albert_zh
1.0.0
Eine Implementierung eines Lite Bert für selbstbewertete Lernsprache-Repräsentationen mit Tensorflow
Albert basiert auf Bert, aber mit einigen Verbesserungen. Es erreicht hochmoderne Performance auf den Hauptbenchmarks mit 30% igen Parametern.
Für Albert_Base_ZH hat es nur zehn Prozentsatzparameter im Vergleich zum ursprünglichen Bert -Modell, und die Hauptgenauigkeit wird beibehalten.
Eine unterschiedliche Version von Albert PreAned Model für Chinesen, einschließlich TensorFlow, Pytorch und Keras, ist ab sofort erhältlich.
Vorgebildetes Albert-Modell auf massivem chinesischem Korpus: weniger Parameter und bessere Ergebnisse. Vorausgebildete kleine Modelle können auch 13 NLP
ClueAai Toolkit: Drei Codezeilen, passen Sie eine NLP -API in drei Minuten an (Null -Beispiel -Lernen)

Ein detaillierter Vergleich der Modelleffekte auf 10 Datensätzen, 9 Basismodellen und One-Click-Lauf. Siehe Clue Benchmark
使用方式:
1、克隆项目
git clone https://github.com/brightmart/albert_zh.git
2、运行一键运行脚本(GPU方式): 会自动下载模型和所有任务数据并开始运行。
bash run_classifier_clue.sh
执行该一键运行脚本将会自动下载所有任务数据,并为所有任务找到最优模型,然后测试得到提交结果
1. Albert_tiny_zh, Albert_Tiny_Zh (länger trainieren, 2 Milliarden Proben zum Lernen ansammeln), Dateigröße 16m, Parameter 4m
训练和推理预测速度提升约10倍,精度基本保留,模型大小为bert的1/25;语义相似度数据集LCQMC测试集上达到85.4%,相比bert_base仅下降1.5个点。
lcqmc训练使用如下参数: --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
albert_tiny使用同样的大规模中文语料数据,层数仅为4层、hidden size等向量维度大幅减少; 尝试使用如下学习率来获得更好效果:{2e-5, 6e-5, 1e-4}
【使用场景】任务相对比较简单一些或实时性要求高的任务,如语义相似度等句子对任务、分类任务;比较难的任务如阅读理解等,可以使用其他大模型。
例如,可以使用[Tensorflow Lite](https://www.tensorflow.org/lite)在移动端进行部署,本文[随后](#use_tflite)针对这一点进行了介绍,包括如何把模型转换成Tensorflow Lite格式和对其进行性能测试等。
一键运行albert_tiny_zh(linux,lcqmc任务):
1) git clone https://github.com/brightmart/albert_zh
2) cd albert_zh
3) bash run_classifier_lcqmc.sh
1.1. ALBERT_TINY_GOOGLE_ZH (akkumulatives Lernen von 1 Milliarde Beispiele, Google -Version), Modellgröße 16m, Leistung stimmt mit Albert_Tiny_ZH überein
1.2. ALBERT_SMALL_GOOGLE_ZH (akkumulatives Lernen von 1 Milliarde Muster, Google -Version),
速度比bert_base快4倍;LCQMC测试集上比Bert下降仅0.9个点;去掉adam后模型大小18.5M;使用方法,见 #下游任务 Fine-tuning on Downstream Task
2. Albert_large_zh, Parametermenge, Anzahl der Ebenen 24, Dateigröße 64 m
参数量和模型大小为bert_base的六分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base上升0.2个点
3.. Albert_base_zh (weitere 150 Millionen Instanzen wurden trainiert, d. H. 36K -Schritte * batch_size 4096); ALBERT_BASE_ZH (kleine Modellerfahrung Version), Parametermenge 12m, Anzahl der Schichten 12, Größe 40 m
参数量为bert_base的十分之一,模型大小也十分之一;在口语化描述相似性数据集LCQMC的测试集上相比bert_base下降约0.6~1个点;
相比未预训练,albert_base提升14个点
4. Albert_xlarge_zh_177k; ALBERT_XLARGE_ZH_183K (Priority -Versuch) Parametermenge, Anzahl der Ebenen 24, Dateigröße 230 m
参数量和模型大小为bert_base的二分之一;需要一张大的显卡;完整测试对比将后续添加;batch_size不能太小,否则可能影响精度
Die oben genannten Modelle sind leicht aufgerufen.
