micronet
1.0.0
「現在、深い学習の分野には2つの学校があります。1つは、より高いパフォーマンスを追求するために強力で複雑なモデルネットワークと実験方法を研究する学術学校です。もう1つは、ハードウェアプラットフォームでより安定かつ効率的にアルゴリズムを実装することを目的としています。深いニューラルネットワークは、モバイルターミナルでのディープラーニングの展開に大きな課題をもたらし、深い学習モデルの圧縮と展開は、学界と産業の両方が焦点を当てている研究分野の1つになりました。」
マイクロット、モデル圧縮とLIBを展開します。
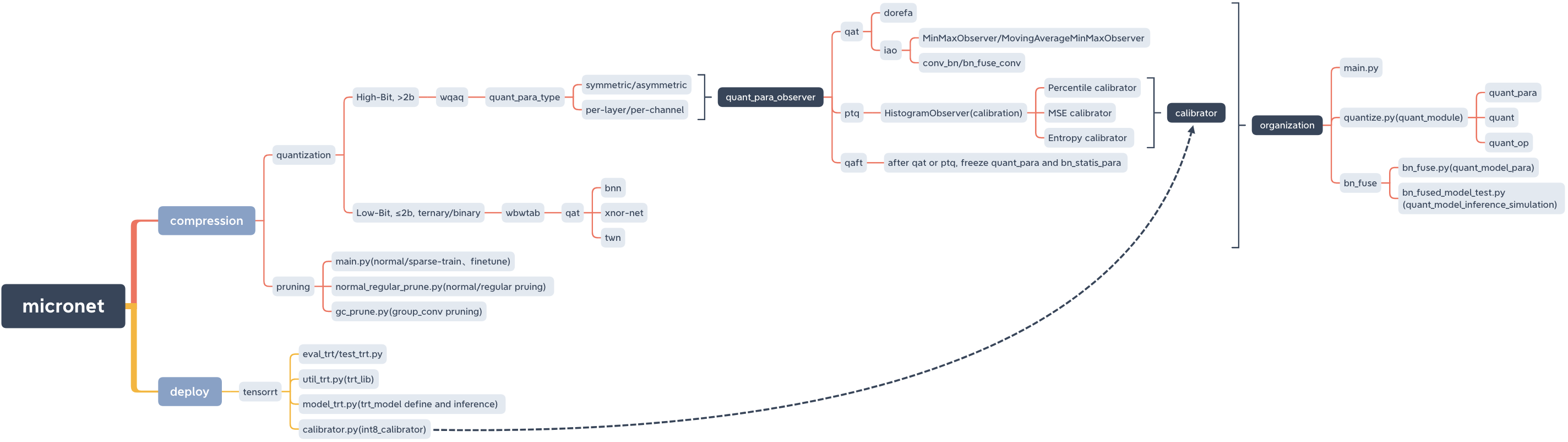
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
ピピ
pip install micronet -i https://pypi.org/simplegithub
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py install確認する
python -c " import micronet; print(micronet.__version__) " Githubからインストールします
-refine、前処理されたフローティングポイントモデルパラメーターをロードし、それらに基づいてそれらを量子化できます
-w-w、重量w、および量子化された値を備えています
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32-w_bits -a_bits、weight w、およびQuantized bit countを備えています
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoDorefaと同じ定量的数字の選択
シングルカード
QAT/PTQ - > QAFT
! QAT/PTQの後にQAFTを実行する必要があることに注意してください!
-q_type、量子化タイプ(0サイズ、1つの対称)
-Q_LEVEL、加重レベル(0チャンネルレベル、1レベル)
-weight_observer、weight_observer選択(0-minmaxobserver、1-movingaverageminmaxobserver)
-bn_fuse、bn fusionフラグの定量化
-bn_fuse_calib、bn fusion calbration mark in Quantization
-pretrained_model、前処理されたフローティングポイントモデル
-qaft、qaftフラグ
-ptq、ptq_observer
-ptq_control、ptq_control
-ptq_batch、ptqのバッチ数
-percentile、PTQキャリブレーション比
qat
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPTQ
事前に訓練されたフローティングポイントモデルをロードする必要があります。これは、剪定の通常のトレーニングによって取得できます。
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999qaft
! QAT/PTQの後にQAFTを実行する必要があることに注意してください!
QAT - > QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001PTQ - > QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqスパーストレーニング - >剪定 - >細かい調整
cd micronet/compression/pruning-srスパースサイン
- スパースレート(データセットとモデルの条件に従って調整する必要があります)
-Model_Typeモデルタイプ(0-NIN、1-NIN_GC)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1- パーセント剪定率
-Normal_Regular Normal、通常の剪定フラグ、および通常の剪定ベース(nに設定されている場合、剪定後のモデルのレイヤーあたりのフィルターの数はnの倍数です)
- スパーストレーニング後のモデルパスをモデル化します
- 剪定後に保存されたモデルパスを保存します(パスはデフォルトで与えられ、実際の状況に応じて変更できます)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthまたは
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth-prune_Refine剪定後にモデルパスをrefineします(それに基づく微調整)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pth剪定後に得られた新しいモデルのCFGを渡す必要があります
のように
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584剪定されたフローティングポイントモデルをロードしてから量子化します
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoQAT/PTQ - > QAFT
! QAT/PTQの後にQAFTを実行する必要があることに注意してください!
qat
BNは融合しません
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001BN融合
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001PTQ
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999qaft
! QAT/PTQの後にQAFTを実行する必要があることに注意してください!
