micronet
1.0.0
"Gegenwärtig gibt es zwei Schulen im Bereich Deep Learning. Eine ist eine akademische Schule, die leistungsstarke und komplexe Modellnetzwerke und experimentelle Methoden untersucht, um eine höhere Leistung zu erzielen. Die andere ist eine technische Schule, die darauf abzielt, Algorithmen zu implementieren, die Algorithmen stabil und effizienter auf Hardware -Plattformen implementieren. Effizienz ist. Das wachsende Ausmaß der tiefen neuronalen Netzwerke hat den Einsatz von Deep -Lernen auf dem mobilen Terminal enorme Herausforderungen mitgebracht, und die Komprimierung und Bereitstellung von Deep Learning Model sind zu einem der Forschungsbereiche geworden, auf die sich sowohl die Wissenschaft als auch die Industrie konzentriert haben. "
Microt, eine Modellkomprimierung und Bereitstellung von Lib.
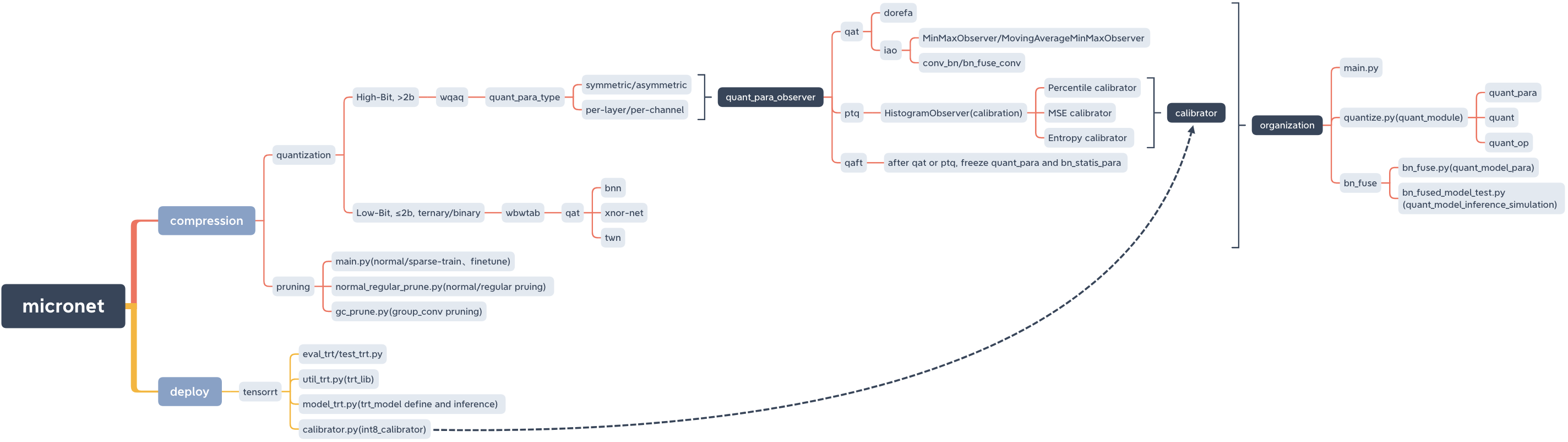
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
Pypi
pip install micronet -i https://pypi.org/simpleGithub
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py installverifizieren
python -c " import micronet; print(micronet.__version__) " Installieren Sie von GitHub
-REFINE, kann vorgezogene schwimmende Punktmodellparameter laden und sie basierend darauf quantisieren
--w-A, Gewicht w und haben einen quantisierten Wert
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32--w_bits-A_bits, Gewicht w und verfügen über eine quantisierte Bitzahl
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoQuantitative Ziffernauswahl wie Dorefa
Einzelkarte
QAT/PTQ -> Qaft
! Beachten Sie, dass Sie QAFT nach QAT/PTQ machen müssen!
--q_type, Quantisierungstyp (0-symmetrisch, 1-symmetrisch)
--Q_Level, Gewichtsniveau (0-Kanal-Ebene, 1-Stufe)
--weight_observer, Gewicht_observer Auswahl (0-minmaxobserver, 1-movingaverageminmaxobserver)
-BN_FUSE, BN-Fusionsflagge zur Quantifizierung
-BN_FUSE_CALIB, BN-Fusionskalibrierungsmarke bei der Quantisierung
-Vorbereitete_Model, vorgezogenes schwimmendes Punktmodell
-Qaft, Qaft Flag
--PTQ, PTQ_OBSERVER
--ptq_control, ptq_control
--Ptq_Batch, die Anzahl der Chargen von PTQ
-Percentile, PTQ-Kalibrierungsverhältnis
Qat
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPtq
Vorausgebildeter Gleitkomma-Modell muss geladen werden, was durch normales Training beim Beschneiden erhalten werden kann.
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
! Beachten Sie, dass Sie QAFT nach QAT/PTQ machen müssen!
QAT -> Qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001Ptq -> Qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqSpärliches Training -> Beschneidung -> Feinanpassung
cd micronet/compression/pruning-sr Spärdes Zeichen
-S Sparse Rate (muss gemäß den Datensatz- und Modellbedingungen angepasst werden)
-Modelltyp-Model_type (0-nin, 1-nin_gc)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1-Percent-Schnittrate
-Normal_reguläre normale, regelmäßige Schnittflaggen und regelmäßige Beschneidungsbasis (wenn auf N eingestellt, ist die Anzahl der Filter pro Schicht des Modells nach dem Beschneiden ein Vielfaches von n).