tokenizer = AutoTokenizer.from_pretrained("MODEL_NAME")
model = AutoModel.from_pretrained("MODEL_NAME")
Die entsprechende Liste von MODEL_NAME lautet wie folgt:
| Modellname | Model_name |
|---|---|
| ALBERT_TINY_GOOGLE_ZH | voidful/Albert_chinese_tiny |
| ALBERT_SMALL_GOOGLE_ZH | voidful/Albert_Chinese_Small |
| ALBERT_BASE_ZH (von Google) | voidful/Albert_Chinese_base |
| ALBERT_LARGE_ZH (von Google) | voidful/Albert_chinese_large |
| ALBERT_XLARGE_ZH (von Google) | voidful/Albert_Chinese_xlarge |
| Albert_xxlarge_zh (von Google) | voidful/Albert_Chinese_xxlarge |
Weitere Beispiele für die Verwendung von Albert durch Transformatoren
Führen Sie den folgenden Befehl aus. Führen Sie den folgenden Befehl aus. Das Projekt verfügt automatisch über eine Beispieltextdatei (Daten/News_Zh_1.txt)
bash create_pretrain_data.sh
Wenn Sie viele Textdateien haben, können Sie mehrere Dateien mit bestimmten Formaten generieren, indem Sie Parameter (tFfrecords) übergeben, indem Sie übergeben werden, indem Sie bestimmte Dateien mit bestimmten Formaten übergeben.
If you are doing pre-train for english or other language,which is not chinese,
you should set hyperparameter of non_chinese to True on create_pretraining_data.py;
otherwise, by default it is doing chinese pre-train using whole word mask of chinese.
GPU(brightmart版, tiny模型):
export BERT_BASE_DIR=./albert_tiny_zh
nohup python3 run_pretraining.py --input_file=./data/tf*.tfrecord
--output_dir=./my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/albert_config_tiny.json
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=51
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
GPU(Google版本, small模型):
export BERT_BASE_DIR=./albert_small_zh_google
nohup python3 run_pretraining_google.py --input_file=./data/tf*.tfrecord --eval_batch_size=64
--output_dir=./my_new_model_path --do_train=True --do_eval=True --albert_config_file=$BERT_BASE_DIR/albert_config_small_google.json --export_dir=./my_new_model_path_export
--train_batch_size=4096 --max_seq_length=512 --max_predictions_per_seq=20
--num_train_steps=125000 --num_warmup_steps=12500 --learning_rate=0.00176
--save_checkpoints_steps=2000 --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt
TPU, add something like this:
--use_tpu=True --tpu_name=grpc://10.240.1.66:8470 --tpu_zone=us-central1-a
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,根据数据的大小,可以不用训练特别久。
Verwenden Sie Python3 + TensorFlow 1.x
zB Tensorflow 1.4 oder 1.5
Nehmen Sie als Beispiel mit Albert_Base für LCQMC -Aufgaben. Die LCQMC -Aufgabe besteht darin, die Vorhersagen der Textähnlichkeit in einem umgangssprachlichen Beschreibungsdatensatz vorzunehmen.
Wir werden den LCQMC-Datensatz für die Feinabstimmung verwenden, es ist oraler Sprachkorpus, es wird verwendet, um die semantische Ähnlichkeit eines Sätze zu trainieren und vorherzusagen.
Laden Sie den LCQMC -Datensatz herunter, der Schulungs-, Validierungs- und Testsätze enthält. Das Trainingssatz enthält 240.000 chinesische Satzpaare mit umgangssprachlichen Beschreibungen mit Etiketten von 1 oder 0. 1 ist eine semantische Ähnlichkeit, und 0 ist semantisch unterschiedlich.
