contrastive unpaired translation
1.0.0

เราให้การใช้งานการแปลภาพเป็นภาพเป็นภาพที่ไม่มีคู่โดยใช้การเรียนรู้แบบตรงกันข้ามและการเรียนรู้ที่เป็นปฏิปักษ์ ไม่มีการใช้งานที่สร้างขึ้นด้วยมือและเครือข่ายผกผัน เมื่อเทียบกับ Cyclegan การฝึกอบรมแบบจำลองของเรานั้นเร็วขึ้นและใช้หน่วยความจำน้อยลง นอกจากนี้วิธีการของเราสามารถขยายไปสู่การฝึกอบรมภาพเดี่ยวโดยที่ "โดเมน" แต่ละรายการเป็นเพียงภาพ เดียว
การเรียนรู้แบบตรงกันข้ามสำหรับการแปลภาพเป็นภาพที่ไม่มีคู่
Taesung Park, Alexei A. Efros, Richard Zhang, Jun-yan Zhu
UC Berkeley และ Adobe Research
ใน ECCV 2020

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020: เพิ่มการแปลภาพเดียว
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTติดตั้ง pytorch 1.1 และการพึ่งพาอื่น ๆ (เช่น torchvision, visdom, ครอบงำ, gputil)
สำหรับผู้ใช้ PIP โปรดพิมพ์คำสั่ง pip install -r requirements.txt
สำหรับผู้ใช้ Conda คุณสามารถสร้างสภาพแวดล้อม conda ใหม่โดยใช้ conda env create -f environment.yml
grumpifycat (รูปที่ 8 ของกระดาษรัสเซียสีน้ำเงิน -> แมว Grumpy) bash ./datasets/download_cut_dataset.sh grumpifycat ชุดข้อมูลจะถูกดาวน์โหลดและคลายซิปที่ ./datasets/grumpifycat/ grumpifycat/
หากต้องการดูผลการฝึกอบรมและแปลงการสูญเสียให้เรียกใช้ python -m visdom.server และคลิก URL http: // localhost: 8097
ฝึกอบรมรุ่นตัด:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTหรือฝึกอบรมรุ่น Fastcut
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT จุดตรวจจะถูกเก็บไว้ที่ ./checkpoints/grumpycat_*/web grumpycat_*/web
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train ผลการทดสอบจะถูกบันทึกลงในไฟล์ html ที่นี่: ./results/grumpifycat/latest_train/index.html
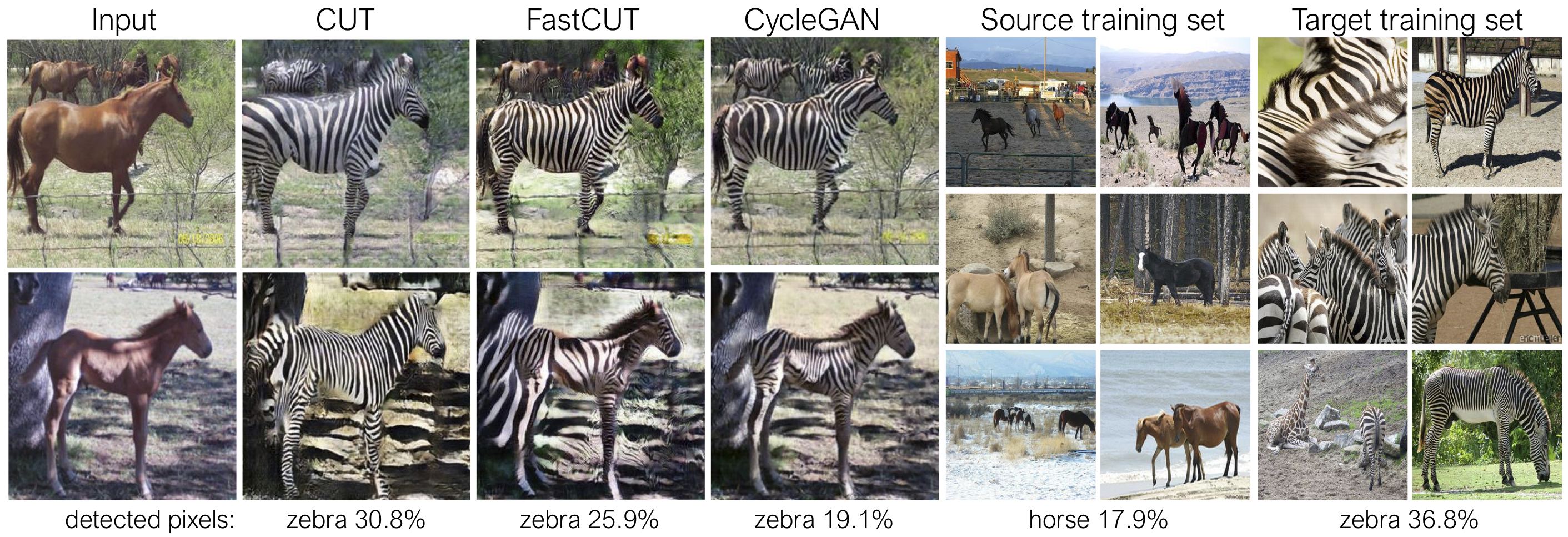
การตัดได้รับการฝึกฝนด้วยการสูญเสียการเก็บรักษาตัวตนและด้วย lambda_NCE=1 ในขณะที่ Fastcut ได้รับการฝึกฝนโดยไม่มีการสูญเสียตัวตน แต่มี lambda_NCE=10.0 เมื่อเปรียบเทียบกับ Cyclegan, Cut เรียนรู้ที่จะทำการจับคู่การกระจายที่ทรงพลังมากขึ้นในขณะที่ FastCut ได้รับการออกแบบให้เป็นหน่วยความจำที่เบากว่า (ครึ่งหนึ่งของหน่วยความจำ GPU สามารถพอดีกับภาพที่ใหญ่กว่า) และเร็วกว่า โปรดดูเอกสารสำหรับรายละเอียดเพิ่มเติม
