micronet
1.0.0
"현재 딥 러닝 분야에는 두 개의 학교가 있습니다. 하나는 더 높은 성능을 추구하기 위해 강력하고 복잡한 모델 네트워크와 실험 방법을 연구하는 학술 학교입니다. 다른 하나는 엔지니어링 스쿨입니다. 다른 하나는 하드웨어 플랫폼에서 알고리즘을보다 안정적이고 효율적으로 구현하는 것을 목표로합니다. 효율성은 더 나은 성능, 높은 스토리지 공간 및 계산에 적용하는 데 중요한 이유가 있어야합니다. 딥 신경 네트워크의 규모가 커지면 모바일 터미널에 딥 러닝을 배치하는 데 큰 어려움이 생겼으며, 딥 러닝 모델 압축 및 배포는 학계와 산업 모두가 집중 한 연구 분야 중 하나가되었습니다. "
Microt, 모델 압축 및 Lib를 배포합니다.
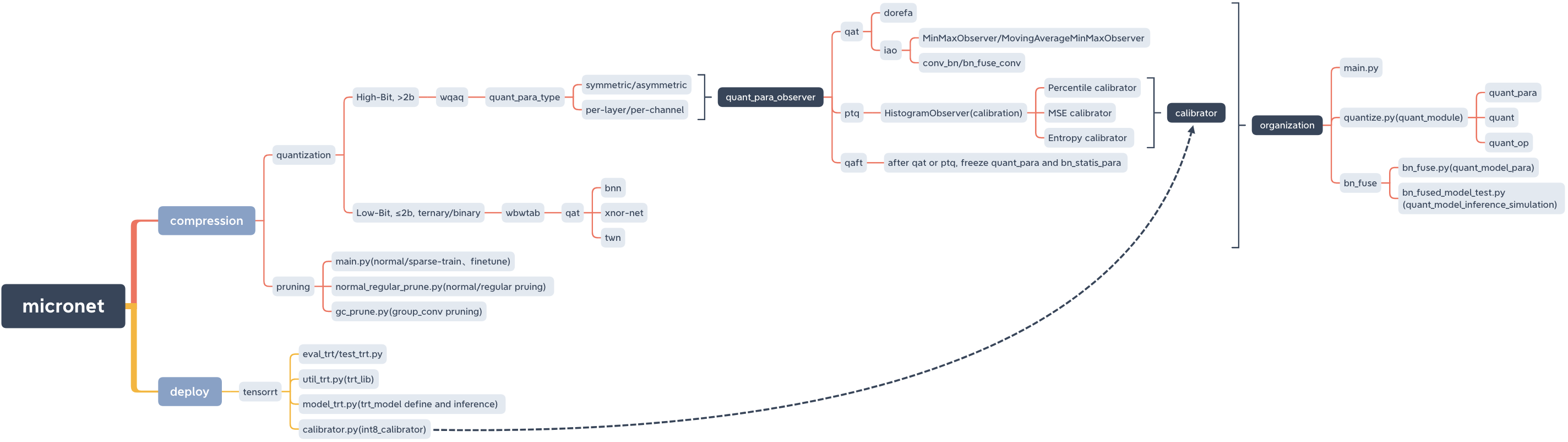
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
pypi
pip install micronet -i https://pypi.org/simplegithub
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py install확인하다
python -c " import micronet; print(micronet.__version__) " Github에서 설치하십시오
--refine, 사전에 사전에있는 플로팅 포인트 모델 매개 변수를로드하고 그것들을 기반으로 양자화 할 수 있습니다.
-w --a, 무게 w 및 양자화 된 값이 특징입니다
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32-w_bits --a_bits, weight w 및 양자화 된 비트 수 특징
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoDorefa와 동일한 정량적 숫자 선택
단일 카드
qat/ptq -> qaft
! QAT/PTQ 이후에 QAFT를 수행해야합니다!
-Q_TYPE, 양자화 유형 (0- 대칭, 1- 대칭)
-Q_LEVEL, 가중치 레벨 (0 채널 레벨, 1 레벨)
-weight_observer, weight_observer selection (0-minmaxobserver, 1-movingaverageminmaxobserver)
----bn_fuse, 정량화의 bn 퓨전 플래그
-BN_FUSE_CALIB, 양자화의 BN 퓨전 교정 마크
-pretraind_model, 사전 상환 플로팅 포인트 모델
-QAFT, QAFT 플래그
--ptq, ptq_observer
--ptq_control, ptq_control
-ptq_batch, PTQ의 배치 수
-중심, PTQ 교정 비율
Qat
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPTQ
사전 훈련 된 부동 소수점 모델은 잘라링해야하며, 이는 가지 치기에 대한 정상적인 훈련으로 얻을 수 있습니다.
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
! QAT/PTQ 이후에 QAFT를 수행해야합니다!
qat -> Qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001PTQ -> QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptq드문 훈련 -> 가지 치기 -> 미세 조정
cd micronet/compression/pruning-SR 스파 스 사인
--S 스파 스 속도 (데이터 세트 및 모델 조건에 따라 조정해야합니다)
-Model_Type 모델 유형 (0-NIN, 1-NIN_GC)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1-중앙 가지 치기 속도
-normal_regular 정상, 일반 가지 치기 플래그 및 일반 가지 치기베이스 (N으로 설정된 경우 가지 치기 후 모델의 레이어 당 필터 수는 N의 배수입니다)
-스파 스 훈련 후 모델 경로를 모델링하십시오
-가지 치기 후에 저장된 모델 경로 (경로는 기본적으로 제공되었으며 실제 상황에 따라 변경 될 수 있음)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pth또는
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth--prune_refine 가지 치기 후 모델 경로 (미세 조정 기반)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pth가지 치기 후 얻은 새 모델의 CFG를 통과해야합니다.
