contrastive unpaired translation
1.0.0

Kami menyediakan implementasi pytorch kami dari terjemahan gambar-ke-gambar yang tidak berpasangan berdasarkan pembelajaran kontras dan pembelajaran permusuhan. Tidak ada kerugian kerajinan tangan dan jaringan terbalik. Dibandingkan dengan Cyclegan, pelatihan model kami lebih cepat dan kurang intensif memori. Selain itu, metode kami dapat diperluas ke pelatihan gambar tunggal, di mana setiap "domain" hanya satu gambar.
Pembelajaran kontras untuk terjemahan gambar-ke-gambar yang tidak berpasangan
Taman Taesung, Alexei A. Efros, Richard Zhang, Jun-Yan Zhu
Penelitian UC Berkeley dan Adobe
Di ECCV 2020

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020: Menambahkan terjemahan image tunggal.
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTInstal Pytorch 1.1 dan dependensi lainnya (misalnya, Torchvision, Visdom, Dominate, Gputil).
Untuk pengguna PIP, silakan ketik perintah pip install -r requirements.txt .
Untuk pengguna Conda, Anda dapat membuat lingkungan Conda baru menggunakan conda env create -f environment.yml .
grumpifycat (Gambar 8 dari Kertas. Rusia Biru -> Kucing pemarah) bash ./datasets/download_cut_dataset.sh grumpifycat Dataset diunduh dan dibuka ritsleting di ./datasets/grumpifycat/ .
Untuk melihat hasil pelatihan dan plot kerugian, jalankan python -m visdom.server dan klik url http: // localhost: 8097.
Latih model cut:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTAtau latih model FastCut
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT Pos pemeriksaan akan disimpan di ./checkpoints/grumpycat_*/web .
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train Hasil tes akan disimpan ke file html di sini: ./results/grumpifycat/latest_train/index.html .
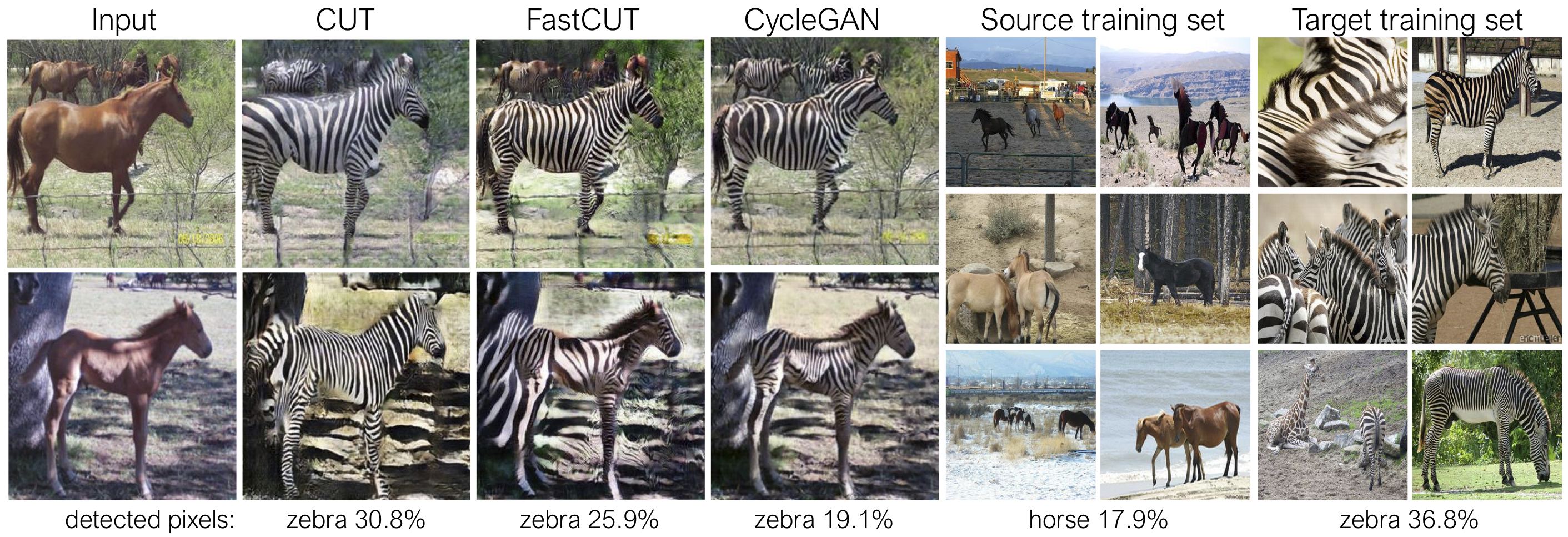
Cut dilatih dengan kehilangan pelestarian identitas dan dengan lambda_NCE=1 , sementara fastcut dilatih tanpa kehilangan identitas tetapi dengan lambda_NCE=10.0 . Dibandingkan dengan Cyclegan, Cut belajar untuk melakukan pencocokan distribusi yang lebih kuat, sementara FastCut dirancang sebagai lebih ringan (setengah memori GPU, dapat sesuai dengan gambar yang lebih besar), dan lebih cepat (dua kali lebih cepat untuk melatih) alternatif untuk Cyclegan. Silakan merujuk ke kertas untuk lebih jelasnya.