QAT - > QAFT
BNは融合しません
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001BN融合
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001PTQ - > QAFT
BNは融合しません
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBN融合
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse-model_type、1 -nin_gc(グループ化された畳み込み構造を含む); 0 -nin(通常の畳み込み構造)
-prune_quant、pruning_quantitativeモデルフラグ
-W、体重量子化値
すべてが定量的トレーニングと一致する必要があり、デフォルトを直接使用できます
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test-model_type、1 -nin_gc(グループ化された畳み込み構造を含む); 0 -nin(通常の畳み込み構造)
-prune_quant、pruning_quantitativeモデルフラグ
-w_bits、体重量子化ビット数。 -a_bits、アクティベーション量子化ビット数
すべてが定量的トレーニングと一致する必要があり、デフォルトを直接使用できます
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.py量子化されたトレーニング-BN_FUSEをtrueに設定する必要があることに注意してください
cd micronet/compression/quantization/wqaq/iao/bn_fuse-model_type、1 -nin_gc(グループ化された畳み込み構造を含む); 0 -nin(通常の畳み込み構造)
-prune_quant、pruning_quantitativeモデルフラグ
-w_bits、体重量子化ビット数。 -a_bits、アクティベーション量子化ビット数
-q_type、0-対称; 1-非対称
-q_level、0-チャネルレベル; 1-レベル
すべてが定量的トレーニングと一致する必要があり、デフォルトを直接使用できます
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pyCPUとGPU(シングルカード、複数カード)をサポートするようになりました
-CPU使用CPU、-GPU_IDはGPUを使用して選択します
python main.py --cpupython main.py --gpu_id 0または
python main.py --gpu_id 1python main.py --gpu_id 0,1または
python main.py --gpu_id 0,1,2デフォルトでは、サーバーフルカードを使用します
現在、関連するコアモジュールコードのみが提供されており、完全に実行可能なデモが後で追加されます。
モデルは、 OPをQuant_opに置き換えるだけで、Quant_opに置き換えるだけで、Quantized(highbit(> 2b)、low-bit(≤2b)/vinaryおよびbinary)を量子化できます。
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )Micronet.compression.quantization.quantize.prepare(モデル)を使用するだけで、モデルを量子化(ハイビット(> 2b)、低ビット(≤2b)/vinaryおよびbinary)を使用することができます。
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "「Quant_Modelの準備ができている」出力を出力すると、Microtの準備が整います。
参照BN融合および定量的推論シミュレーションテスト
以下はCIFAR10の例です。この例では、より冗長モデルとより大きなデータセットで他の複合圧縮方法を試すことができます。
| タイプ | W(ビット) | A(ビット) | acc | GFLOPS | パラ(m) | サイズ(MB) | 圧縮率 | 損失 |
|---|---|---|---|---|---|---|---|---|
| オリジナルモデル(nin) | FP32 | FP32 | 91.01% | 0.15 | 0.67 | 2.68 | *** | *** |
| グループ化畳み込み構造(NIN_GC)の使用 | FP32 | FP32 | 91.04% | 0.15 | 0.58 | 2.32 | 13.43% | -0.03% |
| 剪定 | FP32 | FP32 | 90.26% | 0.09 | 0.32 | 1.28 | 52.24% | 0.75% |
| 定量化 | 1 | FP32 | 90.93% | *** | 0.58 | 0.204 | 92.39% | 0.08% |
| 定量化 | 1.5 | FP32 | 91% | *** | 0.58 | 0.272 | 89.85% | 0.01% |
| 定量化 | 1 | 1 | 86.23% | *** | 0.58 | 0.204 | 92.39% | 4.78% |
| 定量化 | 1.5 | 1 | 86.48% | *** | 0.58 | 0.272 | 89.85% | 4.53% |
| 定量化(dorefa) | 8 | 8 | 91.03% | *** | 0.58 | 0.596 | 77.76% | -0.02% |
| 定量化(IAO、完全な定量化、対称/チャンネル/BN_FUSE) | 8 | 8 | 90.99% | *** | 0.58 | 0.596 | 77.76% | 0.02% |
| グループ化 +剪定 +量子化 | 1.5 | 1 | 86.13% | *** | 0.32 | 0.19 | 92.91% | 4.88% |
-train_batch_size 256、シングルカード
binarizedneuralnetworks:trainingneuralnetworks withweightsand activationsconstrained +1 or -1
Xnor-net:imagenetclassifusingbinary convolutionalneuralnetworks
バイナリニューラルネットワークの最適化の実証研究
二等型ニューラルネットワークのレビュー


