micronet
1.0.0
"Atualmente, existem duas escolas no campo da aprendizagem profunda. Um é uma escola acadêmica, que estuda redes modelo poderosas e complexas e métodos experimentais, a fim de buscar um desempenho mais alto; o outro é uma escola de engenharia, que tem como objetivo implementar que os modelos complexos tenham um melhor desempenho, com mais eficiência que se apliquem, que é um melhor desempenho, que é possível que os algoritmos tenham um melhor desempenho, com mais de maneira alta e eficiente, a eficiência de que a eficiência é que os modelos complexos tenham um melhor desempenho, o melhor desempenho, o alto e eficiente das plataformas de hardware. A crescente escala de redes neurais profundas trouxe enormes desafios à implantação de aprendizado profundo no terminal móvel, e a compressão e a implantação do modelo de aprendizado profundo se tornaram uma das áreas de pesquisa em que a academia e a indústria se concentraram ".
Microt, um modelo de compactação e implantação LIB.
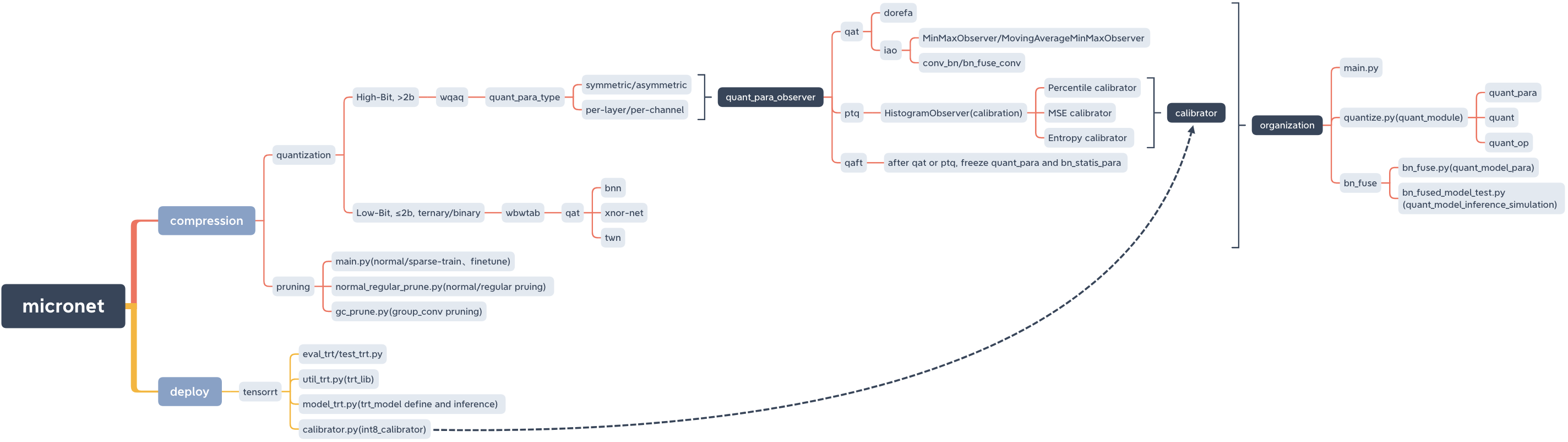
micronet
├── __init__.py
├── base_module
│ ├── __init__.py
│ └── op.py
├── compression
│ ├── README.md
│ ├── __init__.py
│ ├── pruning
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── gc_prune.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── normal_regular_prune.py
│ └── quantization
│ ├── README.md
│ ├── __init__.py
│ ├── wbwtab
│ │ ├── __init__.py
│ │ ├── bn_fuse
│ │ │ ├── bn_fuse.py
│ │ │ ├── bn_fused_model_test.py
│ │ │ └── models_save
│ │ │ └── models_save.txt
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ └── quantize.py
│ └── wqaq
│ ├── __init__.py
│ ├── dorefa
│ │ ├── __init__.py
│ │ ├── main.py
│ │ ├── models_save
│ │ │ └── models_save.txt
│ │ ├── quant_model_test
│ │ │ ├── models_save
│ │ │ │ └── models_save.txt
│ │ │ ├── quant_model_para.py
│ │ │ └── quant_model_test.py
│ │ └── quantize.py
│ └── iao
│ ├── __init__.py
│ ├── bn_fuse
│ │ ├── bn_fuse.py
│ │ ├── bn_fused_model_test.py
│ │ └── models_save
│ │ └── models_save.txt
│ ├── main.py
│ ├── models_save
│ │ └── models_save.txt
│ └── quantize.py
├── data
│ └── data.txt
├── deploy
│ ├── README.md
│ ├── __init__.py
│ └── tensorrt
│ ├── README.md
│ ├── __init__.py
│ ├── calibrator.py
│ ├── eval_trt.py
│ ├── models
│ │ ├── __init__.py
│ │ └── models_trt.py
│ ├── models_save
│ │ └── calibration_seg.cache
│ ├── test_trt.py