-Model des Modellpfads nach spärlichem Training
-Sparen Sie den nach dem Beschneiden gespeicherten Modellpfad (der Pfad wurde standardmäßig gegeben und kann gemäß der tatsächlichen Situation geändert werden)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthoder
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth-Prune_Refine Der Modellpfad nach dem Beschneiden (feinstimmende basierend darauf)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pthSie müssen die CFG des neuen Modells nach dem Beschneiden übergeben
wie
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584Laden Sie das beschnittene schwimmende Punktmodell und quantisieren Sie es dann
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoQAT/PTQ -> Qaft
! Beachten Sie, dass Sie QAFT nach QAT/PTQ machen müssen!
Qat
BN fusion nicht
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001Bn Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001Ptq
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
! Beachten Sie, dass Sie QAFT nach QAT/PTQ machen müssen!
QAT -> Qaft
BN fusion nicht
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001Bn Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001Ptq -> Qaft
BN fusion nicht
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBn Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse-model_type, 1 -nin_gc (einschließlich gruppierter Faltungsstruktur); 0 - Nin (normale Faltungsstruktur)
-Prune_quant, PRUNING_QUANTITATIVE MODELLE FLAG
--w, Gewichtsquantisierungswert
Alle müssen mit dem quantitativen Training übereinstimmen, und Sie können den Standard direkt verwenden
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test-model_type, 1 -nin_gc (einschließlich gruppierter Faltungsstruktur); 0 - Nin (normale Faltungsstruktur)
-Prune_quant, PRUNING_QUANTITATIVE MODELLE FLAG
--w_bit, Gewichtsquantisierungszahl der Bits; -A_Bits, Aktivierungsquantisierungsnummer von Bits
Alle müssen mit dem quantitativen Training übereinstimmen, und Sie können den Standard direkt verwenden
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.pyBeachten Sie, dass beim quantisierten Training - -BN_FUSE auf true eingestellt werden muss
cd micronet/compression/quantization/wqaq/iao/bn_fuse-model_type, 1 -nin_gc (einschließlich gruppierter Faltungsstruktur); 0 - Nin (normale Faltungsstruktur)
-Prune_quant, PRUNING_QUANTITATIVE MODELLE FLAG
--w_bit, Gewichtsquantisierungszahl der Bits; -A_Bits, Aktivierungsquantisierungsnummer von Bits
--q_type, 0 -symmetrisch; 1 - asymmetrisch
--Q_Level, 0 -Kanalebene; 1 - Ebene
Alle müssen mit dem quantitativen Training übereinstimmen, und Sie können den Standard direkt verwenden
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pyUnterstützt nun CPU und GPU (Einzelkarte, mehrere Karte)
-CPU Verwenden Sie CPU, --gpu_id und wählen Sie GPU aus
python main.py --cpupython main.py --gpu_id 0oder
python main.py --gpu_id 1python main.py --gpu_id 0,1oder
python main.py --gpu_id 0,1,2Verwenden Sie standardmäßig die vollständige Karte Server
Derzeit wird nur relevanter Kernmodulcode bereitgestellt, und später wird eine vollständige Runnable -Demo hinzugefügt.
Ein Modell kann durch einfaches Austausch von OP durch quant_op quantisiert werden (hochbit (> 2b), niedrig (≤ 2b)/ternär und binär).
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )Ein Modell kann unter Verwendung von micronet.compression.quantization.quantize.Prepare (Modell) quantisiert werden (hochbit (> 2b), niedrig bit (≤ 2b)/ternär und binär).
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "Beim Ausgabe von "quant_model ist bereit" ist die Mikrorot bereit.
Referenz -BN -Fusion und quantitative Inferenzsimulationstest
Das Folgende ist ein CIFAR10 -Beispiel, bei dem Sie andere kombinierte Komprimierungsmethoden für redundantere Modelle und größere Datensätze ausprobieren können.
| Typ | W (Bits) | A (Bits) | Acc | Gflops | Para (m) | Größe (MB) | Druckrate | Verlust |
|---|---|---|---|---|---|---|---|---|
| Originalmodell (Nin) | FP32 | FP32 | 91,01% | 0,15 | 0,67 | 2.68 | *** | *** |
| Verwenden der Gruppierung der Faltungsstruktur (NIN_GC) | FP32 | FP32 | 91,04% | 0,15 | 0,58 | 2.32 | 13,43% | -0,03% |
| Beschneidung | FP32 | FP32 | 90,26% | 0,09 | 0,32 | 1.28 | 52,24% | 0,75% |
| Quantifizierung | 1 | FP32 | 90,93% | *** | 0,58 | 0,204 | 92,39% | 0,08% |
| Quantifizierung | 1.5 | FP32 | 91% | *** | 0,58 | 0,272 | 89,85% | 0,01% |
| Quantifizierung | 1 | 1 | 86,23% | *** | 0,58 | 0,204 | 92,39% | 4,78% |
| Quantifizierung | 1.5 | 1 | 86,48% | *** | 0,58 | 0,272 | 89,85% | 4,53% |
| Quantifizierung (Dorefa) | 8 | 8 | 91,03% | *** | 0,58 | 0,596 | 77,76% | -0,02% |
| Quantifizierung (IAO, Vollquantifizierung, symmetrisch/pro-kanal/bn_fuse) | 8 | 8 | 90,99% | *** | 0,58 | 0,596 | 77,76% | 0,02% |
| Gruppierung + Beschneidung + Quantisierung | 1.5 | 1 | 86,13% | *** | 0,32 | 0,19 | 92,91% | 4,88% |
--train_batch_size 256, einzelne Karte
BinarizedneuralNetworks: TrainingNeuralNetworks With WeightSand und Activations constrainedto +1 oder - 1
XNOR-NET: ImageNetClassicusedBinary ConprolutionalneuralNetworks
Eine empirische Untersuchung der Optimierung der binären neuronalen Netze
Eine Überprüfung von Binarisierten neuronalen Netzwerken


