micronet
1.0.0
"في الوقت الحاضر ، هناك مدرستان في مجال التعلم العميق. إحداها هي مدرسة أكاديمية ، والتي تدرس شبكات نموذجية قوية ومعقدة وطرق تجريبية من أجل متابعة الأداء العالي ؛ والآخر هو مدرسة هندسية ، تهدف إلى تنفيذ خوارزميات عالية بشكل أكبر وفعالًا ، فإنها تُعتبر الأمر أكثر صعوبة ، مما يجعلها تؤدي إلى صعوبة من منصات المتغيرات المتغيرة. جلب النطاق المتزايد للشبكات العصبية العميقة تحديات هائلة لنشر التعلم العميق على محطة الهاتف المحمول ، وأصبح ضغط نموذج التعلم العميق ونشره أحد مجالات البحث التي ركزت عليها كل من الأوساط الأكاديمية والصناعة. "
microt ، ضغط النموذج ونشر lib.
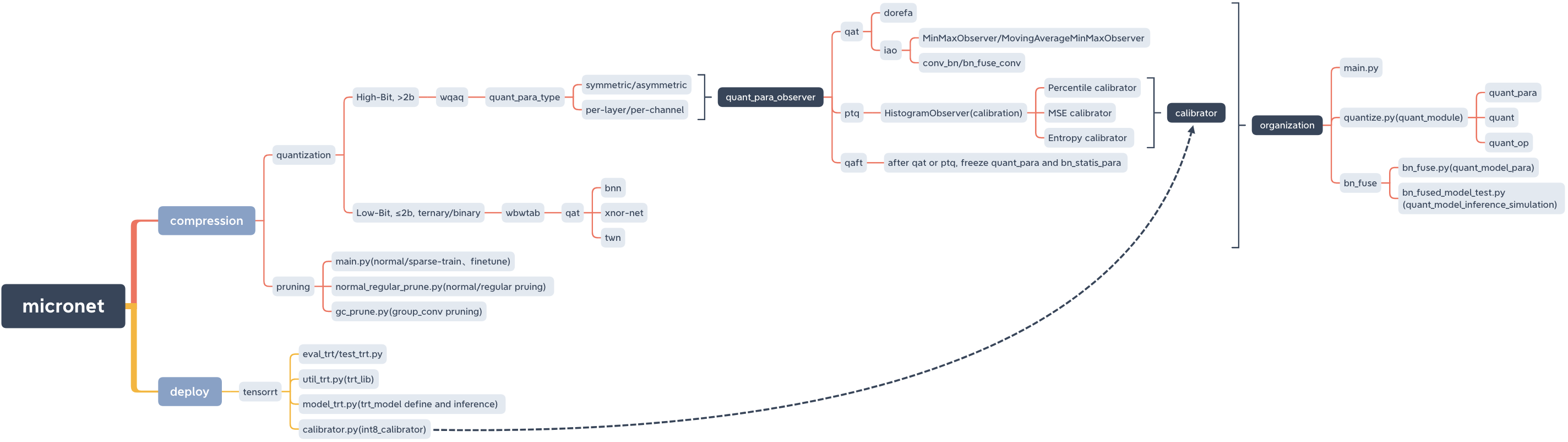
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
pypi
pip install micronet -i https://pypi.org/simpleجيثب
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py installيؤكد
python -c " import micronet; print(micronet.__version__) " تثبيت من جيثب
-REFINE ، يمكن تحميل معلمات نموذج نقطة العائمة المسبقة وتكميتها بناءً عليها بناءً عليها
-W-A ، الوزن W وميز قيمة كمية
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32-w_bits-a_bits ، الوزن ث وميز عدد بتات كمية
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoاختيار الأرقام الكمية مثل Dorefa
بطاقة واحدة
QAT/PTQ -> QAFT
! لاحظ أنك تحتاج إلى القيام Qaft بعد Qat/PTQ!
