micronet
1.0.0
"En la actualidad, hay dos escuelas en el campo del aprendizaje profundo. Una es una escuela académica, que estudia redes de modelos poderosas y complejas y métodos experimentales para obtener un mayor rendimiento; el otro es una escuela de ingeniería, cuyo objetivo es implementar algoritmos de manera más estable y eficiente en las plataformas de hardware. de las redes neuronales profundas ha traído enormes desafíos al despliegue del aprendizaje profundo en la terminal móvil, y la compresión y el despliegue del modelo de aprendizaje profundo se han convertido en una de las áreas de investigación en las que tanto la academia como la industria se han centrado ".
Microt, un modelo de compresión y despliegue lib.
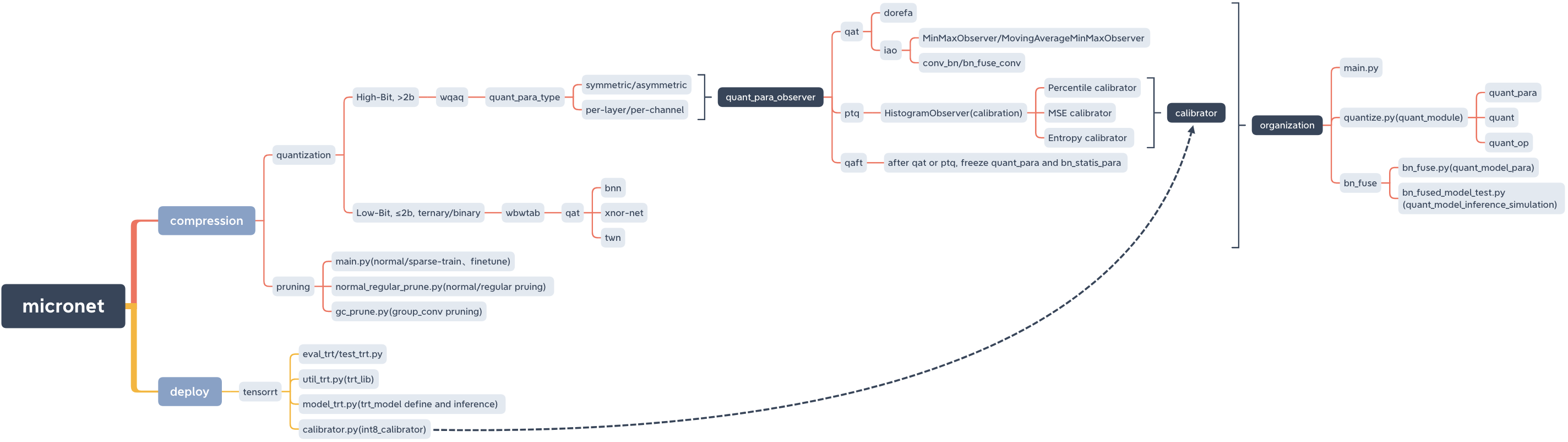
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
Pypi
pip install micronet -i https://pypi.org/simpleGithub
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py installverificar
python -c " import micronet; print(micronet.__version__) " Instalar desde Github
-Refina, puede cargar parámetros del modelo de punto flotante previamente y cuantificarlos en función de ellos
--W --A, peso w y cuentan con un valor cuantificado
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32--w_bits --a_bits, peso con un recuento de bits cuantizado
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoSelección de dígitos cuantitativos igual que dorefa
Tarjeta individual
QAT/PTQ -> QAFT
! ¡Tenga en cuenta que debe hacer QAFT después de QAT/PTQ!
--q_type, tipo de cuantización (0-simétrico, 1-simétrico)
--q_level, nivel de ponderación (nivel de 0 canales, 1 nivel)
--weight_observer, weight_observer selección (0-minmaxobserver, 1-movingaverageminmaxobserver)
--BN_FUSE, BN FUSIÓN FUERA EN LA CUANTISIÓN
--BN_FUSE_CALIB, BN Mark de calibración de fusión en cuantización
--PRETRAENTIVO_MODEL, modelo de punto flotante previo
--qaft, bandera de qaft
--PTQ, PTQ_OBSERVER
--PTQ_CONTROL, PTQ_CONTROL
--Ptq_Batch, el número de lotes de PTQ
-Porcentil, relación de calibración PTQ
Ruing
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPTQ
El modelo de punto flotante previamente capacitado debe cargarse, lo que se puede obtener mediante entrenamiento normal en poda.
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Camiseta
! ¡Tenga en cuenta que debe hacer QAFT después de QAT/PTQ!
QAT -> QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001PTQ -> QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqEntrenamiento escaso—> poda—> ajuste fino
cd micronet/compression/pruning-Sr SPARSE Sign
-Tasa escasa (debe ajustarse de acuerdo con el conjunto de datos y las condiciones del modelo)
--model_type Tipo de modelo (0-Nin, 1-NIN_GC)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1-Tasa de poda por ciento
-Normal_regular normal, podas de poda regular y base de poda regular (si se establece en n, el número de filtros por capa del modelo después de la poda es un múltiplo de n)
-Modelar la ruta del modelo después de un entrenamiento escaso
--Have la ruta del modelo guardada después de la poda (la ruta se ha dado por defecto y se puede cambiar de acuerdo con la situación real)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.ptho
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth--prune_refine la ruta del modelo después de la poda (ajuste fino basado en ella)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pthDebe pasar el CFG del nuevo modelo obtenido después de la poda
como
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584Cargue el modelo de punto flotante podado y luego lo cuantifica
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoQAT/PTQ -> QAFT
! ¡Tenga en cuenta que debe hacer QAFT después de QAT/PTQ!
