setelah membangun biner alat benchmark untuk ponsel Android, lakukan hal berikut untuk mendapatkan gambaran tentang bagaimana kinerja model TFLITE di telepon
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
Pada ponsel Android dengan SD845 SoC Qualcomm, melalui alat benchmark di atas, pada 2019/11/01, latensi inferensi adalah ~ 120 ms dengan model TFLITE yang dikonversi ini menggunakan 4 utas pada CPU, dan penggunaan memori adalah ~ 60MB untuk model selama inferensi. Perhatikan kinerja akan meningkat lebih lanjut dengan optimasi implementasi TFLITE di masa depan.
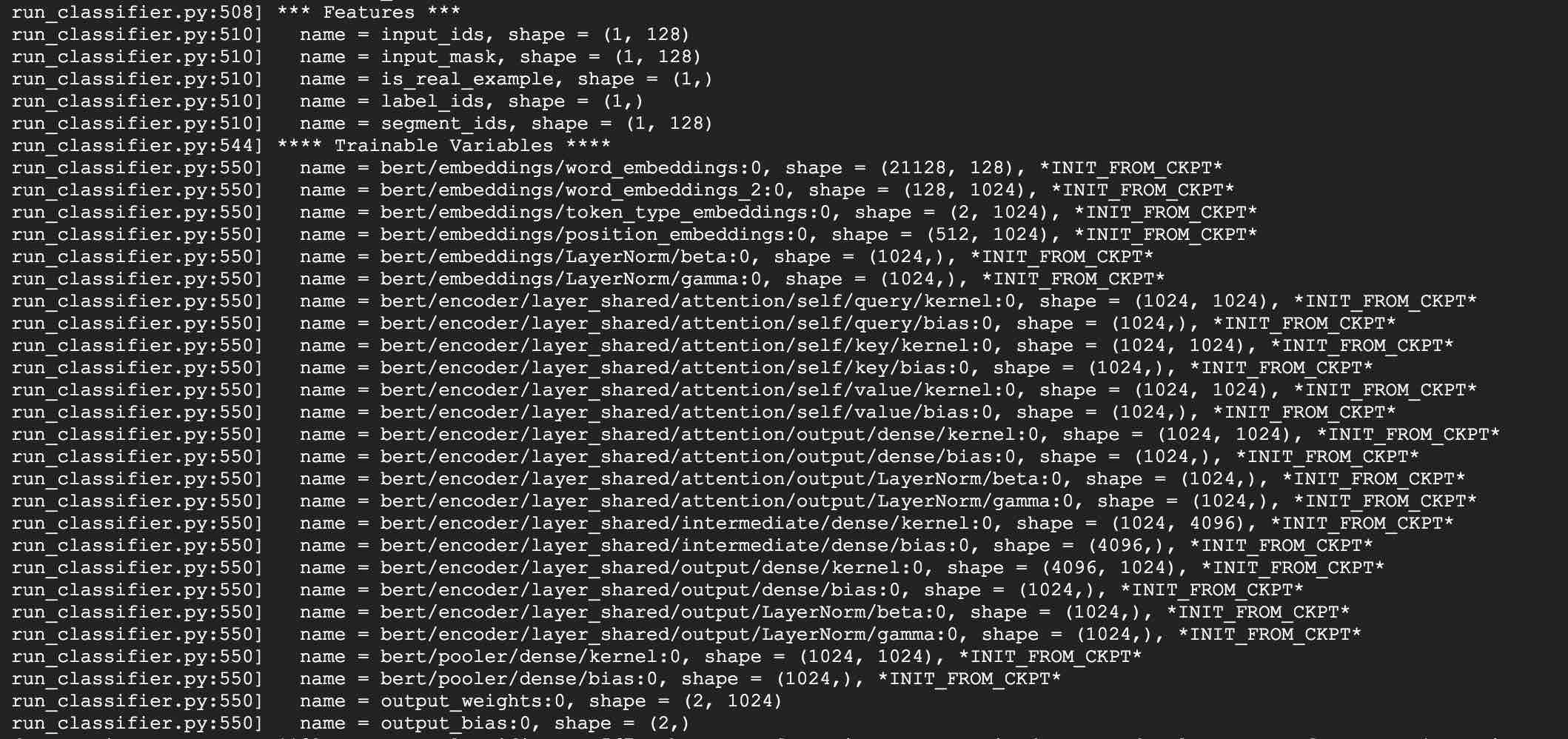
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
Menggunakan Albert_Pytorch
Bert4keras beradaptasi dengan Albert, yang dapat berhasil memuat berat Albert_zh. Anda hanya perlu menambahkan albert = benar ke fungsi load_pretrain_model.
Muat model pra-terlatih dengan BerT4keras
Bert-for-tf2
Deskripsi Fungsi: Pengguna dapat menggunakan contoh ini untuk memahami cara memuat set pelatihan untuk mencapai penilaian kesamaan teks pendek berdasarkan input pengguna. Berdasarkan kode ini, Anda dapat secara fleksibel memperluas program ke layanan latar belakang atau menambahkan klasifikasi teks dan contoh lainnya.
Kode yang terlibat: kesamaan.py, args.py
melangkah:
1. Gunakan model ini untuk melatih kesamaan teks dan menyimpan file model ke direktori yang sesuai.
2. Menurut situasi aktual, memodifikasi parameter di args.py. Parameternya adalah sebagai berikut:
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )Struktur file dalam contoh ini adalah:
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. Ubah kata input pengguna
Buka kesamaan.py, dan kode berikut di bagian bawah:
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])di mana sim.start_model () mewakili model pemuatan, dan input sim.predict_sentences adalah array tupel, dan tuple berisi dua elemen, kalimat yang perlu dinilai serupa.
4. Jalankan file python: kesamaan.py
| Sistem | Panjang seq | Ukuran batch maks |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - | - |
Jika Anda memiliki pertanyaan, Anda dapat mengangkat masalah, atau mengirimi saya email: [email protected];
Saat ini cara menggunakan versi Pytorch dari Albert belum jelas, jika Anda tahu cara melakukannya, cukup email kami atau buka masalah.
Anda juga dapat mengirim permintaan tarik untuk melaporkan kinerja Anda pada tugas Anda atau menambahkan metode tentang cara memuat model untuk pytorch dan sebagainya.
Jika Anda memiliki ide untuk menghasilkan model Cina pra-pelatihan kinerja terbaik, tolong beri tahu saya.
Bright Liang Xu, Albert_zh, (2019), Github Repository, https://github.com/brightmart/albert_zh
1. Albert: Lite Bert untuk pembelajaran representasi bahasa sendiri
2. Bert: Pra-pelatihan transformator dua arah yang dalam untuk pemahaman bahasa
3. Spanbert: Meningkatkan pra-pelatihan dengan mewakili dan memprediksi rentang
4. Roberta: Pendekatan pretraining Bert yang dioptimalkan dengan kuat
5. Optimalisasi Batch Besar untuk Pembelajaran mendalam: Pelatihan Bert dalam 76 menit (domba)
6. Pengoptimal Domba, Versi TensorFlow
7. Model kecil pra-terlatih juga dapat memenangkan 13 tugas NLP, dan tiga transformasi utama Albert mencapai bagian atas tolok ukur lem
8. Albert_Pytorch
9. Muat Albert dengan Keras
10. Muat Albert dengan TF2.0
11. Repo Albert dari Google
12. Evaluasi Benchmark Tugas Chineseglue-Chinese: Beberapa tugas yang tersedia untuk umum, model dasar, evaluasi yang luas dan perbandingan efek