│ └── util_trt.py
├── models
│ ├── __init__.py
│ ├── nin.py
│ ├── nin_gc.py
│ └── resnet.py
└── readme_imgs
├── code_structure.jpg
└── micronet.xmind
Pypi
pip install micronet -i https://pypi.org/simpleGithub
git clone https://github.com/666DZY666/micronet.git
cd micronet
python setup.py installverificar
python -c " import micronet; print(micronet.__version__) " Instale no github
--Refine, pode carregar os parâmetros do modelo de ponto flutuante pré-traido e quantizá-los com base neles
--w --a, peso w e apresenta um valor quantizado
cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2python main.py --W 2 --A 32python main.py --W 3 --A 2python main.py --W 3 --A 32--w_bits --a_bits, peso w e apresenta uma contagem de bits quantizada
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 16 --a_bits 16python main.py --w_bits 8 --a_bits 8python main.py --w_bits 4 --a_bits 4 cd micronet/compression/quantization/wqaq/iaoSeleção quantitativa de dígitos iguais ao Dorefa
Cartão único
Qat/ptq -> qaft
! Observe que você precisa fazer qaft após qat/ptq!
--q_type, tipo de quantização (0-simétrico, 1-simétrico)
--q_level, nível de ponderação (nível de 0 canal, 1 nível)
--weight_observer, Weight_observer Seleção (0-Minmaxobserver, 1-MOVINGINGEMINMAXOBSERVER)
--bn_fuse, bandeira de fusão bn em quantificação
--bn_fuse_calib, marca de calibração de fusão bn na quantização
-Modelo de ponto flutuante pré-traido, pré-terenciado
-qaft, sinalizador QAFT
--ptq, ptq_observer
--ptq_control, ptq_control
--ptq_batch, o número de lotes de PTQ
--Percentile, taxa de calibração PTQ
Qat
python main.py --q_type 0 --q_level 0 --weight_observer 0python main.py --q_type 0 --q_level 0 --weight_observer 1python main.py --q_type 0 --q_level 1python main.py --q_type 1 --q_level 0python main.py --q_type 1 --q_level 1python main.py --q_type 0 --q_level 0 --bn_fusepython main.py --q_type 0 --q_level 1 --bn_fusepython main.py --q_type 1 --q_level 0 --bn_fusepython main.py --q_type 1 --q_level 1 --bn_fusepython main.py --q_type 0 --q_level 0 --bn_fuse --bn_fuse_calibPtq
O modelo de ponto flutuante pré-treinado precisa ser carregado, o que pode ser obtido por treinamento normal na poda.
python main.py --refine ../../../pruning/models_save/nin_gc.pth --q_level 0 --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
! Observe que você precisa fazer qaft após qat/ptq!