Führen Sie die Feinabstimmung im LCQMC-Datensatz durch, indem Sie den folgenden Befehl ausführen:
1. Clone this project:
git clone https://github.com/brightmart/albert_zh.git
2. Fine-tuning by running the following command.
brightmart版本的tiny模型
export BERT_BASE_DIR=./albert_tiny_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--bert_config_file=./albert_config/albert_config_tiny.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
google版本的small模型
export BERT_BASE_DIR=./albert_small_zh
export TEXT_DIR=./lcqmc
nohup python3 run_classifier_sp_google.py --task_name=lcqmc_pair --do_train=true --do_eval=true --data_dir=$TEXT_DIR --vocab_file=./albert_config/vocab.txt
--albert_config_file=./$BERT_BASE_DIR/albert_config_small_google.json --max_seq_length=128 --train_batch_size=64 --learning_rate=1e-4 --num_train_epochs=5
--output_dir=./albert_lcqmc_checkpoints --init_checkpoint=$BERT_BASE_DIR/albert_model.ckpt &
Notice/注:
1) you need to download pre-trained chinese albert model, and also download LCQMC dataset
你需要下载预训练的模型,并放入到项目当前项目,假设目录名称为albert_tiny_zh; 需要下载LCQMC数据集,并放入到当前项目,
假设数据集目录名称为lcqmc
2) for Fine-tuning, you can try to add small percentage of dropout(e.g. 0.1) by changing parameters of
attention_probs_dropout_prob & hidden_dropout_prob on albert_config_xxx.json. By default, we set dropout as zero.
3) you can try different learning rate {2e-5, 6e-5, 1e-4} for better performance
****** 2019-11-03: Fügen Sie die Google-Version von Albert_Small, Albert_Tiny hinzu;
Fügen Sie die Methode hinzu, um abert_tiny auf mobilen Geräten mit nur 0,1 Sekundenschlusszeit für die Sequenzlänge 128, 60 m Speicher ***** zu bereitstellen. ******
***** 2019-10-30: Fügen Sie eine einfache Anleitung zum Konvertieren des Modells in den Tensorflow Lite für die Edge-Bereitstellung hinzu *****
!
***** 2019-10-07: Weitere Modelle von Albert *****
fügen Sie Albert_xlarge_ZH hinzu; ALBERT_BASE_ZH_ADDITIONAL_STEPS, Training mit weiteren Instanzen
***** 2019-10-04: Pytorch- und Keras-Versionen von Albert wurden unterstützt *****
A.Convert to Pytorch -Version und erledigen Sie Ihre Aufgaben über Albert_Pytorch
B. Laden Sie vorgebildetes Modell mit Keras mit einer Codes-Zeile über Bert4keras
C. Use Albert mit TensorFlow 2.0: Verwenden oder laden Sie vorgebildetes Modell mit TF2.0 über Bert-for-TF2
Veröffentlichung von Albert_xlarge am 6. Oktober
***** 2019-10-02: Albert_large_zh, Albert_Base_ZH *****
Relessed albert_base_zh mit nur 10% Parametern von Bert_base, einem kleinen Modell (40 m) und dem Training kann sehr schnell sein.
Relued Albert_Large_ZH mit nur 16% -Parametern von Bert_base (64 m)
***** 2019-09-28: Codes und Testfunktionen *****
Fügen Sie Codes und Testfunktionen für drei Hauptänderungen von Albert von Bert hinzu
Das Albert -Modell ist eine verbesserte Version von Bert. Im Gegensatz zu anderen neueren Modellen der Kunst handelt es sich um ein vorgebildetes kleines Modell mit besseren Ergebnissen und weniger Parametern.
Es hat drei Änderungen an Bert drei Hauptänderungen von Albert von Bert vorgenommen:
1) Faktorisierte eingebettete Parametrisierung von Wortbettungsvektorparametern
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
2) Target der Verschleppungsparameter
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
3) Absatzkontinuitätsaufgabe Inter-Sentenzkohärenzverlust.
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
We maintain that inter-sentence modeling is an important aspect of language understanding, but we propose a loss
based primarily on coherence. That is, for ALBERT, we use a sentence-order prediction (SOP) loss, which avoids topic
prediction and instead focuses on modeling inter-sentence coherence. The SOP loss uses as positive examples the
same technique as BERT (two consecutive segments from the same document), and as negative examples the same two
consecutive segments but with their order swapped. This forces the model to learn finer-grained distinctions about
discourse-level coherence properties.