Ruing
BN no fusiona
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001PTQ
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Camiseta
! ¡Tenga en cuenta que debe hacer QAFT después de QAT/PTQ!
QAT -> QAFT
BN no fusiona
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001PTQ -> QAFT
BN no fusiona
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse--model_type, 1 -nin_gc (incluida la estructura convolucional agrupada); 0 - NIN (estructura convolucional normal)
--Prune_quant, Pruning_Quantitative Model Flag
--W, valor de cuantificación de peso
Todos deben ser consistentes con la capacitación cuantitativa, y puede usar el valor predeterminado directamente
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test--model_type, 1 -nin_gc (incluida la estructura convolucional agrupada); 0 - NIN (estructura convolucional normal)
--Prune_quant, Pruning_Quantitative Model Flag
--w_bits, número de cuantificación de peso de bits; --A_BITS, Número de cuantificación de activación de bits
Todos deben ser consistentes con la capacitación cuantitativa, y puede usar el valor predeterminado directamente
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.pyTenga en cuenta que cuando la capacitación cuantifica - -BN_FUSE debe establecerse en True
cd micronet/compression/quantization/wqaq/iao/bn_fuse--model_type, 1 -nin_gc (incluida la estructura convolucional agrupada); 0 - NIN (estructura convolucional normal)
--Prune_quant, Pruning_Quantitative Model Flag
--w_bits, número de cuantificación de peso de bits; --A_BITS, Número de cuantificación de activación de bits
--q_type, 0 -simétrico; 1 - Asimétrico
--q_level, 0 -nivel de canal; 1 - Nivel
Todos deben ser consistentes con la capacitación cuantitativa, y puede usar el valor predeterminado directamente
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pyAhora admite CPU y GPU (tarjeta única, tarjeta múltiple)
--CPU Usar CPU,--GPU_ID use y seleccione GPU
python main.py --cpupython main.py --gpu_id 0o
python main.py --gpu_id 1python main.py --gpu_id 0,1o
python main.py --gpu_id 0,1,2Por defecto, use la tarjeta completa del servidor
Actualmente, solo se proporciona un código de módulo central relevante y más adelante se agregará una demostración ejecutable completa.
Se puede cuantificar un modelo (alto bit (> 2b), bajo bits (≤2b)/ternario y binario) simplemente reemplazando OP con Quant_op .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )Se puede cuantificar un modelo (alto bit (> 2b), bajo bits (≤2b)/ternario y binario) simplemente usando micronet.compression.quantization.quantize.prepare (modelo) .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "Al emitir "Quant_model está listo", Microt está listo.
Referencia BN Fusión y prueba de simulación de inferencia cuantitativa
El siguiente es un ejemplo CIFAR10, donde puede probar otros métodos de compresión combinados en modelos más redundantes y conjuntos de datos más grandes.
| tipo | W (bits) | A (bits) | Accidentista | Gflops | Para (m) | Tamaño (MB) | Tasa de compresión | pérdida |
|---|---|---|---|---|---|---|---|---|
| Modelo original (nin) | FP32 | FP32 | 91.01% | 0.15 | 0.67 | 2.68 | *** | *** |
| Uso de la estructura de convolución de agrupación (nin_gc) | FP32 | FP32 | 91.04% | 0.15 | 0.58 | 2.32 | 13.43% | -0.03% |
| Poda | FP32 | FP32 | 90.26% | 0.09 | 0.32 | 1.28 | 52.24% | 0.75% |
| Cuantificación | 1 | FP32 | 90.93% | *** | 0.58 | 0.204 | 92.39% | 0.08% |
| Cuantificación | 1.5 | FP32 | 91% | *** | 0.58 | 0.272 | 89.85% | 0.01% |
| Cuantificación | 1 | 1 | 86.23% | *** | 0.58 | 0.204 | 92.39% | 4.78% |
| Cuantificación | 1.5 | 1 | 86.48% | *** | 0.58 | 0.272 | 89.85% | 4.53% |
| Cuantificación (dorefa) | 8 | 8 | 91.03% | *** | 0.58 | 0.596 | 77.76% | -0.02% |
| Cuantificación (IAO, cuantificación completa, simétrica/por canal/bn_fuse) | 8 | 8 | 90.99% | *** | 0.58 | 0.596 | 77.76% | 0.02% |
| Agrupación + poda + cuantización | 1.5 | 1 | 86.13% | *** | 0.32 | 0.19 | 92.91% | 4.88% |
--train_batch_size 256, tarjeta única
BinarizedNeuralNetworks: Capacitarnetworks con pesas y activaciones CONSTRUICIÓN TO +1 OR - 1
Xnor-Net: ImagenetClassi fi cusingBinary ConvolutionalNetWorks
Un estudio empírico de la optimización de las redes neuronales binarias
Una revisión de las redes neuronales binarizadas


