micronet
1.0.0
"ในปัจจุบันมีโรงเรียนสองแห่งในด้านการเรียนรู้อย่างลึกซึ้งแห่งหนึ่งคือโรงเรียนวิชาการซึ่งศึกษาเครือข่ายแบบจำลองที่มีประสิทธิภาพและซับซ้อนและวิธีการทดลองเพื่อให้ได้ประสิทธิภาพที่สูงขึ้น การเพิ่มขนาดของเครือข่ายประสาทลึกได้นำความท้าทายอย่างมากมาสู่การปรับใช้การเรียนรู้อย่างลึกซึ้งในสถานีเคลื่อนที่และการบีบอัดรูปแบบการเรียนรู้อย่างลึกซึ้งและการปรับใช้ได้กลายเป็นหนึ่งในพื้นที่การวิจัยที่ทั้งสถาบันการศึกษาและอุตสาหกรรมได้มุ่งเน้นไปที่ "
Microt การบีบอัดแบบจำลองและปรับใช้ LIB
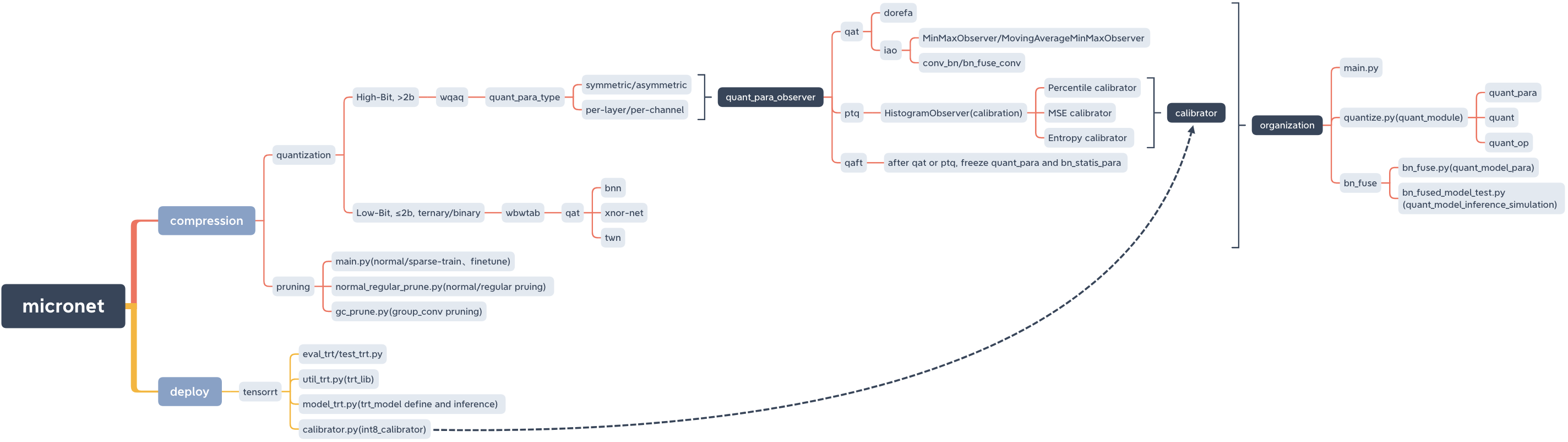
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
Pypi
pip install micronet -i https://pypi.org/simpleคนอื่น ๆ
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py installตรวจสอบ
python -c " import micronet; print(micronet.__version__) " ติดตั้งจาก GitHub
-รีฟินสามารถโหลดพารามิเตอร์แบบจำลองจุดลอยตัวล่วงหน้าและหาปริมาณตามพวกเขาตามพวกเขา
-W-A, Weight W และมีค่าเชิงปริมาณ
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32-w_bits-a_bits น้ำหนัก w และมีจำนวนบิตเชิงปริมาณ
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoการเลือกตัวเลขหลักเช่นเดียวกับ Dorefa
การ์ดใบเดียว
qat/ptq -> qaft
- โปรดทราบว่าคุณต้องทำ QAFT หลังจาก QAT/PTQ!
