contrastive unpaired translation
1.0.0

Proporcionamos nuestra implementación de Pytorch de la traducción de imagen a imagen no apareada basada en el aprendizaje contrastante de parche y el aprendizaje adversario. No se usa pérdida hecha a mano ni red inversa. En comparación con Cyclegan, nuestro entrenamiento modelo es más rápido y menos intensivo en la memoria. Además, nuestro método se puede extender al entrenamiento de una sola imagen, donde cada "dominio" es solo una imagen.
Aprendizaje contrastante para la traducción de imagen a imagen no emparejada
Parque Taesung, Alexei A. Efros, Richard Zhang, Jun-Yan Zhu
UC Berkeley y Adobe Research
En ECCV 2020

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020: Traducción de imagen única agregada.
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTInstale Pytorch 1.1 y otras dependencias (p. Ej.
Para los usuarios de PIP, escriba el comando pip install -r requirements.txt .
Para los usuarios de Conda, puede crear un nuevo entorno de conda utilizando conda env create -f environment.yml .
grumpifycat (Fig. 8 del documento. Azul ruso -> Cats Grumpy) bash ./datasets/download_cut_dataset.sh grumpifycat El conjunto de datos se descarga y se desabrocha en ./datasets/grumpifycat/ .
Para ver los resultados del entrenamiento y las tramas de pérdida, ejecute python -m visdom.server y haga clic en la url http: // localhost: 8097.
Entrena el modelo de corte:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTO entrenar el modelo Fastcut
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT Los puntos de control se almacenarán en ./checkpoints/grumpycat_*/web .
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train Los resultados de la prueba se guardarán en un archivo HTML aquí: ./results/grumpifycat/latest_train/index.html .
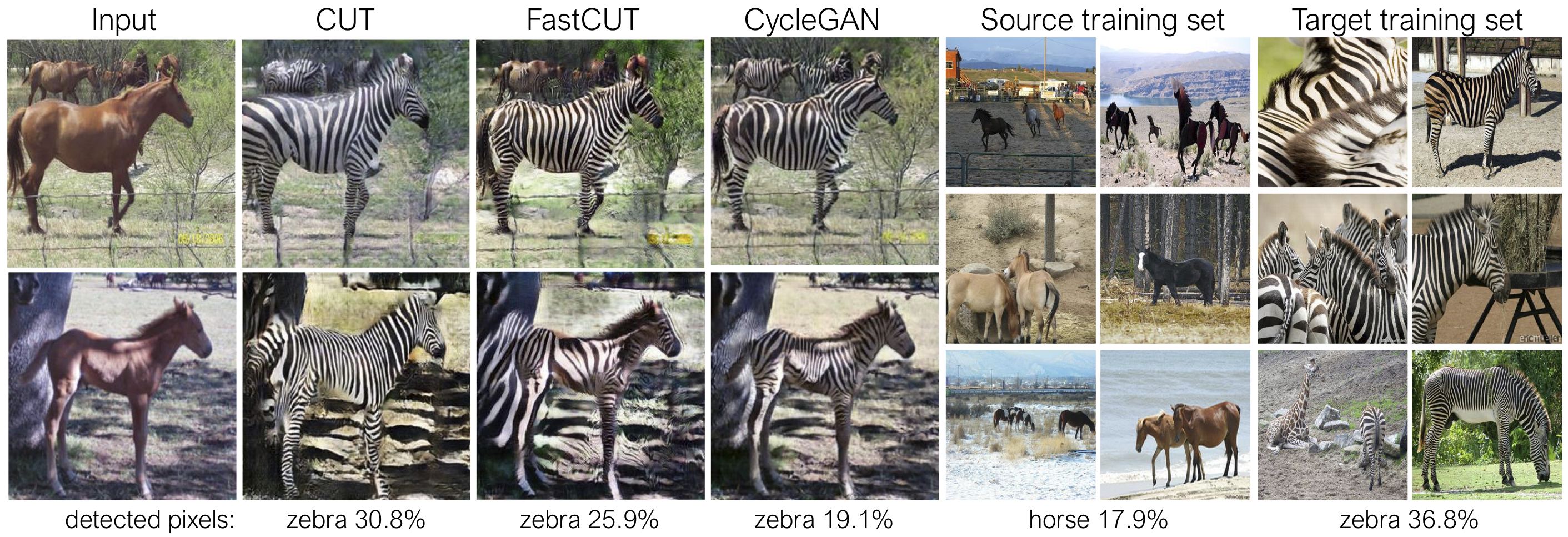
El corte está entrenado con la pérdida de preservación de identidad y con lambda_NCE=1 , mientras que FastCut está entrenado sin la pérdida de identidad pero con mayor lambda_NCE=10.0 . En comparación con Cyclegan, COT aprende a realizar una coincidencia de distribución más potente, mientras que FastCut está diseñado como un más ligero (la mitad de la memoria de la GPU, puede ajustarse a una imagen más grande) y más rápido (dos veces más rápido para entrenar) alternativa a Cyclegan. Consulte el documento para obtener más detalles.