Qat -> qaft
python main.py --resume models_save/nin_gc_bn_fused.pth --q_type 0 --q_level 0 --bn_fuse --qaft --lr 0.00001PTQ -> QAFT
python main.py --resume models_save/nin_gc_bn_fused.pth --q_level 0 --bn_fuse --qaft --lr 0.00001 --ptqTreinamento esparso -> Avaros -> ajuste fino
cd micronet/compression/pruning-SR Sinal esparso
-S Taxa escassa (precisa ser ajustada de acordo com o conjunto de dados e as condições do modelo)
-Model_type Tipo de modelo (0-NIN, 1-NIN_GC)
python main.py -sr --s 0.0001 --model_type 0python main.py -sr --s 0.001 --model_type 1-Taxa de poda de excesso
-Normal_regulular Normal, bandeiras de poda regular e base de poda regular (se definido como n, o número de filtros por camada do modelo após a poda é um múltiplo de n)
-Modelo o caminho do modelo após treinamento esparso
--SAVE O CAMINHO DE MODELO SALVADO Após a poda (o caminho foi dado por padrão e pode ser alterado de acordo com a situação real)
python normal_regular_prune.py --percent 0.5 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython normal_regular_prune.py --percent 0.5 --normal_regular 8 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthou
python normal_regular_prune.py --percent 0.5 --normal_regular 16 --model models_save/nin_sparse.pth --save models_save/nin_prune.pthpython gc_prune.py --percent 0.4 --model models_save/nin_gc_sparse.pth--prune_refine O caminho do modelo após a poda (ajuste fino com base nele)
python main.py --model_type 0 --prune_refine models_save/nin_prune.pthVocê precisa passar no CFG do novo modelo obtido após a poda
como
python main.py --model_type 1 --gc_prune_refine 154 162 144 304 320 320 608 584Carregue o modelo de ponto flutuante podado e quantize -o
cd micronet/compression/quantization/wqaq/dorefapython main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pthpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wqaq/iaoQat/ptq -> qaft
! Observe que você precisa fazer qaft após qat/ptq!
Qat
BN não fusura
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --lr 0.001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --lr 0.001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_quant ../../../pruning/models_save/nin_gc_retrain.pth --bn_fuse --pretrained_model --lr 0.001Ptq
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_quant ../../../pruning/models_save/nin_finetune.pth --bn_fuse --pretrained_model --ptq_control --ptq --batch_size 32 --ptq_batch 200 --percentile 0.999999Qaft
! Observe que você precisa fazer qaft após qat/ptq!
Qat -> qaft
BN não fusura
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001BN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001python main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001PTQ -> QAFT
BN não fusura
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin.pth --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc.pth --qaft --lr 0.00001 --ptqBN Fusion
python main.py --w_bits 8 --a_bits 8 --model_type 0 --prune_qaft models_save/nin_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptqpython main.py --w_bits 8 --a_bits 8 --model_type 1 --prune_qaft models_save/nin_gc_bn_fused.pth --bn_fuse --qaft --lr 0.00001 --ptq cd micronet/compression/quantization/wbwtabpython main.py --W 2 --A 2 --model_type 0 --prune_quant ../../pruning/models_save/nin_finetune.pthpython main.py --W 2 --A 2 --model_type 1 --prune_quant ../../pruning/models_save/nin_gc_retrain.pth cd micronet/compression/quantization/wbwtab/bn_fuse- -Model_type, 1 -nin_gc (incluindo estrutura convolucional agrupada); 0 - NIN (estrutura convolucional normal)
--prune_quant, pruning_quantitative sinalizador
--W, valor de quantização de peso
Todos precisam ser consistentes com o treinamento quantitativo e você pode usar o padrão diretamente
python bn_fuse.py --model_type 1 --W 2python bn_fuse.py --model_type 1 --prune_quant --W 2python bn_fuse.py --model_type 1 --W 3python bn_fuse.py --model_type 0 --W 2python bn_fused_model_test.py cd micronet/compression/quantization/wqaq/dorefa/quant_model_test- -Model_type, 1 -nin_gc (incluindo estrutura convolucional agrupada); 0 - NIN (estrutura convolucional normal)
--prune_quant, pruning_quantitative sinalizador
--w_bits, número de quantização de peso de bits; --a_bits, quantização de ativação Número de bits
Todos precisam ser consistentes com o treinamento quantitativo e você pode usar o padrão diretamente
python quant_model_para.py --model_type 1 --w_bits 8 --a_bits 8python quant_model_para.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python quant_model_para.py --model_type 0 --w_bits 8 --a_bits 8python quant_model_test.pyObserve que quando o treinamento quantizado -bn_fuse precisa ser definido como true
cd micronet/compression/quantization/wqaq/iao/bn_fuse- -Model_type, 1 -nin_gc (incluindo estrutura convolucional agrupada); 0 - NIN (estrutura convolucional normal)
--prune_quant, pruning_quantitative sinalizador
--w_bits, número de quantização de peso de bits; --a_bits, quantização de ativação Número de bits
--q_type, 0 -simétrico; 1 - assimétrico
--q_level, 0 -nível de canal; 1 - nível
Todos precisam ser consistentes com o treinamento quantitativo e você pode usar o padrão diretamente
python bn_fuse.py --model_type 1 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 1 --prune_quant --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8python bn_fuse.py --model_type 0 --w_bits 8 --a_bits 8 --q_type 1 --q_level 1python bn_fused_model_test.pyAgora suporta CPU e GPU (cartão único, cartão múltiplo)
-CPU Use CPU,--GPU_ID Use e selecione GPU
python main.py --cpupython main.py --gpu_id 0ou
python main.py --gpu_id 1python main.py --gpu_id 0,1ou
python main.py --gpu_id 0,1,2Por padrão, use o cartão completo do servidor
Atualmente, apenas o código do módulo principal relevante é fornecido e uma demonstração completa do Runnable será adicionada posteriormente.
