micronet
1.0.0
«В настоящее время в области глубокого обучения существует две школы. Одной из них является академическая школа, которая изучает мощные и сложные модельные сети и экспериментальные методы для достижения более высокой производительности; другая - инженерная школа, которая направлена на то, чтобы внедрить алгоритмы более стабильно и эффективно на платформе для оборудования. Хотя сложные модели применяются в сложных возможностях, которые применяют сложные. Растущий масштаб глубоких нейронных сетей вызвал огромные проблемы для развертывания глубокого обучения на мобильном терминале, а сжатие и развертывание модели глубокого обучения стали одной из областей исследований, на которой сосредоточены как академические круги, так и отрасль ».
Микрот, модель сжатия и развертывание LIB.
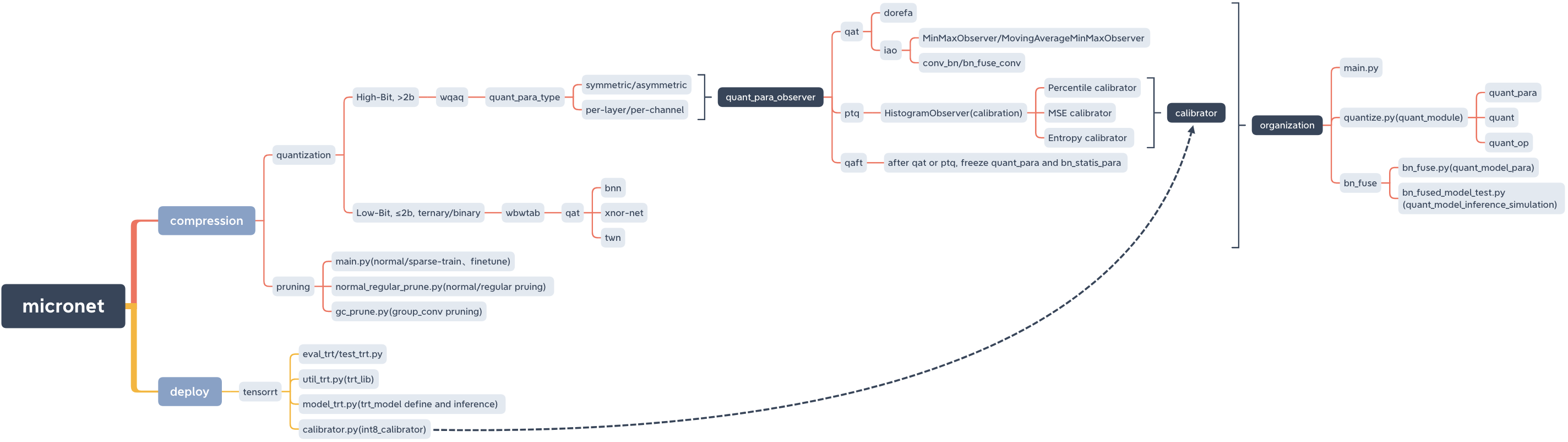
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
Пипи
pip install micronet -i https://pypi.org/simpleGitHub
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py installпроверять
python -c " import micronet; print(micronet.__version__) " Установите с GitHub
-Refine, может загрузить параметры модели с плавающей запятой и квантовать на основе их на основе их
--W-A, вес W и оснащен квантованным значением
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32--W_BITS --A_BITS, Вес W и оснащен квантовым количеством битов
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoКоличественный выбор цифр, такой же, как Dorefa
Одиночная карта
QAT/PTQ -> QAFT
! Обратите внимание, что вам нужно сделать QAFT после QAT/PTQ!
-q_type, тип квантования (0-симметричный, 1-симметричный)
-q_level, уровень веса (0-канальный уровень, 1-й уровень)
--Weight_observer, Wews_observer Selection (0-MinmaxObServer, 1-MovingAverageminMaxObserver)
-bn_fuse, флаг слияния BN в количественной оценке
-bn_fuse_calib, BN-калибровочная отметка в квантовании
-Подушный
-Qaft, Qaft Flag
--ptq, ptq_observer
--ptq_control, ptq_control
--ptq_batch, количество партий PTQ
-Percentile, коэффициент калибровки PTQ
Кат
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPtq
Предварительно обученная модель с плавающей запятой должна быть загружена, которая может быть получена путем нормальной тренировки по обрезке.
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
! Обратите внимание, что вам нужно сделать QAFT после QAT/PTQ!
Кат -> Кафт
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001PTQ -> QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqРазреженная тренировка -> Обрезка -> тонкая корректировка
cd micronet/compression/pruning-SR Sparse Знак
-S Sparse Scree (необходимо корректировать в соответствии с условиями набора данных и модели)
-Модель модели модели
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1-Процедура обрезки
-normal_regular нормальные, регулярные флаги обрезки и регулярная база обрезки (если установлено на n, количество фильтров на слой модели после обрезки, кратно N)
-Модель модельного пути после разреженного обучения
-Соберите путь модели, сохраненный после обрезки (путь был дан по умолчанию и может быть изменен в соответствии с фактической ситуацией)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthили
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth--prune_refine Путь модели после обрезки (настраиваемая настраиваемая настройка)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pthВам нужно пройти в CFG новой модели, полученной после обрезки
нравиться
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584Загрузите обрезку с плавающей запятой, а затем квантовать ее
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoQAT/PTQ -> QAFT
! Обратите внимание, что вам нужно сделать QAFT после QAT/PTQ!