ในรูปด้านบนเราวัดเปอร์เซ็นต์ของพิกเซลที่อยู่ในร่างกายของม้า/ม้าลายโดยใช้แบบจำลองการแบ่งส่วนความหมายที่ผ่านการฝึกอบรมมาก่อน เราพบว่าการกระจายความไม่ตรงกันระหว่างขนาดของม้าและภาพม้าลาย - ม้าลายมักจะมีขนาดใหญ่กว่า (36.8% เทียบกับ 17.9%) วิธีการตัดเต็มวิธีของเรามีความยืดหยุ่นในการขยายม้าซึ่งเป็นวิธีการจับคู่สถิติการฝึกอบรมที่ดีกว่า Cyclegan Fastcut ทำงานอย่างอนุรักษ์นิยมมากขึ้นเช่น Cyclegan
โปรดดู experiments/grumpifycat_launcher.py ที่สร้างอาร์กิวเมนต์บรรทัดคำสั่งข้างต้น สคริปต์ Launcher มีประโยชน์สำหรับการกำหนดค่าอาร์กิวเมนต์บรรทัดคำสั่งที่ซับซ้อนของการฝึกอบรมและการทดสอบ
การใช้ตัวเรียกใช้งานคำสั่งด้านล่างสร้างคำสั่งการฝึกอบรมของการตัดและ fastcut
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTเพื่อทดสอบโดยใช้ตัวเรียกใช้งาน
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT คำสั่งที่เป็นไปได้คือรัน, run_test, เปิดตัว, ปิดและอื่น ๆ โปรดดู experiments/__main__.py สำหรับคำสั่งทั้งหมด Launcher นั้นง่ายและรวดเร็วในการกำหนดและใช้งาน ตัวอย่างเช่นตัวเรียกใช้งาน grumpifycat ถูกกำหนดในไม่กี่บรรทัด:
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]ในการเรียกใช้โมเดลที่ผ่านการฝึกฝนให้เรียกใช้สิ่งต่อไปนี้
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
หมายเหตุ: รูปแบบของ CityScapes Pretrained ได้รับการฝึกอบรมและประเมินผลในชุดข้อมูล CityScapes รุ่นดั้งเดิมที่ปรับขนาดและ JPEG ในการประเมินผลโปรดดาวน์โหลดชุดการตรวจสอบนี้และทำการประเมินผล
ในการฝึกอบรม sincut (การแปลภาพเดียวแสดงในรูปที่ 9, 13 และ 14 ของกระดาษ) คุณต้อง
--model เป็น --model sincut ซึ่งเรียกใช้การกำหนดค่าและรหัสที่ ./models/sincut_model.py และ./datasets/single_image_monet_etretat/ single_image_monet_etretat/ตัวอย่างเช่นในการฝึกอบรมแบบจำลองสำหรับหน้าผา Etretat (ภาพแรกของรูปที่ 13) โปรดใช้คำสั่งต่อไปนี้
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatหรือโดยใช้สคริปต์ Launcher Experiment
python -m experiments singleimage run 0 สำหรับการแปลภาพเดียวเราใช้ส่วนประกอบสถาปัตยกรรมเครือข่ายของ Stylegan2 เช่นเดียวกับการสูญเสียการเก็บรักษาพิกเซลที่ใช้ใน DTN และ Cyclegan โดยเฉพาะอย่างยิ่งเราใช้รหัสของ Rosinality ซึ่งมีอยู่ที่ models/stylegan_networks.py
การฝึกอบรมใช้เวลาหลายชั่วโมง เพื่อสร้างภาพสุดท้ายโดยใช้จุดตรวจ
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatหรือเพียงอย่างเดียว
