micronet
1.0.0
"At present, there are two schools in the field of deep learning. One is an academic school, which studies powerful and complex model networks and experimental methods in order to pursue higher performance; the other is an engineering school, which aims to implement algorithms more stably and efficiently on hardware platforms. Efficiency is its goal. Although complex models have better performance, high storage space and computing resource consumption are important reasons that make it difficult to effectively apply on various hardware platforms. Therefore, the growing scale of deep neural networks has brought huge challenges to the deployment of deep learning on the mobile terminal, and deep learning model compression and deployment have become one of the research areas that both academia and industry have focused on."
microt, a model compression and deploy lib.
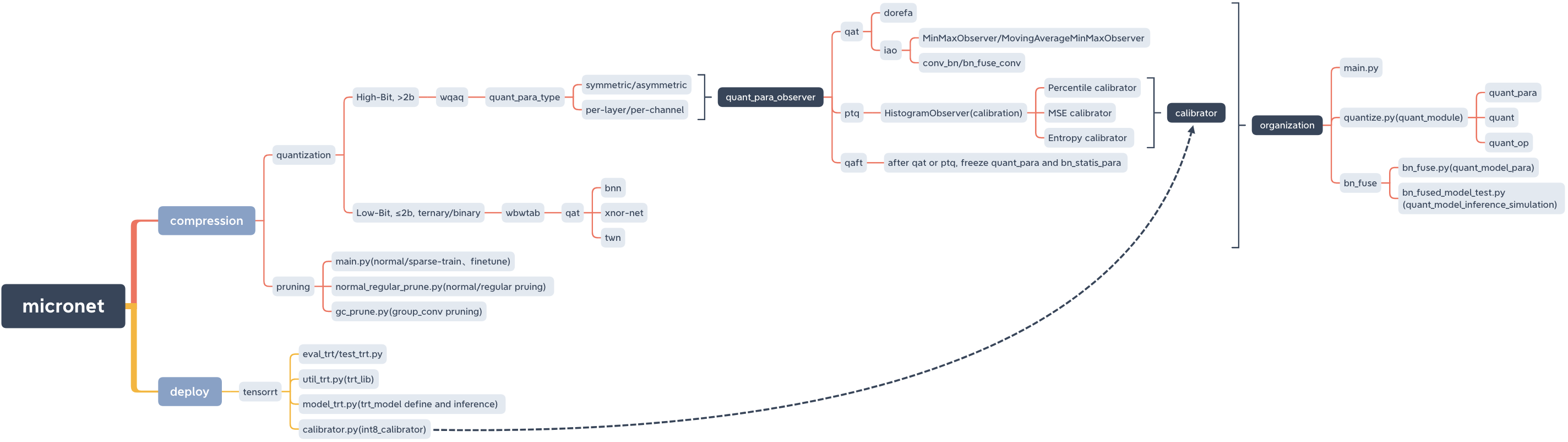
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
PyPI
pip install micronet -i https://pypi.org/simpleGitHub
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py installverify
python -c " import micronet; print(micronet.__version__) " Install from github
--refine, can load pretrained floating point model parameters and quantize them based on them
--W --A, Weight W and Feature A quantized value
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32--w_bits --a_bits, weight W and feature A quantized bit count
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoQuantitative digit selection same as dorefa
Single card
QAT/PTQ —> QAFT
! Note that you need to do QAFT after QAT/PTQ!
--q_type, quantization type (0-symmetric, 1-symmetric)
--q_level, weighting level (0-channel level, 1-level)
--weight_observer, weight_observer selection (0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, bn fusion flag in quantification
--bn_fuse_calib, bn fusion calibration mark in quantization
--pretrained_model, pretrained floating point model
--qaft, qaft flag
--ptq, ptq_observer
--ptq_control, ptq_control
--ptq_batch, the number of batches of ptq
--percentile, ptq calibration ratio
QAT
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPTQ
Pre-trained floating-point model needs to be loaded, which can be obtained by normal training in pruning.
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999QAFT
! Note that you need to do QAFT after QAT/PTQ!
QAT —> QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001PTQ —> QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqSparse training—> Pruning—> Fine adjustment
cd micronet/compression/pruning-sr sparse sign
--s sparse rate (need to be adjusted according to dataset and model conditions)
--model_type Model type (0-nin, 1-nin_gc)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1--percent pruning rate
--normal_regular Normal, regular pruning flags and regular pruning base (if set to N, the number of filters per layer of the model after pruning is a multiple of N)
--model The model path after sparse training
--save The model path saved after pruning (the path has been given by default and can be changed according to the actual situation)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthor
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth--prune_refine The model path after pruning (fine-tuning based on it)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pthYou need to pass in the cfg of the new model obtained after pruning
like
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584Load the pruned floating point model and then quantize it
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoQAT/PTQ —> QAFT
! Note that you need to do QAFT after QAT/PTQ!