좋다
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584가지 치기 플로팅 포인트 모델을로드 한 다음 정량화하십시오.
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoqat/ptq -> qaft
! QAT/PTQ 이후에 QAFT를 수행해야합니다!
Qat
BN은 융합하지 않습니다
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001BN 퓨전
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001PTQ
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
! QAT/PTQ 이후에 QAFT를 수행해야합니다!
qat -> Qaft
BN은 융합하지 않습니다
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001BN 퓨전
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001PTQ -> QAFT
BN은 융합하지 않습니다
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBN 퓨전
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse-Model_type, 1 -nin_gc (그룹화 된 컨볼 루션 구조 포함); 0- NIN (정상 컨볼 루션 구조)
-prune_quant, pruning_quantitative 모델 플래그
-w, 중량 양자화 값
모두 정량적 훈련과 일치해야하며 기본값을 직접 사용할 수 있습니다.
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test-Model_type, 1 -nin_gc (그룹화 된 컨볼 루션 구조 포함); 0- NIN (정상 컨볼 루션 구조)
-prune_quant, pruning_quantitative 모델 플래그
-w_bits, 무게 양자화 비트; --a_bits, 활성화 양자화 비트 수
모두 정량적 훈련과 일치해야하며 기본값을 직접 사용할 수 있습니다.
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.py양자화 된 훈련 -bn_fuse는 true로 설정해야합니다.
cd micronet/compression/quantization/wqaq/iao/bn_fuse-Model_type, 1 -nin_gc (그룹화 된 컨볼 루션 구조 포함); 0- NIN (정상 컨볼 루션 구조)
-prune_quant, pruning_quantitative 모델 플래그
-w_bits, 무게 양자화 비트; --a_bits, 활성화 양자화 비트 수
-q_type, 0- 대칭; 1- 비대칭
-Q_LEVEL, 0- 채널 레벨; 1- 레벨
모두 정량적 훈련과 일치해야하며 기본값을 직접 사용할 수 있습니다.
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.py이제 CPU 및 GPU를 지원합니다 (단일 카드, 다중 카드)
-CPU CPU를 사용합니다. -GPU_ID 사용 및 GPU를 선택하십시오
python main.py --cpupython main.py --gpu_id 0또는
python main.py --gpu_id 1python main.py --gpu_id 0,1또는
python main.py --gpu_id 0,1,2기본적으로 서버 전체 카드를 사용하십시오
현재 관련 핵심 모듈 코드 만 제공되며 나중에 전체 실행 가능한 데모가 추가됩니다.
OP를 Quant_OP 로 교체하여 모델을 양자화 (고 비트 (> 2B), 저 비트 (≤2B)/3 배)로 만들 수 있습니다.
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )단순히 micronet.compression.quantization.quantize.prepare (model)를 사용하여 모델을 양자화 (고 비트 (> 2b), 저 비트 (≤2b)/3 배)로 양자화 할 수 있습니다.
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() ""Quant_Model이 준비되었다"는 출력을 출력하면 마이크로가 준비되었습니다.
참조 BN 융합 및 정량적 추론 시뮬레이션 테스트
다음은 CIFAR10 예제로, 더 중복 모델과 더 큰 데이터 세트에서 다른 결합 된 압축 방법을 시도 할 수 있습니다.
| 유형 | W (비트) | A (비트) | acc | gflops | 파라 (m) | 크기 (MB) | 압축률 | 손실 |
|---|---|---|---|---|---|---|---|---|
| 오리지널 모델 (NIN) | FP32 | FP32 | 91.01% | 0.15 | 0.67 | 2.68 | *** | *** |
| 그룹화 컨볼 루션 구조 사용 (NIN_GC) | FP32 | FP32 | 91.04% | 0.15 | 0.58 | 2.32 | 13.43% | -0.03% |
| 전정 | FP32 | FP32 | 90.26% | 0.09 | 0.32 | 1.28 | 52.24% | 0.75% |
| 부량 | 1 | FP32 | 90.93% | *** | 0.58 | 0.204 | 92.39% | 0.08% |
| 부량 | 1.5 | FP32 | 91% | *** | 0.58 | 0.272 | 89.85% | 0.01% |
| 부량 | 1 | 1 | 86.23% | *** | 0.58 | 0.204 | 92.39% | 4.78% |
| 부량 | 1.5 | 1 | 86.48% | *** | 0.58 | 0.272 | 89.85% | 4.53% |
| 정량화 (dorefa) | 8 | 8 | 91.03% | *** | 0.58 | 0.596 | 77.76% | -0.02% |
| 정량화 (IAO, 전체 정량화, 대칭/채널/BN_FUSE) | 8 | 8 | 90.99% | *** | 0.58 | 0.596 | 77.76% | 0.02% |
| 그룹화 + 가지 치기 + 양자화 | 1.5 | 1 | 86.13% | *** | 0.32 | 0.19 | 92.91% | 4.88% |
--train_batch_size 256, 단일 카드
Binarizedneuralnetworks : +1 OR -1의 무게와 활성화가있는 TrainingneuralNewnowss는 +1 또는 -1
Xnor-Net : ImageNetClassificingbinary Convolutionalneuralnetworks
이진 신경망의 최적화에 대한 경험적 연구
이항화 된 신경망의 검토