Andere Änderungen:
1)去掉了dropout Remove dropout to enlarge capacity of model.
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
(dropout可以认为是随机的去掉网络中的一部分,同时使网络变小一些)
We also note that, even after training for 1M steps, our largest models still do not overfit to their training data.
As a result, we decide to remove dropout to further increase our model capacity.
其他型号的模型,在我们的实现中我们还是会保留原始的dropout的比例,防止模型对训练数据的过拟合。
2)为加快训练速度,使用LAMB做为优化器 Use LAMB as optimizer, to train with big batch size
使用了大的batch_size来训练(4096)。 LAMB优化器使得我们可以训练,特别大的批次batch_size,如高达6万。
3)使用n-gram(uni-gram,bi-gram, tri-gram)来做遮蔽语言模型 Use n-gram as make language model
即以不同的概率使用n-gram,uni-gram的概率最大,bi-gram其次,tri-gram概率最小。
本项目中目前使用的是在中文上做whole word mask,稍后会更新一下与n-gram mask的效果对比。n-gram从spanBERT中来。
30G Chinese Corpus, mehr als 10 Milliarden chinesische Charaktere, darunter mehrere Enzyklopädien, Nachrichten und interaktive Gemeinschaften.
Die vorgebreitete Sequenzlängensequence_Length ist auf 512 eingestellt, die Batch-Batch_size beträgt 4096 und das Training generiert 350 Millionen Trainingsdaten (Instanz). Jedes Modell trainiert standardmäßig 125K -Schritte und Albert_xxlarge wird länger geschult.
Zum Vergleich hat Roberta_Zh Pre-Training 250 Millionen Trainingsdaten mit einer Sequenzlänge von 256 generiert. Seit Albert_Zh Pre-Training mehr Trainingsdaten generiert und längere Sequenzlängen verwendet.
我们预计albert_zh会有比roberta_zh更好的性能表现,并且能更好处理较长的文本。