Um modelo pode ser quantizado (alto bit (> 2b), baixo bit (≤2b)/ternário e binário) simplesmente substituindo OP pelo quant_OP .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
# ``quantize`` is quant_module, ``QuantConv2d``, ``QuantLinear``, ``QuantMaxPool2d``, ``QuantReLU`` are quant_op
from micronet . compression . quantization . wbwtab . quantize import (
QuantConv2d as quant_conv_wbwtab ,
)
from micronet . compression . quantization . wbwtab . quantize import (
ActivationQuantizer as quant_relu_wbwtab ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantConv2d as quant_conv_dorefa ,
)
from micronet . compression . quantization . wqaq . dorefa . quantize import (
QuantLinear as quant_linear_dorefa ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantConv2d as quant_conv_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantLinear as quant_linear_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantMaxPool2d as quant_max_pool_iao ,
)
from micronet . compression . quantization . wqaq . iao . quantize import (
QuantReLU as quant_relu_iao ,
)
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetWbWtAb ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetWbWtAb , self ). __init__ ()
self . conv1 = quant_conv_wbwtab ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_wbwtab ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = quant_relu_wbwtab ()
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetDoReFa ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetDoReFa , self ). __init__ ()
self . conv1 = quant_conv_dorefa ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_dorefa ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_dorefa ( 320 , 50 )
self . fc2 = quant_linear_dorefa ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
class QuantLeNetIAO ( nn . Module ):
def __init__ ( self ):
super ( QuantLeNetIAO , self ). __init__ ()
self . conv1 = quant_conv_iao ( 1 , 10 , kernel_size = 5 )
self . conv2 = quant_conv_iao ( 10 , 20 , kernel_size = 5 )
self . fc1 = quant_linear_iao ( 320 , 50 )
self . fc2 = quant_linear_iao ( 50 , 10 )
self . max_pool = quant_max_pool_iao ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
lenet = LeNet ()
quant_lenet_wbwtab = QuantLeNetWbWtAb ()
quant_lenet_dorefa = QuantLeNetDoReFa ()
quant_lenet_iao = QuantLeNetIAO ()
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_wbwtab*** n " , quant_lenet_wbwtab )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )Um modelo pode ser quantizado (alto bit (> 2b), baixo bit (≤2b)/ternário e binário) simplesmente usando o micronet.compression.quantization.quantize.prepare (modelo) .