-q_type ، نوع الكمي (0-symmetric ، 1-symmetric)
-Q_LEVEL ، مستوى الترجيح (مستوى القناة 0 ، مستوى واحد)
-weight_observer ، اختيار eight_observer (0-minmaxobserver ، 1-movingaverageminmaxobserver)
-Bn_fuse ، علم الانصهار BN في القياس الكمي
-BN_FUSE_CALIB ، علامة معايرة الاندماج BN في القياس الكمي
-pretrabed_model ، نموذج نقطة عائم قبله
-Qaft ، علم Qaft
-PTQ ، PTQ_OBServer
-PTQ_CONTROL ، PTQ_CONTROL
-PTQ_BATCH ، عدد دفعات PTQ
-نسبة PTQ ، نسبة معايرة PTQ
قات
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPTQ
يجب تحميل نموذج الفاصلة العائمة المدربين مسبقًا ، والذي يمكن الحصول عليه عن طريق التدريب العادي في التقليم.
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999qaft
! لاحظ أنك تحتاج إلى القيام Qaft بعد Qat/PTQ!
Qat -> qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001PTQ -> qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqالتدريب المتناثر -> التقليم -> تعديل غرامة
cd micronet/compression/pruning-SR علامة تفريخ
-معدل الفرق (يجب تعديله وفقًا لشروط مجموعة البيانات وشروط النموذج)
-نوع طراز model_type (0-nin ، 1-nin_gc)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1-معدل التقليم في المائة
-normal_regular العادية ، العلامات التقليدية العادية وقاعدة التقليم العادية (إذا تم ضبطها على n ، فإن عدد المرشحات لكل طبقة من النموذج بعد التقليم هو مضاعف n)
-نموذج مسار النموذج بعد التدريب المتناثر
-احمل مسار النموذج المحفوظ بعد التقليم (تم إعطاء المسار افتراضيًا ويمكن تغييره وفقًا للوضع الفعلي)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthأو
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth-prune_refine مسار النموذج بعد التقليم (صقله بناءً عليه)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pthتحتاج إلى المرور في CFG من النموذج الجديد الذي تم الحصول عليه بعد التقليم
يحب
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584قم بتحميل نموذج النقطة العائمة المشبعة ثم حدده
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoQAT/PTQ -> QAFT
! لاحظ أنك تحتاج إلى القيام Qaft بعد Qat/PTQ!
قات
BN لا يندمج
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001PTQ
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999qaft
! لاحظ أنك تحتاج إلى القيام Qaft بعد Qat/PTQ!
Qat -> qaft
BN لا يندمج
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001PTQ -> qaft
BN لا يندمج
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse-model_type ، 1 -nin_gc (بما في ذلك الهيكل التلافيفي المجمعة) ؛ 0 - NIN (بنية تلغيرات طبيعية)
-prune_quant ، علم النموذج pruning_quantitive
-W ، قيمة قياس الوزن
يجب أن تكون جميعها متسقة مع التدريب الكمي ، ويمكنك استخدام الافتراضي مباشرة
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test-model_type ، 1 -nin_gc (بما في ذلك الهيكل التلافيفي المجمعة) ؛ 0 - NIN (بنية تلغيرات طبيعية)
-prune_quant ، علم النموذج pruning_quantitive
-W_BITS ، عدد الكميات في الوزن عدد البتات ؛ -A_BITS ، تقدير كمية التنشيط عدد البتات
يجب أن تكون جميعها متسقة مع التدريب الكمي ، ويمكنك استخدام الافتراضي مباشرة
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.pyلاحظ أنه عند التدريب الكمي -يجب ضبط bn_fuse على صحيح
cd micronet/compression/quantization/wqaq/iao/bn_fuse-model_type ، 1 -nin_gc (بما في ذلك الهيكل التلافيفي المجمعة) ؛ 0 - NIN (بنية تلغيرات طبيعية)
-prune_quant ، علم النموذج pruning_quantitive
-W_BITS ، عدد الكميات في الوزن عدد البتات ؛ -A_BITS ، تقدير كمية التنشيط عدد البتات
-q_type ، 0 -متماثل ؛ 1 - غير متماثل
-q_level ، 0 -مستوى القناة ؛ 1 - المستوى
يجب أن تكون جميعها متسقة مع التدريب الكمي ، ويمكنك استخدام الافتراضي مباشرة
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pyيدعم الآن وحدة المعالجة المركزية و GPU (بطاقة واحدة ، بطاقة متعددة)
-CPU استخدم وحدة المعالجة المركزية ،-GPU_ID الاستخدام وحدد GPU
python main.py --cpupython main.py --gpu_id 0أو
python main.py --gpu_id 1python main.py --gpu_id 0,1أو
python main.py --gpu_id 0,1,2افتراضيًا ، استخدم البطاقة الكاملة للخادم
حاليًا ، يتم توفير رمز الوحدة الأساسية ذات الصلة فقط ، وسيتم إضافة عرض تجريبي كامل يمكن تشغيله لاحقًا.