Das Training verwendet TPU V3 POD, wir verwenden v3-256, das 32 V3-8s enthält. Jede V3-8-Maschine enthält 128 g Videospeicher.
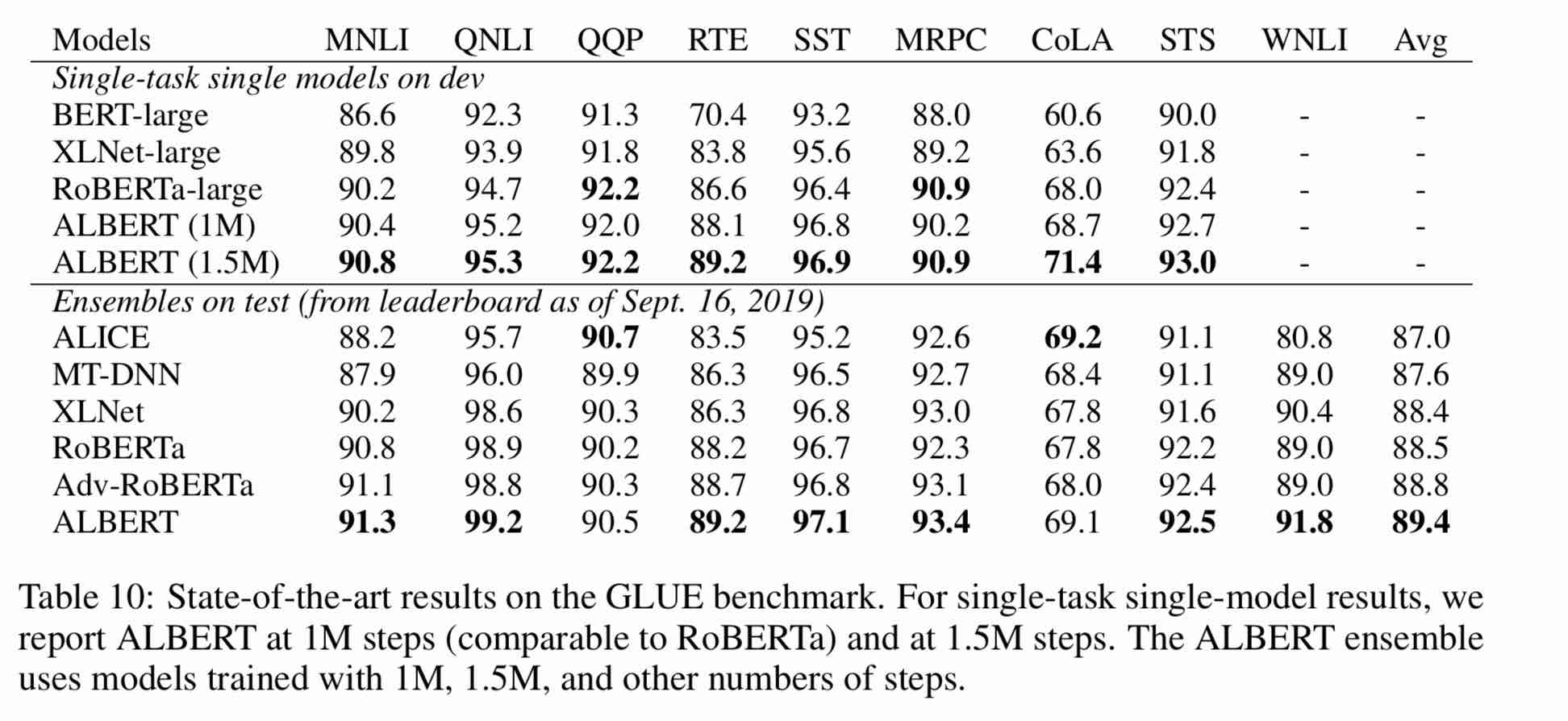
| Modell | Entwicklungssatz (Dev) | Testsatz (Test) |
|---|---|---|
| Bert | 89,4 (88,4) | 86,9 (86,4) |
| Ernie | 89,8 (89,6) | 87,2 (87,0) |
| Bert-wwm | 89,4 (89,2) | 87,0 (86,8) |
| Bert-wwm-ot | - - | - - |
| Roberta-Zh-Base | 88.7 | 87.0 |
| Roberta-Zh-Large | 89,9 (89,6) | 87,2 (86,7) |
| Roberta-Zh-Large (20W_steps) | 89.7 | 87.0 |
| Albert-Zh-Tiny | - | 85.4 |
| Albert-Zh-Small | - | 86.0 |
| Albert-Zh-Small (Pytorch) | - | 86,8 |
| Albert-Zh-Base-Additional-36K-Steps | 87,8 | 86,3 |
| Albert-Zh-Base | 87,2 | 86,3 |
| Albert-Large | 88.7 | 87.1 |
| Albert-Xlarge | 87,3 | 87.7 |
Hinweis: Ich habe nur einmal Albert-Xlarge gelaufen, und der Effekt kann verbessert werden
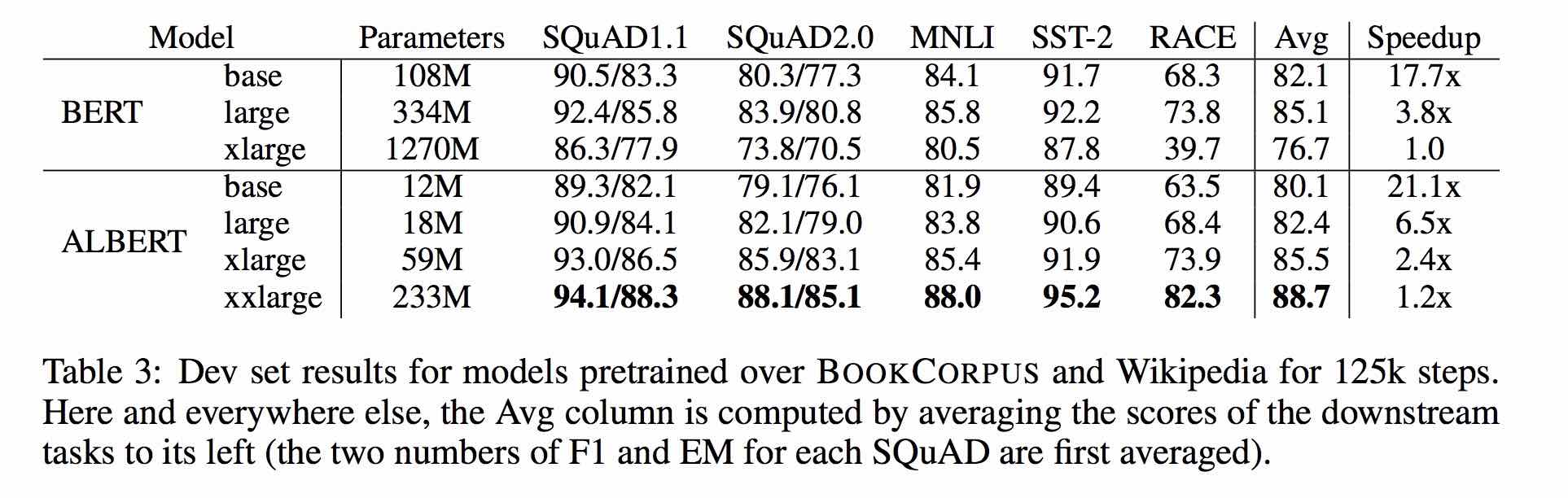
| Modell | Entwicklungsset | Testset |
|---|---|---|
| Bert | 77,8 (77,4) | 77,8 (77,5) |
| Ernie | 79,7 (79,4) | 78,6 (78,2) |
| Bert-wwm | 79,0 (78,4) | 78,2 (78,0) |
| Bert-wwm-ot | 79,4 (78,6) | 78,7 (78,3) |
| Xlnet | 79,2 | 78,7 |
| Roberta-Zh-Base | 79,8 | 78,8 |
| Roberta-Zh-Large | 80.2 (80.0) | 79,9 (79,5) |
| Albert-Base | 77.0 | 77.1 |
| Albert-Large | 78.0 | 77,5 |
| Albert-Xlarge | ? | ? |
HINWEIS: Bert-wwm-ot kommt von hier; Xlnet kommt von hier; Roberta-Zh-Base bezieht sich auf das 12-layerer Roberta Chinese Model
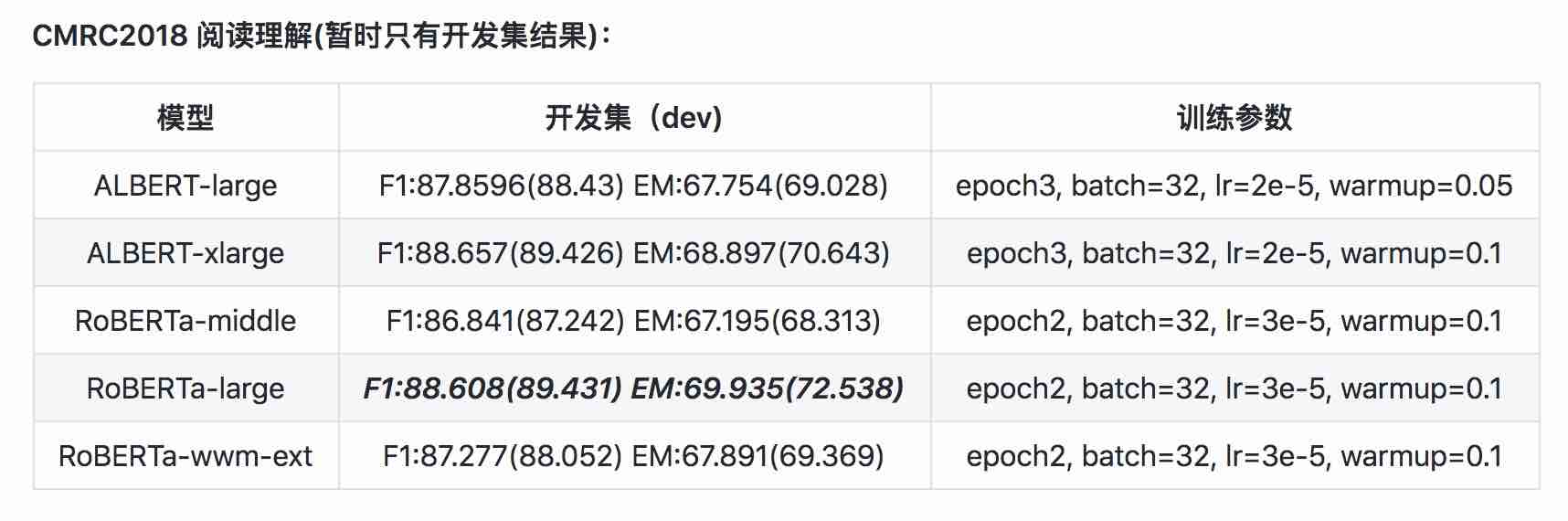