python -m experiments singleimage run_test 0ดาวน์โหลดชุดข้อมูล Cut/Cyclegan/Pix2Pix ตัวอย่างเช่น,
bash datasets/download_cut_datasets.sh horse2zebra ชุดข้อมูล CAT2DOG จัดทำขึ้นจากชุดข้อมูล AFHQ กรุณาเยี่ยมชม https://github.com/clovaai/stargan-v2 และดาวน์โหลดชุดข้อมูล AFHQ โดย bash download.sh afhq-dataset ของ GitHub repo จากนั้นจัดระเบียบไดเรกทอรีใหม่ดังนี้
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog ชุดข้อมูล CityScapes สามารถดาวน์โหลดได้จาก https://cityscapes-dataset.com หลังจากนั้นให้ใช้สคริปต์ ./datasets/prepare_cityscapes_dataset.py เพื่อเตรียมชุดข้อมูล
การประมวลผลล่วงหน้าของภาพอินพุตเช่นการปรับขนาดหรือการปลูกพืชแบบสุ่มถูกควบคุมโดยตัวเลือก --preprocess , --load_size และ --crop_size การใช้งานติดตาม repo pyclegan/pix2pix
ตัวอย่างเช่นการตั้งค่าเริ่มต้น --preprocess resize_and_crop --load_size 286 --crop_size 256 ปรับขนาดภาพอินพุตเป็น 286x286 จากนั้นทำให้การเพาะปลูกแบบสุ่มขนาด 256x256 เป็นวิธีการเพิ่มข้อมูล มีตัวเลือกการประมวลผลล่วงหน้าอื่น ๆ ที่สามารถระบุได้และมีการระบุไว้ใน base_dataset.py ด้านล่างนี้เป็นตัวเลือกตัวอย่าง
--preprocess none : ไม่ดำเนินการล่วงหน้าใด ๆ โปรดทราบว่าขนาดภาพยังคงถูกปรับขนาดให้เป็นหลายตัวที่ใกล้เคียงที่สุดของ 4 เนื่องจากเครื่องกำเนิดไฟฟ้า convolutional ไม่สามารถรักษาขนาดภาพเดียวกันได้--preprocess scale_width --load_size 768 : ปรับความกว้างของภาพให้มีขนาด 768--preprocess scale_shortside_and_crop : ปรับอัตราส่วนการรักษาภาพเพื่อให้ด้านสั้นคือ load_size จากนั้นทำการปลูกพืชแบบสุ่มของขนาดหน้าต่าง crop_size ตัวเลือกการประมวลผลล่วงหน้าเพิ่มเติมสามารถเพิ่มได้โดยการแก้ไข get_transform() ของ base_dataset.py
หากคุณใช้รหัสนี้สำหรับการวิจัยของคุณโปรดอ้างอิงบทความของเรา
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
หากคุณใช้โมเดล Pix2Pix และ Cyclegan ดั้งเดิมที่รวมอยู่ใน repo นี้โปรดอ้างอิงเอกสารต่อไปนี้
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
เราขอขอบคุณ Allan Jabri และ Phillip Isola สำหรับการอภิปรายและข้อเสนอแนะที่เป็นประโยชน์ รหัสของเราได้รับการพัฒนาตาม pytorch-cyclegan-and-pix2pix นอกจากนี้เรายังขอขอบคุณ Pytorch-Fid สำหรับการคำนวณ FID, DRN สำหรับการคำนวณ MIOU และ Stylegan2-Pytorch สำหรับการใช้งาน Pytorch ของ Stylegan2 ที่ใช้ในการตั้งค่าการแปลภาพเดียวของเรา