-q_type, ประเภทปริมาณ (0-symmetric, 1-symmetric)
-q_level, ระดับน้ำหนัก (ระดับ 0 ช่อง, 1 ระดับ)
-Weight_observer, Weight_observer Selection (0-Minmaxobserver, 1-movingaverageminmaxobserver)
-BN_FUSE, BN Fusion Flag ในปริมาณ
-BN_FUSE_CALIB, BN Fusion Calibration Mark ใน Quantization
-pretrained_model, โมเดลจุดลอยตัวล่วงหน้า
-Qaft, Qaft Flag
-ptq, ptq_observer
-ptq_control, ptq_control
-ptq_batch จำนวนแบทช์ของ PTQ
-อัตราส่วนการสอบเทียบ PTQ
ไส้
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPTQ
ต้องโหลดโมเดลจุดลอยตัวที่ผ่านการฝึกอบรมมาแล้วซึ่งสามารถรับได้โดยการฝึกอบรมปกติในการตัดแต่งกิ่ง
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999qaft
- โปรดทราบว่าคุณต้องทำ QAFT หลังจาก QAT/PTQ!
qat -> qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001ptq -> qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqการฝึกอบรมแบบกระจัดกระจาย -> การตัดแต่ง -> การปรับที่ดี
cd micronet/compression/pruning-SR SPARSE SIGN
-อัตราเบาบาง (ต้องปรับตามชุดข้อมูลและเงื่อนไขของโมเดล)
-ประเภทรุ่น Model_type (0-NIN, 1-NIN_GC)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1-อัตราการตัดแต่งกิ่ง
-normal_regular ปกติธงการตัดแต่งกิ่งปกติและฐานการตัดแต่งกิ่งปกติ (ถ้าตั้งค่าเป็น n จำนวนตัวกรองต่อเลเยอร์ของแบบจำลองหลังจากการตัดแต่งกิ่งมีหลาย N)
-โมเดลเส้นทางโมเดลหลังจากการฝึกอบรมแบบเบาบาง
-บันทึกเส้นทางโมเดลที่บันทึกไว้หลังจากการตัดแต่ง (เส้นทางได้รับโดยค่าเริ่มต้นและสามารถเปลี่ยนแปลงได้ตามสถานการณ์จริง)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthหรือ
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth-PRUNE_REFINE เส้นทางโมเดลหลังจากการตัดแต่ง (ปรับแต่งตามมัน)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pthคุณต้องผ่าน CFG ของรุ่นใหม่ที่ได้รับหลังจาก การตัดแต่ง
ชอบ
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584โหลดโมเดลจุดลอยตัวแบบตัดแต่ง
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoqat/ptq -> qaft
- โปรดทราบว่าคุณต้องทำ QAFT หลังจาก QAT/PTQ!
ไส้
BN ไม่ได้ฟิวชั่น
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001PTQ
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999qaft
- โปรดทราบว่าคุณต้องทำ QAFT หลังจาก QAT/PTQ!
qat -> qaft
BN ไม่ได้ฟิวชั่น
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001ptq -> qaft
BN ไม่ได้ฟิวชั่น
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse-MODEL_TYPE, 1 -NIN_GC (รวมถึงโครงสร้าง convolutional ที่จัดกลุ่ม); 0 - NIN (โครงสร้าง convolutional ปกติ)
-PRUNE_QUANT, FLAG MODEL PRONING_QUANTITATIT
-W, ค่าปริมาณการวัดน้ำหนัก
ทั้งหมดจำเป็นต้องสอดคล้องกับการฝึกอบรมเชิงปริมาณและคุณสามารถใช้ค่าเริ่มต้นโดยตรง
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test-MODEL_TYPE, 1 -NIN_GC (รวมถึงโครงสร้าง convolutional ที่จัดกลุ่ม); 0 - NIN (โครงสร้าง convolutional ปกติ)
-PRUNE_QUANT, FLAG MODEL PRONING_QUANTITATIT
--w_bits, จำนวนปริมาณบิต; -a_bits, จำนวนการเปิดใช้งานจำนวนบิต
ทั้งหมดจำเป็นต้องสอดคล้องกับการฝึกอบรมเชิงปริมาณและคุณสามารถใช้ค่าเริ่มต้นโดยตรง