Кат
BN не слияет
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001Ptq
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
! Обратите внимание, что вам нужно сделать QAFT после QAT/PTQ!
Кат -> Кафт
BN не слияет
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001PTQ -> QAFT
BN не слияет
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse-model_type, 1 -nin_gc (включая группированную сверточную структуру); 0 - нин (нормальная сверточная структура)
--prune_quant, truning_quantitative Model Flag
--W, значение квантования веса
Все необходимо соответствовать количественному обучению, и вы можете напрямую использовать по умолчанию
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test-model_type, 1 -nin_gc (включая группированную сверточную структуру); 0 - нин (нормальная сверточная структура)
--prune_quant, truning_quantitative Model Flag
--W_BITS, Квантование веса. Количество битов; -A_BITS, Квантование активации Количество битов
Все необходимо соответствовать количественному обучению, и вы можете напрямую использовать по умолчанию
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.pyОбратите внимание, что при квантованном обучении -BN_FUSE должно быть установлено на True
cd micronet/compression/quantization/wqaq/iao/bn_fuse-model_type, 1 -nin_gc (включая группированную сверточную структуру); 0 - нин (нормальная сверточная структура)
--prune_quant, truning_quantitative Model Flag
--W_BITS, Квантование веса. Количество битов; -A_BITS, Квантование активации Количество битов
-q_type, 0 -симметричный; 1 - асимметричный
-q_level, 0 -уровень канала; 1 - Уровень
Все необходимо соответствовать количественному обучению, и вы можете напрямую использовать по умолчанию
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pyТеперь поддерживает процессорец и графический процессор (одна карта, несколько карт)
-CPU Используйте ЦП,-GPU_ID Использовать и выберите GPU
python main.py --cpupython main.py --gpu_id 0или
python main.py --gpu_id 1python main.py --gpu_id 0,1или
python main.py --gpu_id 0,1,2По умолчанию используйте полную карту сервера
В настоящее время предоставляется только соответствующий код модуля основного модуля , и позже будет добавлена полная демонстрация.
Модель может быть квантована (с высоким содержанием (> 2b), низким содержанием (≤2b)/тройной и двоичной), просто заменив OP Quant_op .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )Модель может быть квантована (высокий (> 2b), низкий балл (≤2b)/тройной и двоичный), просто используя micronet.compression.quantization.quantize.prepare (модель) .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "При выводе «Quant_model готов», Microt готов.
Справочный тест моделирования слияния и количественного вывода
Ниже приведен пример CIFAR10, где вы можете попробовать другие комбинированные методы сжатия на более избыточных моделях и более крупных наборах данных.
| тип | W (биты) | А (биты) | Акк | Gflops | Пара (м) | Размер (MB) | Скорость сжатия | потеря |
|---|---|---|---|---|---|---|---|---|
| Оригинальная модель (NIN) | FP32 | FP32 | 91,01% | 0,15 | 0,67 | 2.68 | *** | *** |
| Использование группирующей структуры свертки (NIN_GC) | FP32 | FP32 | 91,04% | 0,15 | 0,58 | 2.32 | 13,43% | -0,03% |
| Обрезка | FP32 | FP32 | 90,26% | 0,09 | 0,32 | 1.28 | 52,24% | 0,75% |
| Количественная оценка | 1 | FP32 | 90,93% | *** | 0,58 | 0,204 | 92,39% | 0,08% |
| Количественная оценка | 1.5 | FP32 | 91% | *** | 0,58 | 0,272 | 89,85% | 0,01% |
| Количественная оценка | 1 | 1 | 86,23% | *** | 0,58 | 0,204 | 92,39% | 4,78% |
| Количественная оценка | 1.5 | 1 | 86,48% | *** | 0,58 | 0,272 | 89,85% | 4,53% |
| Количественная оценка (Dorefa) | 8 | 8 | 91,03% | *** | 0,58 | 0,596 | 77,76% | -0,02% |
| Количественная оценка (IAO, полная количественная оценка, симметричная/за канал/bn_fuse) | 8 | 8 | 90,99% | *** | 0,58 | 0,596 | 77,76% | 0,02% |
| Группировка + обрезка + квантование | 1.5 | 1 | 86,13% | *** | 0,32 | 0,19 | 92,91% | 4,88% |
-train_batch_size 256, одиночная карта
Binarizedneuralnetworks: Trainingnuralnetworks без веса и активации, созданные для +1 или -1
XNOR-NET: ImageNetClassieBingBinary ConvolutionAlneuralNetworks
Эмпирическое исследование оптимизации бинарных нейронных сетей
Обзор бинаризированных нейронных сетей