Pada gambar di atas, kami mengukur persentase piksel milik tubuh kuda/zebra, menggunakan model segmentasi semantik pra-terlatih. Kami menemukan ketidakcocokan distribusi antara ukuran kuda dan gambar zebra - zebra biasanya tampak lebih besar (36,8% vs 17,9%). Potongan metode penuh kami memiliki fleksibilitas untuk memperbesar kuda, sebagai sarana pencocokan statistik pelatihan yang lebih baik daripada Cyclegan. Fastcut berperilaku lebih konservatif seperti Cyclegan.
Silakan lihat experiments/grumpifycat_launcher.py yang menghasilkan argumen baris perintah di atas. Script peluncur berguna untuk mengkonfigurasi argumen baris perintah yang agak rumit tentang pelatihan dan pengujian.
Menggunakan peluncur, perintah di bawah ini menghasilkan perintah pelatihan cut dan fastcut.
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTUntuk menguji menggunakan peluncur,
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT Perintah yang mungkin dijalankan, run_test, peluncuran, tutup, dan sebagainya. Silakan lihat experiments/__main__.py untuk semua perintah. Peluncur mudah dan cepat untuk didefinisikan dan digunakan. Misalnya, peluncur GrumpifyCat didefinisikan dalam beberapa baris:
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]Untuk menjalankan model pretrained, jalankan yang berikut.
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
CATATAN: Model pretrained CityScapes dilatih dan dievaluasi pada versi yang diubah ukurannya dan JPEG yang dikompresi dari dataset Cityscapes asli. Untuk melakukan evaluasi, silakan unduh set validasi ini dan lakukan evaluasi.
Untuk melatih Sincut (terjemahan gambar tunggal, ditunjukkan pada Gambar 9, 13 dan 14 dari makalah), Anda perlu
--model sebagai --model sincut , yang memohon konfigurasi dan kode di ./models/sincut_model.py , dan./datasets/single_image_monet_etretat/ .Misalnya, untuk melatih model untuk Etretat Cliff (gambar pertama dari Gambar 13), silakan gunakan perintah berikut.
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatatau dengan menggunakan skrip peluncur eksperimen,
python -m experiments singleimage run 0 Untuk terjemahan gambar tunggal, kami mengadopsi komponen arsitektur jaringan StyleGan2, serta kehilangan pelestarian identitas piksel yang digunakan dalam DTN dan Cyclegan. Secara khusus, kami mengadopsi kode rosinalitas, yang ada di models/stylegan_networks.py .
Pelatihan memakan waktu beberapa jam. Untuk menghasilkan gambar akhir menggunakan pos pemeriksaan,
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatatau sederhana
python -m experiments singleimage run_test 0Unduh Dataset Cut/Cyclegan/Pix2pix. Misalnya,
bash datasets/download_cut_datasets.sh horse2zebra Dataset CAT2DOG disiapkan dari dataset AFHQ. Silakan kunjungi https://github.com/clovaai/sargan-v2 dan unduh dataset AFHQ oleh bash download.sh afhq-dataset dari github repo. Kemudian periksa kembali direktori sebagai berikut.
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog Dataset CityScapes dapat diunduh dari https://cityscapes-dataset.com. Setelah itu, gunakan skrip ./datasets/prepare_cityscapes_dataset.py untuk menyiapkan dataset.
Preprocessing dari gambar input, seperti mengubah ukuran atau penanaman acak, dikendalikan oleh opsi --preprocess , --load_size , dan --crop_size . Penggunaan mengikuti repo Cyclegan/Pix2pix.
Misalnya, pengaturan default --preprocess resize_and_crop --load_size 286 --crop_size 256 mengubah ukuran gambar input menjadi 286x286 , dan kemudian membuat tanaman acak berukuran 256x256 sebagai cara untuk melakukan augmentasi data. Ada opsi preprocessing lain yang dapat ditentukan, dan mereka ditentukan dalam base_dataset.py. Di bawah ini adalah beberapa opsi contoh.
--preprocess none : Tidak melakukan preprocessing. Perhatikan bahwa ukuran gambar masih diskalakan menjadi kelipatan terdekat dari 4, karena generator konvolusional tidak dapat mempertahankan ukuran gambar yang sama sebaliknya.--preprocess scale_width --load_size 768 : skala lebar gambar berukuran 768.--preprocess scale_shortside_and_crop : skala rasio aspek pelestarian gambar sehingga sisi pendeknya adalah load_size , dan kemudian melakukan pemangkasan acak ukuran jendela crop_size . Opsi preprocessing lebih banyak dapat ditambahkan dengan memodifikasi get_transform() dari base_dataset.py .
Jika Anda menggunakan kode ini untuk penelitian Anda, silakan kutip makalah kami.
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
Jika Anda menggunakan model pix2pix dan cyclegan asli yang termasuk dalam repo ini, silakan kutip makalah berikut
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
Kami berterima kasih kepada Allan Jabri dan Phillip Isola atas diskusi dan umpan balik yang bermanfaat. Kode kami dikembangkan berdasarkan Pytorch-Cyclegan dan Pix2pix. Kami juga berterima kasih kepada Pytorch-Fid untuk komputasi FID, DRN untuk komputasi MIOU, dan StyleGan2-Pytorch untuk implementasi Pytorch dari StyleGan2 yang digunakan dalam pengaturan terjemahan gambar tunggal kami.