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.pyโปรดทราบว่าเมื่อต้องมีการตั้งค่าการฝึกอบรมเชิงปริมาณ -BN_FUSE
cd micronet/compression/quantization/wqaq/iao/bn_fuse-MODEL_TYPE, 1 -NIN_GC (รวมถึงโครงสร้าง convolutional ที่จัดกลุ่ม); 0 - NIN (โครงสร้าง convolutional ปกติ)
-PRUNE_QUANT, FLAG MODEL PRONING_QUANTITATIT
--w_bits, จำนวนปริมาณบิต; -a_bits, จำนวนการเปิดใช้งานจำนวนบิต
-q_type, 0 -symmetric; 1 - ไม่สมมาตร
-q_level, 0 -ระดับช่อง; 1 - ระดับ
ทั้งหมดจำเป็นต้องสอดคล้องกับการฝึกอบรมเชิงปริมาณและคุณสามารถใช้ค่าเริ่มต้นโดยตรง
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pyตอนนี้รองรับ CPU และ GPU (การ์ดใบเดียวการ์ดหลายใบ)
-CPU ใช้ CPU,-GPU_ID ใช้และเลือก GPU
python main.py --cpupython main.py --gpu_id 0หรือ
python main.py --gpu_id 1python main.py --gpu_id 0,1หรือ
python main.py --gpu_id 0,1,2โดยค่าเริ่มต้นให้ใช้การ์ดเต็มเซิร์ฟเวอร์
ขณะนี้มีเฉพาะรหัส โมดูลหลัก ที่เกี่ยวข้องเท่านั้นและจะมีการเพิ่มการสาธิตที่สมบูรณ์แบบในภายหลัง
แบบจำลองสามารถวัดปริมาณได้ (สูงบิต (> 2B), ต่ำบิต (≤2b)/เทิร์นรีและไบนารี) โดยเพียงแค่แทนที่ OP ด้วย Quant_OP
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )แบบจำลองสามารถวัดปริมาณได้ (สูง (> 2B), ต่ำบิต (≤2b)/ternary และไบนารี) เพียงแค่ใช้ micronet.compression.quantization.quantize.prepare (รุ่น)
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "เมื่อเอาท์พุท "Quant_Model พร้อม" Microt ก็พร้อม
การอ้างอิง BN Fusion และการทดสอบการอนุมานเชิงปริมาณ
ต่อไปนี้เป็นตัวอย่าง CIFAR10 ที่คุณสามารถลองใช้วิธีการบีบอัดแบบรวมอื่น ๆ ในรุ่นที่ซ้ำซ้อนมากขึ้นและชุดข้อมูลขนาดใหญ่ขึ้น
| พิมพ์ | W (บิต) | A (บิต) | ACC | gflops | Para (M) | ขนาด (MB) | อัตราการบีบอัด | การสูญเสีย |
|---|---|---|---|---|---|---|---|---|
| โมเดลต้นฉบับ (NIN) | fp32 | fp32 | 91.01% | 0.15 | 0.67 | 2.68 | - | - |
| การใช้โครงสร้างการรวมกลุ่ม (NIN_GC) | fp32 | fp32 | 91.04% | 0.15 | 0.58 | 2.32 | 13.43% | -0.03% |
| การตัดแต่ง | fp32 | fp32 | 90.26% | 0.09 | 0.32 | 1.28 | 52.24% | 0.75% |
| การหาปริมาณ | 1 | fp32 | 90.93% | - | 0.58 | 0.204 | 92.39% | 0.08% |
| การหาปริมาณ | 1.5 | fp32 | 91% | - | 0.58 | 0.272 | 89.85% | 0.01% |
| การหาปริมาณ | 1 | 1 | 86.23% | - | 0.58 | 0.204 | 92.39% | 4.78% |
| การหาปริมาณ | 1.5 | 1 | 86.48% | - | 0.58 | 0.272 | 89.85% | 4.53% |
| ปริมาณ (Dorefa) | 8 | 8 | 91.03% | - | 0.58 | 0.596 | 77.76% | -0.02% |
| ปริมาณ (IAO, ปริมาณเต็ม, สมมาตร/ต่อช่องทาง/BN_FUSE) | 8 | 8 | 90.99% | - | 0.58 | 0.596 | 77.76% | 0.02% |
| การจัดกลุ่ม + การตัดแต่งกิ่ง + quantization | 1.5 | 1 | 86.13% | - | 0.32 | 0.19 | 92.91% | 4.88% |
-train_batch_size 256, การ์ดใบเดียว
BinarizedNeuralNetWorks: TrainingNeuralNetworks withweights และ activationsConstrained to +1 หรือ 1
xnor-net: imagenetclassi fi cusingbinary convolutionalneuralnetworks
การศึกษาเชิงประจักษ์ของการเพิ่มประสิทธิภาพของเครือข่ายประสาทไบนารี
การทบทวนเครือข่ายประสาท binarized