QAT
bn does not fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001bn fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001PTQ
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999QAFT
! Note that you need to do QAFT after QAT/PTQ!
QAT —> QAFT
bn does not fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001bn fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001PTQ —> QAFT
bn does not fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqbn fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse--model_type, 1 - nin_gc (including grouped convolutional structure); 0 - nin (normal convolutional structure)
--prune_quant, pruning_quantitative model flag
--W, weight quantization value
All need to be consistent with quantitative training, and you can use the default directly
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test--model_type, 1 - nin_gc (including grouped convolutional structure); 0 - nin (normal convolutional structure)
--prune_quant, pruning_quantitative model flag
--w_bits, weight quantization number of bits; --a_bits, activation quantization number of bits
All need to be consistent with quantitative training, and you can use the default directly
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.pyNote that when quantized training --bn_fuse needs to be set to True
cd micronet/compression/quantization/wqaq/iao/bn_fuse--model_type, 1 - nin_gc (including grouped convolutional structure); 0 - nin (normal convolutional structure)
--prune_quant, pruning_quantitative model flag
--w_bits, weight quantization number of bits; --a_bits, activation quantization number of bits
--q_type, 0 - symmetric; 1 - asymmetric
--q_level, 0 - channel level; 1 - level
All need to be consistent with quantitative training, and you can use the default directly
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pyNow supports CPU and GPU (single card, multiple card)
--cpu Use cpu, --gpu_id Use and select gpu
python main.py --cpupython main.py --gpu_id 0or
python main.py --gpu_id 1python main.py --gpu_id 0,1or
python main.py --gpu_id 0,1,2By default, use the server full card
Currently, only relevant core module code is provided, and a complete runnable demo will be added later.
A model can be quantized(High-Bit(>2b), Low-Bit(≤2b)/Ternary and Binary) by simply replacing op with quant_op .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )A model can be quantized(High-Bit(>2b), Low-Bit(≤2b)/Ternary and Binary) by simply using micronet.compression.quantization.quantize.prepare(model) .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "When outputting "quant_model is ready", microt is ready.
Reference BN fusion and quantitative inference simulation test
The following is a cifar10 example, where you can try other combined compression methods on more redundant models and larger data sets.
| type | W(Bits) | A(Bits) | Acc | GFLOPs | Para(M) | Size(MB) | Compression rate | loss |
|---|---|---|---|---|---|---|---|---|
| Original model (nin) | FP32 | FP32 | 91.01% | 0.15 | 0.67 | 2.68 | *** | *** |
| Using grouping convolution structure (nin_gc) | FP32 | FP32 | 91.04% | 0.15 | 0.58 | 2.32 | 13.43% | -0.03% |
| Pruning | FP32 | FP32 | 90.26% | 0.09 | 0.32 | 1.28 | 52.24% | 0.75% |
| Quantification | 1 | FP32 | 90.93% | *** | 0.58 | 0.204 | 92.39% | 0.08% |
| Quantification | 1.5 | FP32 | 91% | *** | 0.58 | 0.272 | 89.85% | 0.01% |
| Quantification | 1 | 1 | 86.23% | *** | 0.58 | 0.204 | 92.39% | 4.78% |
| Quantification | 1.5 | 1 | 86.48% | *** | 0.58 | 0.272 | 89.85% | 4.53% |
| Quantification (DoReFa) | 8 | 8 | 91.03% | *** | 0.58 | 0.596 | 77.76% | -0.02% |
| Quantification (IAO, full quantification, symmetric/per-channel/bn_fuse) | 8 | 8 | 90.99% | *** | 0.58 | 0.596 | 77.76% | 0.02% |
| Grouping + pruning + quantization | 1.5 | 1 | 86.13% | *** | 0.32 | 0.19 | 92.91% | 4.88% |
--train_batch_size 256, single card
BinarizedNeuralNetworks: TrainingNeuralNetworks withWeightsand ActivationsConstrainedto +1 or−1
XNOR-Net:ImageNetClassificUsingBinary ConvolutionalNeuralNetworks
AN EMPIRICAL STUDY OF BINARY NEURAL NETWORKS' OPTIMISATION
A Review of Binarized Neural Networks