| Modell | MLM eval ACC | Sop eval ACC | Training (Stunden) | Verlust eval |
|---|---|---|---|---|
| ALBERT_ZH_BASE | 79,1% | 99,0% | 6h | 1.01 |
| ALBERT_ZH_LARGE | 80,9% | 98,6% | 22.5H | 0,93 |
| ALBERT_ZH_XLARGE | ? | ? | 53H (geschätzt) | ? |
| ALBERT_ZH_XXLARGE | ? | ? | 106H (geschätzt) | ? |
Notiz:? Wird bald ersetzt
Testen Sie die Hauptverbesserungspunkte, indem Sie die folgenden Befehle ausführen, einschließlich, aber nicht beschränkt auf die Faktorisierung von Worteinbettungsvektorparametern, die Freigabe von Cross-Layer-Parametern, Absatzkontinuitätsaufgaben usw.
python test_changes.py
Hier führen wir hauptsächlich TFLite -Modellformatkonvertierung und Leistungstests ein. Nach dem Konvertieren in das TFLite -Modell können Sie die von Tflite bereitgestellte Tutorial -Tutorial -Tutorial -Tutorial -Tutorial -Tutorial -Tutorial -Tutorial -Tutorial -Tutorial auf das TFLite -Modell konvertiert. Diese Seite enthält derzeit zwei Android -Fälle: Textklassifizierung und Text und a.
Das Folgende ist ein Beispiel, um die Konvertierung und Leistungstest für TFLite -Modellformat einzuführen:
Stellen Sie sicherzustellen
pip install tensorflow==1.15
freeze_graph --input_checkpoint=./albert_model.ckpt
--output_graph=/tmp/albert_tiny_zh.pb
--output_node_names=cls/predictions/truediv
--checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true
Wir werden den neuen experimentellen TF-> TFLITE-Konverter verwenden, der mit dem TensorFlow Nightly Build verteilt ist.