يمكن تقدير كمية النموذج (عالية بت (> 2 ب) ، منخفضة بت (≤2b)/الثلاثي والثنائي) عن طريق استبدال OP مع Quant_OP .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )يمكن تقدير النموذج (عالية بت (> 2 ب) ، منخفضة بت (≤2b)/الثلاثية والثنائية) عن طريق استخدام micronet.compression.quantization.quantize.prepare (نموذج) .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "عند إخراج "Quant_Model جاهز" ، يكون Microt جاهزًا.
مرجع BN الانصهار واختبار محاكاة الاستدلال الكمي
فيما يلي مثال CIFAR10 ، حيث يمكنك تجربة طرق الضغط المدمجة الأخرى على النماذج الأكثر زائدة عن الحاجة ومجموعات البيانات الأكبر.
| يكتب | ث (بت) | (بت) | ACC | gflops | الفقرة (م) | الحجم (MB) | معدل الضغط | خسارة |
|---|---|---|---|---|---|---|---|---|
| النموذج الأصلي (NIN) | FP32 | FP32 | 91.01 ٪ | 0.15 | 0.67 | 2.68 | *** | *** |
| باستخدام هيكل إتلاف التجميع (NIN_GC) | FP32 | FP32 | 91.04 ٪ | 0.15 | 0.58 | 2.32 | 13.43 ٪ | -0.03 ٪ |
| تشذيب | FP32 | FP32 | 90.26 ٪ | 0.09 | 0.32 | 1.28 | 52.24 ٪ | 0.75 ٪ |
| الكمية | 1 | FP32 | 90.93 ٪ | *** | 0.58 | 0.204 | 92.39 ٪ | 0.08 ٪ |
| الكمية | 1.5 | FP32 | 91 ٪ | *** | 0.58 | 0.272 | 89.85 ٪ | 0.01 ٪ |
| الكمية | 1 | 1 | 86.23 ٪ | *** | 0.58 | 0.204 | 92.39 ٪ | 4.78 ٪ |
| الكمية | 1.5 | 1 | 86.48 ٪ | *** | 0.58 | 0.272 | 89.85 ٪ | 4.53 ٪ |
| القياس الكمي (dorefa) | 8 | 8 | 91.03 ٪ | *** | 0.58 | 0.596 | 77.76 ٪ | -0.02 ٪ |
| القياس الكمي (IAO ، الكمي الكامل ، متماثل/لكل قناة/BN_FUSE) | 8 | 8 | 90.99 ٪ | *** | 0.58 | 0.596 | 77.76 ٪ | 0.02 ٪ |
| التجميع + التقليم + القياس الكمي | 1.5 | 1 | 86.13 ٪ | *** | 0.32 | 0.19 | 92.91 ٪ | 4.88 ٪ |
-train_batch_size 256 ، بطاقة واحدة
binarizedneuralnetworks: TrainingNuralNetWorks withweights و activationscreatedto +1 أو 1
Xnor-Net: ImageNetClassi controlutionalnuralnuralnetworks
دراسة تجريبية لتحسين الشبكات العصبية الثنائية
مراجعة للشبكات العصبية ذات الثقة


