contrastive unpaired translation
1.0.0

パッチワイズの対照学習と敵対学習に基づいて、Pytorchのイメージから画像間翻訳のPytorchの実装を提供します。手作りの損失と逆ネットワークは使用されません。 Cycleganと比較して、私たちのモデルトレーニングはより速く、メモリ集約的ではありません。さらに、この方法は単一の画像トレーニングに拡張できます。この方法では、各「ドメイン」は単一の画像にすぎません。
対応のない画像から画像への翻訳の対照学習
Taesung Park、Alexei A. Efros、Richard Zhang、Jun-Yan Zhu
UC BerkeleyとAdobe Research
ECCV 2020で

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020:シングルイメージ翻訳を追加しました。
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTPytorch 1.1およびその他の依存関係(たとえば、Torchvision、Visom、Dominate、Gputil)をインストールします。
PIPユーザーの場合は、コマンドpip install -r requirements.txtを入力してください。txt。
Condaユーザーの場合、 conda env create -f environment.ymlを使用して新しいConda環境を作成できます。
grumpifycatデータセットをダウンロードします(論文の図8。RussianBlue->不機嫌そうな猫) bash ./datasets/download_cut_dataset.sh grumpifycatデータセットはダウンロードされ、 ./datasets/grumpifycat/ datasets/grumpifycat/で解凍されます。
トレーニング結果と損失プロットを表示するには、 python -m visdom.serverを実行し、URL http:// localhost:8097をクリックします。
カットモデルをトレーニングします:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTまたは、FastCutモデルをトレーニングします
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUTチェックポイントは./checkpoints/grumpycat_*/web Grumpycat_*/webに保存されます。
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase trainテスト結果は、こちらのHTMLファイルに保存されます: ./results/grumpifycat/latest_train/index.html /latest_train/index.html。
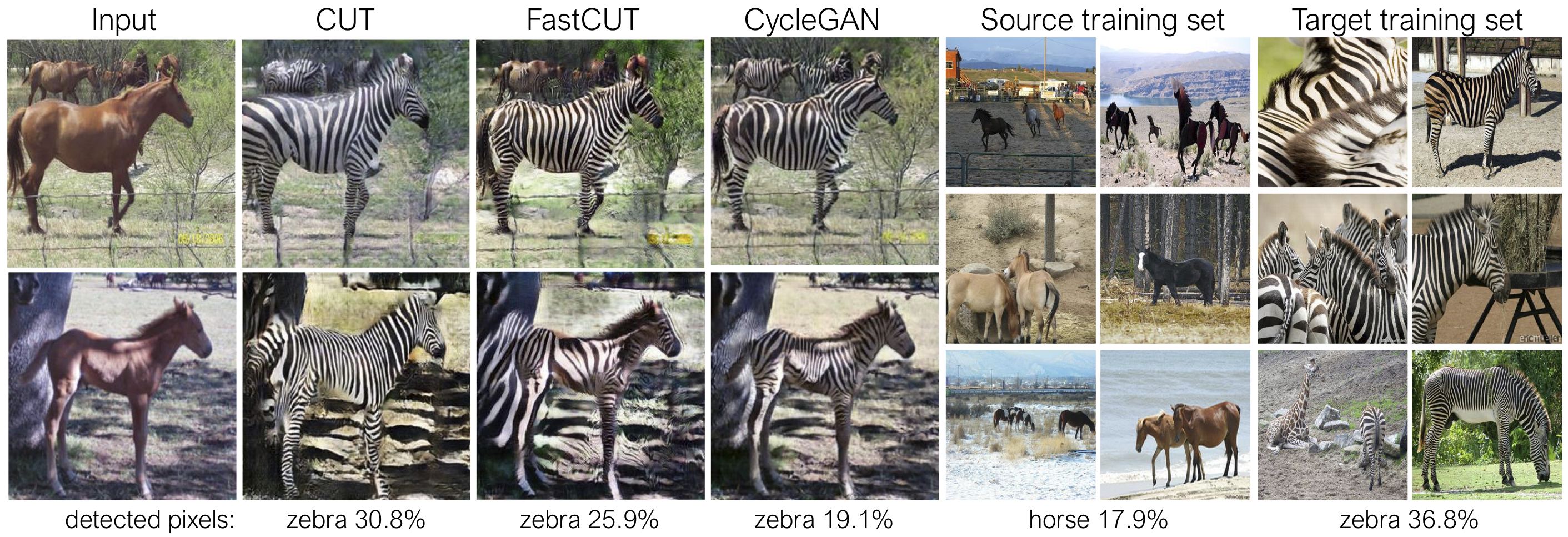
カットは、アイデンティティの保存損失とlambda_NCE=1で訓練されますが、FastCutはアイデンティティの損失なしで訓練されますが、 lambda_NCE=10.0が高くなります。 Cycleganと比較して、Cutはより強力な分布マッチングを実行することを学びますが、FastCutはより軽い(GPUメモリの半分、より大きな画像に適合することができます)、Cycleganに代わるより速く(トレーニングが2倍高速)設計されています。詳細については、論文を参照してください。
上記の図では、事前に訓練されたセマンティックセグメンテーションモデルを使用して、馬/ゼブラ体に属するピクセルの割合を測定します。馬のサイズとゼブラの画像間の分布の不一致が見つかります - ゼブラは通常大きく見えます(36.8%対17.9%)。私たちの完全なメソッドカットには、Cycleganよりもトレーニング統計をよりよく一致させる手段として、馬を拡大する柔軟性があります。 FastCutはCycleganのように控えめに動作します。
上記のコマンドライン引数を生成するexperiments/grumpifycat_launcher.pyご覧ください。ランチャースクリプトは、トレーニングとテストのかなり複雑なコマンドライン引数を構成するのに役立ちます。
ランチャーを使用して、以下のコマンドは、カットとファストカットのトレーニングコマンドを生成します。
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTランチャーを使用してテストするには、
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT可能なコマンドは実行、run_test、起動、閉じるなどです。すべてのコマンドについてはexperiments/__main__.py参照してください。ランチャーは簡単で迅速に定義して使用できます。たとえば、GrumpifyCatランチャーは数行で定義されています。
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]事前に守られたモデルを実行するには、以下を実行します。