pip install tf-nightly
tflite_convert --graph_def_file=/tmp/albert_tiny_zh.pb
--input_arrays='input_ids,input_mask,segment_ids,masked_lm_positions,masked_lm_ids,masked_lm_weights'
--output_arrays='cls/predictions/truediv'
--input_shapes=1,128:1,128:128:1,128:1,128:1,128
--output_file=/tmp/albert_tiny_zh.tflite
--enable_v1_converter --experimental_new_converter
Weitere Informationen zu den Leistungsbenchmark -Tools in Tflite finden Sie hier. Zum Beispiel: Nachdem Sie das Benchmark -Tool Binary für ein Android -Telefon erstellt haben, machen Sie Folgendes, um eine Vorstellung davon zu erhalten
adb push /tmp/albert_tiny_zh.tflite /data/local/tmp/
adb shell /data/local/tmp/benchmark_model_performance_options --graph=/data/local/tmp/albert_tiny_zh.tflite --perf_options_list=cpu
Auf einem Android -Telefon mit SD845 SOC von Qualcomm über das obige Benchmark -Tool beträgt die Inferenzlatenz ab 2019/11/01 ~ 120 ms mit diesem konvertierten TFLite -Modell mit 4 Threads auf der CPU, und die Speicherverwendung beträgt ~ 60 MB für das Modell während der Inferenz. Beachten Sie, dass sich die Leistung mit zukünftigen Optimierungen der TFLite -Implementierung weiter verbessern wird.
download pre-trained model, and convert to PyTorch using:
python convert_albert_tf_checkpoint_to_pytorch.py
mit Albert_Pytorch
Bert4keras passt sich an Albert an, was das Gewicht von Albert_Zh erfolgreich laden kann. Sie müssen nur Albert = true zur Funktion load_pretraed_model hinzufügen.