import torch . nn as nn
import torch . nn . functional as F
# some base_op, such as ``Add``、``Concat``
from micronet . base_module . op import *
import micronet . compression . quantization . wqaq . dorefa . quantize as quant_dorefa
import micronet . compression . quantization . wqaq . iao . quantize as quant_iao
class LeNet ( nn . Module ):
def __init__ ( self ):
super ( LeNet , self ). __init__ ()
self . conv1 = nn . Conv2d ( 1 , 10 , kernel_size = 5 )
self . conv2 = nn . Conv2d ( 10 , 20 , kernel_size = 5 )
self . fc1 = nn . Linear ( 320 , 50 )
self . fc2 = nn . Linear ( 50 , 10 )
self . max_pool = nn . MaxPool2d ( kernel_size = 2 )
self . relu = nn . ReLU ( inplace = True )
def forward ( self , x ):
x = self . relu ( self . max_pool ( self . conv1 ( x )))
x = self . relu ( self . max_pool ( self . conv2 ( x )))
x = x . view ( - 1 , 320 )
x = self . relu ( self . fc1 ( x ))
x = F . dropout ( x , training = self . training )
x = self . fc2 ( x )
return F . log_softmax ( x , dim = 1 )
"""
--w_bits --a_bits, 权重W和特征A量化位数
--q_type, 量化类型(0-对称, 1-非对称)
--q_level, 权重量化级别(0-通道级, 1-层级)
--weight_observer, weight_observer选择(0-MinMaxObserver, 1-MovingAverageMinMaxObserver)
--bn_fuse, 量化中bn融合标志
--bn_fuse_calib, 量化中bn融合校准标志
--pretrained_model, 预训练浮点模型
--qaft, qaft标志
--ptq, ptq标志
--percentile, ptq校准的比例
"""
lenet = LeNet ()
quant_lenet_dorefa = quant_dorefa . prepare ( lenet , inplace = False , a_bits = 8 , w_bits = 8 )
quant_lenet_iao = quant_iao . prepare (
lenet ,
inplace = False ,
a_bits = 8 ,
w_bits = 8 ,
q_type = 0 ,
q_level = 0 ,
weight_observer = 0 ,
bn_fuse = False ,
bn_fuse_calib = False ,
pretrained_model = False ,
qaft = False ,
ptq = False ,
percentile = 0.9999 ,
)
# if ptq == False, do qat/qaft, need train
# if ptq == True, do ptq, don't need train
# you can refer to micronet/compression/quantization/wqaq/iao/main.py
print ( "***ori_model*** n " , lenet )
print ( " n ***quant_model_dorefa*** n " , quant_lenet_dorefa )
print ( " n ***quant_model_iao*** n " , quant_lenet_iao )
print ( " n quant_model is ready" )
print ( "micronet is ready" )python -c " import micronet; micronet.quant_test_manual() " python -c " import micronet; micronet.quant_test_auto() "Ao produzir "quant_model está pronto", o microt está pronto.
Referência BN Fusion e Teste Quantitativo de Simulação de Inferência
A seguir, é apresentado um exemplo do CIFAR10, onde você pode tentar outros métodos combinados de compressão em modelos mais redundantes e conjuntos de dados maiores.
| tipo | W (bits) | A (bits) | Acc | GFLOPS | Para (M) | Tamanho (MB) | Taxa de compressão | perda |
|---|---|---|---|---|---|---|---|---|
| Modelo original (NIN) | Fp32 | Fp32 | 91,01% | 0,15 | 0,67 | 2.68 | *** | *** |
| Usando a estrutura de convolução de agrupamento (Nin_GC) | Fp32 | Fp32 | 91,04% | 0,15 | 0,58 | 2.32 | 13,43% | -0,03% |
| Podando | Fp32 | Fp32 | 90,26% | 0,09 | 0,32 | 1.28 | 52,24% | 0,75% |
| Quantificação | 1 | Fp32 | 90,93% | *** | 0,58 | 0,204 | 92,39% | 0,08% |
| Quantificação | 1.5 | Fp32 | 91% | *** | 0,58 | 0,272 | 89,85% | 0,01% |
| Quantificação | 1 | 1 | 86,23% | *** | 0,58 | 0,204 | 92,39% | 4,78% |
| Quantificação | 1.5 | 1 | 86,48% | *** | 0,58 | 0,272 | 89,85% | 4,53% |
| Quantificação (Dorefa) | 8 | 8 | 91,03% | *** | 0,58 | 0,596 | 77,76% | -0,02% |
| Quantificação (IAO, quantificação total, simétrica/por canal/bn_fuse) | 8 | 8 | 90,99% | *** | 0,58 | 0,596 | 77,76% | 0,02% |
| Agrupamento + podaing + quantização | 1.5 | 1 | 86,13% | *** | 0,32 | 0,19 | 92,91% | 4,88% |
--train_batch_size 256, cartão único
BinarizedneuralNetworks: TreiningNeuralNetworks WithweightSands e ativações, para +1 ou -1
XNOR-NET: ImageNetClassi fi cusingbinary ConvolucionalNeuralNetworks
Um estudo empírico da otimização das redes neurais binárias
Uma revisão de redes neurais binarizadas


