micronet
1.0.0
"Saat ini, ada dua sekolah di bidang pembelajaran yang mendalam. Satu adalah sekolah akademik, yang mempelajari jaringan model yang kuat dan kompleks dan metode eksperimental untuk mengejar kinerja yang lebih tinggi; yang lain adalah sekolah teknik, yang bertujuan untuk menerapkan algoritma yang lebih sulit dan secara efisien pada platform perangkat keras. Skala yang berkembang dari jaringan saraf yang dalam telah membawa tantangan besar untuk penyebaran pembelajaran mendalam di terminal seluler, dan kompresi dan penyebaran model pembelajaran yang mendalam telah menjadi salah satu bidang penelitian yang difokuskan oleh akademisi dan industri. "
Mikrot, model kompresi dan menggunakan lib.
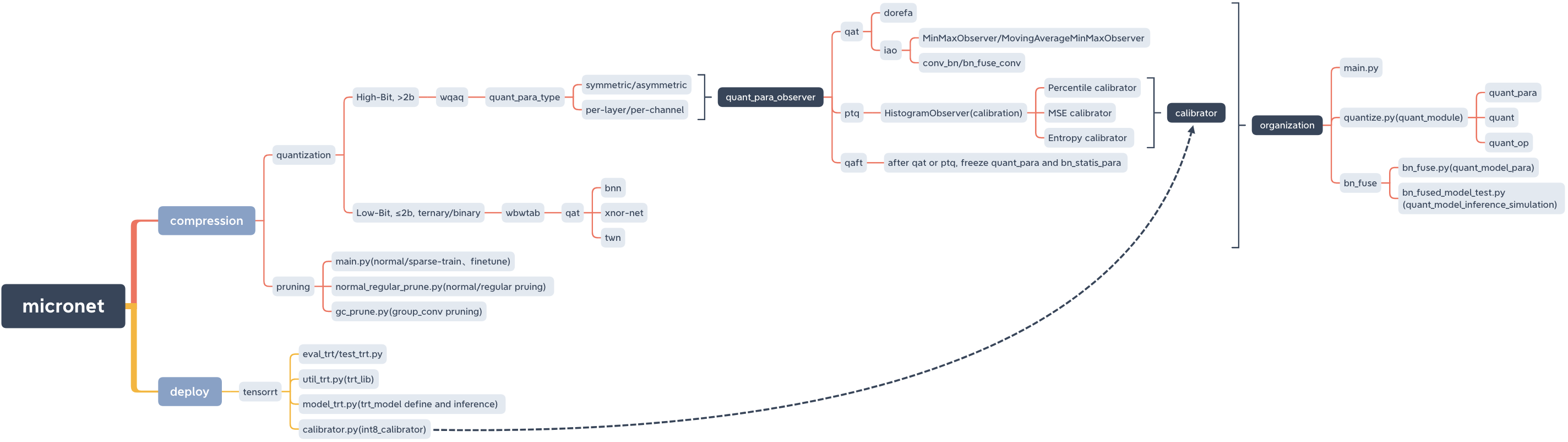
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
Pypi
pip install micronet -i https://pypi.org/simpleGitHub
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py installmemeriksa
python -c " import micronet; print(micronet.__version__) " Instal dari GitHub
--Fine, dapat memuat parameter model floating point pretrain dan mengukurnya berdasarkan mereka
--W-A, Weight W dan fitur nilai kuantisasi
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32--w_bits --a_bits, bobot w dan fitur jumlah bit kuantisasi
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoSeleksi digit kuantitatif sama dengan Dorefa
Kartu tunggal
Qat/ptq -> qaft
Lai Perhatikan bahwa Anda perlu melakukan qaft setelah qat/ptq!
--q_type, tipe kuantisasi (0-symmetric, 1-symmetric)
--q_level, level bobot (level 0-saluran, 1 level)
--weight_observer, seleksi Weight_observer (0-MinmaxoBserver, 1-MovingAverageminMaxoBserver)
-BN_FUSE, BN Fusion Flag dalam Kuantifikasi
--BN_FUSE_CALIB, tanda kalibrasi fusi BN dalam kuantisasi
--Pretrain_model, model floating point pretrained
--qaft, bendera qaft
--ptq, ptq_observer
--PTQ_CONTROL, PTQ_CONTROL
--ptq_batch, jumlah batch PTQ
--Pentile, rasio kalibrasi PTQ
Qat
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPTQ
Model titik mengambang pra-terlatih perlu dimuat, yang dapat diperoleh dengan pelatihan normal dalam pemangkasan.
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
Lai Perhatikan bahwa Anda perlu melakukan qaft setelah qat/ptq!
Qat -> qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001PTQ -> Qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqPelatihan Jarang—> Pemangkasan—> Penyesuaian yang Baik
cd micronet/compression/pruning-Sr tanda jarang
-S rate jarang (perlu disesuaikan sesuai dengan dataset dan kondisi model)
-Model_type Model Tipe (0-nin, 1-nin_gc)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1-tingkat pemangkasan
-Normal_Regular normal, bendera pemangkasan reguler dan basis pemangkasan reguler (jika diatur ke n, jumlah filter per lapisan model setelah pemangkasan adalah kelipatan n)
-Model jalur model setelah pelatihan jarang
-Save Model Path yang disimpan setelah pemangkasan (jalur telah diberikan secara default dan dapat diubah sesuai dengan situasi aktual)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthatau
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth--prune_refine jalur model setelah pemangkasan (fine-tuning berdasarkan itu)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pthAnda harus lulus dalam CFG model baru yang diperoleh setelah pemangkasan
menyukai
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584Memuat model titik mengambang yang dipangkas dan kemudian menghitungnya
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoQat/ptq -> qaft
Lai Perhatikan bahwa Anda perlu melakukan qaft setelah qat/ptq!