Last vorgebildetem Modell mit Bert4keras
Bert-für-TF2
Funktionsbeschreibung: Benutzer können dieses Beispiel verwenden, um zu verstehen, wie das Trainingssatz geladen werden kann, um eine kurze Textähnlichkeitsbeurteilung auf der Grundlage der Benutzereingabe zu erhalten. Basierend auf diesem Code können Sie das Programm flexibel auf Hintergrunddienste erweitern oder Textklassifizierung und andere Beispiele hinzufügen.
Code beteiligte: Ähnlichkeit.py, args.py
Schritt:
1. Verwenden Sie dieses Modell, um die Ähnlichkeit des Textes zu trainieren und die Modelldatei in dem entsprechenden Verzeichnis zu speichern.
2. Ändern Sie gemäß der tatsächlichen Situation die Parameter in args.py. Die Parameter sind wie folgt:
#模型目录,存放ckpt文件
model_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#config文件,存放模型的json文件
config_name = os . path . join ( file_path , 'albert_config/albert_config_tiny.json' )
#ckpt文件名称
ckpt_name = os . path . join ( model_dir , 'model.ckpt' )
#输出文件目录,训练时的模型输出目录
output_dir = os . path . join ( file_path , 'albert_lcqmc_checkpoints/' )
#vocab文件目录
vocab_file = os . path . join ( file_path , 'albert_config/vocab.txt' )
#数据目录,训练使用的数据集存放目录
data_dir = os . path . join ( file_path , 'data/' )Die Dateistruktur in diesem Beispiel lautet:
|__args.py
|__similarity.py
|__data
|__albert_config
|__albert_lcqmc_checkpoints
|__lcqmc
3. Ändern Sie das Benutzereingabegeld
Öffnen Sie die Ähnlichkeit.py und der folgende Code unten:
if __name__ == '__main__' :
sim = BertSim ()
sim . start_model ()
sim . predict_sentences ([( "我喜欢妈妈做的汤" , "妈妈做的汤我很喜欢喝" )])wobei Sim.Start_Model () das Lademodell darstellt, und die Eingabe von SIM.PREDICT_SENTENCE ist ein Array von Tupeln, und das Tupel enthält zwei Elemente, Sätze, die ähnlich beurteilt werden müssen.
4. Führen Sie die Python -Datei aus: Ähnlichkeit.py
| System | SEQ Länge | Max Batchgröße |
|---|---|---|
albert-base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
albert-large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
albert-xlarge | - - | - - |
Wenn Sie eine Frage haben, können Sie ein Problem aufwerfen oder mir eine E -Mail senden: [email protected];
Derzeit ist die Verwendung von Pytorch -Version von Albert noch nicht klar. Wenn Sie wissen, wie das geht, senden Sie uns einfach eine E -Mail oder öffnen Sie ein Problem.
Sie können auch die Pull -Anfrage senden, um Ihre Leistung in Ihrer Aufgabe zu melden oder Methoden zum Laden von Modellen für Pytorch und so weiter hinzuzufügen.
Wenn Sie Ideen für die Generierung des chinesischen Modells vor dem Training für die beste Leistung haben, lassen Sie es mich bitte auch wissen.
Bright Liang XU, Albert_Zh, (2019), Github Repository, https://github.com/brightmart/albert_zh
1..
2. Bert: Vorausbildung von tiefen bidirektionalen Transformatoren für das Sprachverständnis
3. Spanbert: Verbesserung der Vorausbildung durch Vertretung und Vorhersage von Spannweiten
4..
5. Große Chargenoptimierung für Deep Learning: Training Bert in 76 Minuten (Lamm)
6. Lammoptimierer, Tensorflow -Version
7. Vorausgebildete kleine Modelle können auch 13 NLP
8. Albert_Pytorch
9. Albert mit Keras laden
10. Albert mit TF2.0 beladen
11. Repo von Albert von Google
12. Bewertung des chinesischen Klebers-chinesischen Task-Benchmarks: öffentlich verfügbare mehrere Aufgaben, Basismodelle, umfangreiche Bewertung und Effektvergleich