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
注:Cityscapesの前提条件モデルは、元のCityscapesデータセットのサイズ変更されたJPEG圧縮バージョンでトレーニングおよび評価されました。評価を実行するには、この検証セットをダウンロードして評価を実行してください。
sincut(紙の図9、13、14に示すシングルイメージの翻訳)を訓練するには、
--modelオプションを--model sincutとして設定します。これは、 ./models/sincut_model.py sincut_model.pyで構成とコードを呼び出します。./datasets/single_image_monet_etretat/に含まれるデータセットの例など、各ドメインの1つの画像のデータセットディレクトリを指定します。たとえば、エトレタットクリフのモデルをトレーニングするには、次のコマンドを使用してください。
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatまたは、実験ランチャースクリプトを使用することにより、
python -m experiments singleimage run 0シングルイメージ翻訳のために、StyleGan2のネットワークアーキテクチャコンポーネントと、DTNおよびCycleGanで使用されるピクセルIDの保存損失を採用しています。特に、 models/stylegan_networks.pyに存在するロジナリティのコードを採用しました。
トレーニングには数時間かかります。チェックポイントを使用して最終画像を生成するには、
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatまたは単に
python -m experiments singleimage run_test 0Cut/CycleGan/PIX2PIXデータセットをダウンロードします。例えば、
bash datasets/download_cut_datasets.sh horse2zebra CAT2DOGデータセットは、AFHQデータセットから準備されています。 https://github.com/clovaai/stargan-v2にアクセスし、 bash download.sh afhq-dataset of the Github RepoでAFHQデータセットをダウンロードしてください。次に、次のようにディレクトリを再編成します。
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog Cityscapesデータセットは、https://cityscapes-dataset.comからダウンロードできます。その後、スクリプト./datasets/prepare_cityscapes_dataset.pyを使用して、データセットを準備します。
サイズ変更やランダムトリッピングなどの入力画像の前処理は、オプション--preprocess 、 --load_size 、および--crop_sizeによって制御されます。使用状況は、CycleGan/PIX2PIXリポジトリに従います。
たとえば、デフォルトの設定--preprocess resize_and_crop --load_size 286 --crop_size 256 、入力画像を286x286にサイズ変更し、データ増強を実行する方法としてサイズ256x256のランダムクロップを作成します。指定できる他の前処理オプションがあり、base_dataset.pyで指定されています。以下はいくつかの例のオプションです。
--preprocess none :前処理を実行しません。畳み込みの発電機はそれ以外の場合は同じ画像サイズを維持できないため、画像サイズは4の最も近い倍数にスケーリングされていることに注意してください。--preprocess scale_width --load_size 768 :画像の幅をサイズ768にスケーリングします。--preprocess scale_shortside_and_crop :画像を保存するアスペクト比をスケーリングして、短い側がload_sizeになり、ウィンドウサイズのcrop_sizeのランダムなトリミングを実行します。 base_dataset.pyのget_transform()変更することにより、より多くの前処理オプションを追加できます。
このコードを調査に使用する場合は、私たちの論文を引用してください。
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
このリポジトリに含まれる元のPix2PixおよびCycleganモデルを使用する場合は、次の論文を引用してください
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
有益な議論とフィードバックをしてくれたアラン・ジャブリとフィリップ・イソラに感謝します。私たちのコードは、Pytorch-Cyclegan-and-Pix2pixに基づいて開発されています。また、FID計算についてはPytorch-Fid、MIOU計算のためのDRN、および単一イメージ翻訳設定で使用されているStyleGan2のPytorch実装については、StyleGan2-Pytorchに感謝します。