En la figura anterior, medimos el porcentaje de píxeles que pertenecen a los cuerpos de caballo/cebra, utilizando un modelo de segmentación semántica previamente entrenada. Encontramos un desajuste de distribución entre los tamaños de caballos y las imágenes de cebras: las cebras generalmente parecen más grandes (36.8% frente a 17.9%). Nuestro corte de método completo tiene la flexibilidad de ampliar los caballos, como un medio para una mejor coincidencia de las estadísticas de entrenamiento que Cyclegan. Fastcut se comporta de manera más conservadora como Cyclegan.
Consulte experiments/grumpifycat_launcher.py que genera los argumentos de línea de comando anteriores. Los scripts de lanzadores son útiles para configurar argumentos de línea de comandos bastante complicados de capacitación y pruebas.
Usando el lanzador, el siguiente comando genera el comando de entrenamiento de Cut y Fastcut.
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTPara probar con el lanzador,
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT Los posibles comandos son ejecutados, run_test, lanzamiento, cierre, etc. Consulte experiments/__main__.py para todos los comandos. Eluncher es fácil y rápido de definir y usar. Por ejemplo, el lanzador GrumpifyCat se define en algunas líneas:
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]Para ejecutar los modelos previos a la aparición, ejecute lo siguiente.
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
NOTA: El modelo de petróleo de los paisajes urbanos fue entrenado y evaluado en una versión redimensionada y comprimida por JPEG del conjunto de datos de paisajes urbanos originales. Para realizar la evaluación, descargue este conjunto de validación y realice una evaluación.
Para entrenar a Sincut (traducción de imagen única, que se muestra en las figuras 9, 13 y 14 del papel), debe
--model como --model sincut , que invoca la configuración y los códigos en ./models/sincut_model.py , y./datasets/single_image_monet_etretat/ .Por ejemplo, para entrenar un modelo para el acantilado Etretat (primera imagen de la Figura 13), use el siguiente comando.
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretato utilizando el script de lanzador de experimentos,
python -m experiments singleimage run 0 Para la traducción de imagen única, adoptamos componentes arquitectónicos de red de StyleGan2, así como la pérdida de preservación de identidad de píxeles utilizada en DTN y Cyclegan. En particular, adoptamos el código de rosalidad, que existe en models/stylegan_networks.py .
El entrenamiento lleva varias horas. Para generar la imagen final usando el punto de control,
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretato simplemente
python -m experiments singleimage run_test 0Descargue los conjuntos de datos Cut/Cyclegan/Pix2pix. Por ejemplo,
bash datasets/download_cut_datasets.sh horse2zebra El conjunto de datos CAT2DOG se prepara a partir del conjunto de datos AFHQ. Visite https://github.com/clovaai/stargan-v2 y descargue el conjunto de datos AFHQ by bash download.sh afhq-dataset del repositorio de Github. Luego reorganice los directorios de la siguiente manera.
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog El conjunto de datos Cityscapes se puede descargar de https://cityscapes-dataset.com. Después de eso, use el script ./datasets/prepare_cityscapes_dataset.py para preparar el conjunto de datos.
El preprocesamiento de las imágenes de entrada, como el cambio de tamaño o el cultivo aleatorio, está controlado por la opción --preprocess , --load_size y --crop_size . El uso sigue el repositorio de Cyclegan/Pix2pix.
Por ejemplo, la configuración predeterminada --preprocess resize_and_crop --load_size 286 --crop_size 256 cambia de tamaño la imagen de entrada a 286x286 , y luego hace una cosecha aleatoria de tamaño 256x256 como una forma de realizar el aumento de datos. Hay otras opciones de preprocesamiento que se pueden especificar, y se especifican en base_dataset.py. A continuación se presentan algunas opciones de ejemplo.
--preprocess none : no realiza ningún preprocesamiento. Tenga en cuenta que el tamaño de la imagen todavía se escala para ser un múltiplo más cercano de 4, porque el generador convolucional no puede mantener el mismo tamaño de imagen de otra manera.--preprocess scale_width --load_size 768 : escala el ancho de la imagen para ser de tamaño 768.--preprocess scale_shortside_and_crop : escala la relación de aspecto de preservación de la imagen para que el lado corto sea load_size , y luego realiza el cultivo aleatorio del tamaño de la ventana crop_size . Se pueden agregar más opciones de preprocesamiento modificando get_transform() de base_dataset.py .
Si usa este código para su investigación, cite nuestro documento.
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
Si usa el modelo original Pix2Pix y Cyclegan incluido en este repositorio, cite los siguientes documentos
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
Agradecemos a Allan Jabri y Phillip Isola por su útil discusión y comentarios. Nuestro código se desarrolla en base a Pytorch-Cyclegan-and-Pix2pix. También agradecemos a Pytorch-Fid por FID Computation, DRN por Miou Computation y Stylegan2-Pytorch por la implementación de Pytorch de StyleGan2 utilizada en nuestra configuración de traducción de imagen única.