Qat
BN tidak fusi
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001PTQ
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
Lai Perhatikan bahwa Anda perlu melakukan qaft setelah qat/ptq!
Qat -> qaft
BN tidak fusi
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001PTQ -> Qaft
BN tidak fusi
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse--odel_type, 1 -nin_gc (termasuk struktur konvolusional yang dikelompokkan); 0 - NIN (Struktur Konvolusi Normal)
--Prune_quant, pruning_quantitative model bendera
--W, nilai kuantisasi berat
Semua harus konsisten dengan pelatihan kuantitatif, dan Anda dapat menggunakan default secara langsung
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test--odel_type, 1 -nin_gc (termasuk struktur konvolusional yang dikelompokkan); 0 - NIN (Struktur Konvolusi Normal)
--Prune_quant, pruning_quantitative model bendera
--w_bits, jumlah kuantisasi berat bit; --A_Bits, jumlah kuantisasi aktivasi bit
Semua harus konsisten dengan pelatihan kuantitatif, dan Anda dapat menggunakan default secara langsung
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.pyPerhatikan bahwa saat pelatihan terkuantisasi -BN_FUSE perlu diatur ke True
cd micronet/compression/quantization/wqaq/iao/bn_fuse--odel_type, 1 -nin_gc (termasuk struktur konvolusional yang dikelompokkan); 0 - NIN (Struktur Konvolusi Normal)
--Prune_quant, pruning_quantitative model bendera
--w_bits, jumlah kuantisasi berat bit; --A_Bits, jumlah kuantisasi aktivasi bit
--q_type, 0 -Symmetric; 1 - asimetris
--Q_LEVEL, 0 -Level Saluran; 1 - level
Semua harus konsisten dengan pelatihan kuantitatif, dan Anda dapat menggunakan default secara langsung
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pySekarang mendukung CPU dan GPU (kartu tunggal, beberapa kartu)
--CPU Gunakan CPU, --GPU_ID Penggunaan dan pilih GPU
python main.py --cpupython main.py --gpu_id 0atau
python main.py --gpu_id 1python main.py --gpu_id 0,1atau
python main.py --gpu_id 0,1,2Secara default, gunakan kartu penuh server
Saat ini, hanya kode modul inti yang relevan yang disediakan, dan demo runnable lengkap akan ditambahkan nanti.
Suatu model dapat dikuantisasi (bit tinggi (> 2b), rendah-bit (≤2b)/ternary dan biner) dengan hanya mengganti OP dengan quant_op .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )Model dapat dikuantisasi (bit tinggi (> 2b), rendah-bit (≤2b)/ternary dan biner) hanya dengan menggunakan micronet.compression.quantization.quantize.prepare (model) .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "Saat mengeluarkan "quant_model sudah siap", mikrot sudah siap.
Referensi BN Fusion dan tes simulasi inferensi kuantitatif
Berikut ini adalah contoh CIFAR10, di mana Anda dapat mencoba metode kompresi gabungan lainnya pada model yang lebih berlebihan dan set data yang lebih besar.
| jenis | W (bit) | A (bit) | ACC | Gflops | Para (m) | Ukuran (MB) | Tingkat kompresi | kehilangan |
|---|---|---|---|---|---|---|---|---|
| Model Asli (NIN) | FP32 | FP32 | 91,01% | 0,15 | 0.67 | 2.68 | *** | *** |
| Menggunakan Pengelompokan Struktur Konvolusi (NIN_GC) | FP32 | FP32 | 91,04% | 0,15 | 0,58 | 2.32 | 13,43% | -0,03% |
| Pemangkasan | FP32 | FP32 | 90,26% | 0,09 | 0.32 | 1.28 | 52,24% | 0,75% |
| Hitungan | 1 | FP32 | 90,93% | *** | 0,58 | 0.204 | 92,39% | 0,08% |
| Hitungan | 1.5 | FP32 | 91% | *** | 0,58 | 0.272 | 89,85% | 0,01% |
| Hitungan | 1 | 1 | 86,23% | *** | 0,58 | 0.204 | 92,39% | 4,78% |
| Hitungan | 1.5 | 1 | 86,48% | *** | 0,58 | 0.272 | 89,85% | 4,53% |
| Kuantifikasi (DOREFA) | 8 | 8 | 91,03% | *** | 0,58 | 0,596 | 77,76% | -0,02% |
| Kuantifikasi (IAO, kuantifikasi penuh, simetris/per-channel/bn_fuse) | 8 | 8 | 90,99% | *** | 0,58 | 0,596 | 77,76% | 0,02% |
| Pengelompokan + pemangkasan + kuantisasi | 1.5 | 1 | 86,13% | *** | 0.32 | 0.19 | 92,91% | 4,88% |
--train_batch_size 256, kartu tunggal
BinarizedneuralNetWorks: pelatihaneureuralnetworks dengan bobot dan aktivasi yang dibatasi untuk +1 atau - 1
Xnor-net: ImagenetClassifiFusingbinary ConvolutionaleureuralNetWorks
Studi empiris optimasi jaringan saraf biner
Tinjauan jaringan saraf binarized


