contrastive unpaired translation
1.0.0

نحن نقدم تنفيذ Pytorch الخاص بنا لترجمة صورة إلى صورة غير محصنة استنادًا إلى التعلم المتناقض والتعلم العدواني. لا يتم استخدام الخسارة المصنوعة يدويًا والشبكة العكسية. بالمقارنة مع Cyclegan ، فإن تدريبنا النموذجي أسرع وأقل كثافة في الذاكرة. بالإضافة إلى ذلك ، يمكن توسيع طريقتنا إلى تدريب على الصور المفردة ، حيث يكون كل "مجال" مجرد صورة واحدة .
التعلم المتناقض لترجمة صورة إلى صورة غير متوفرة
تايسونج بارك ، أليكسي أ. إفروس ، ريتشارد تشانغ ، جون يان تشو
UC Berkeley و Adobe Research
في ECCV 2020

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020: إضافة ترجمة واحدة.
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTتثبيت Pytorch 1.1 وغيرها من التبعيات (على سبيل المثال ، Torchvision ، Visdom ، Dounting ، Gputil).
بالنسبة لمستخدمي PIP ، يرجى كتابة PIP Command pip install -r requirements.txt .
بالنسبة لمستخدمي الكوندنا ، يمكنك إنشاء بيئة جديدة من كوندا باستخدام conda env create -f environment.yml .
grumpifycat (الشكل 8 من الورقة. Russian Blue -> القطط الغاضبة) bash ./datasets/download_cut_dataset.sh grumpifycat يتم تنزيل مجموعة البيانات وإلغاء الضغط على ./datasets/grumpifycat/ .
لعرض نتائج التدريب ومؤامرات الخسارة ، قم بتشغيل python -m visdom.server وانقر فوق عنوان URL http: // localhost: 8097.
تدريب نموذج القطع:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTأو تدريب نموذج Fastcut
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT سيتم تخزين نقاط التفتيش على ./checkpoints/grumpycat_*/web .
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train سيتم حفظ نتائج الاختبار إلى ملف HTML هنا: ./results/grumpifycat/latest_train/index.html .
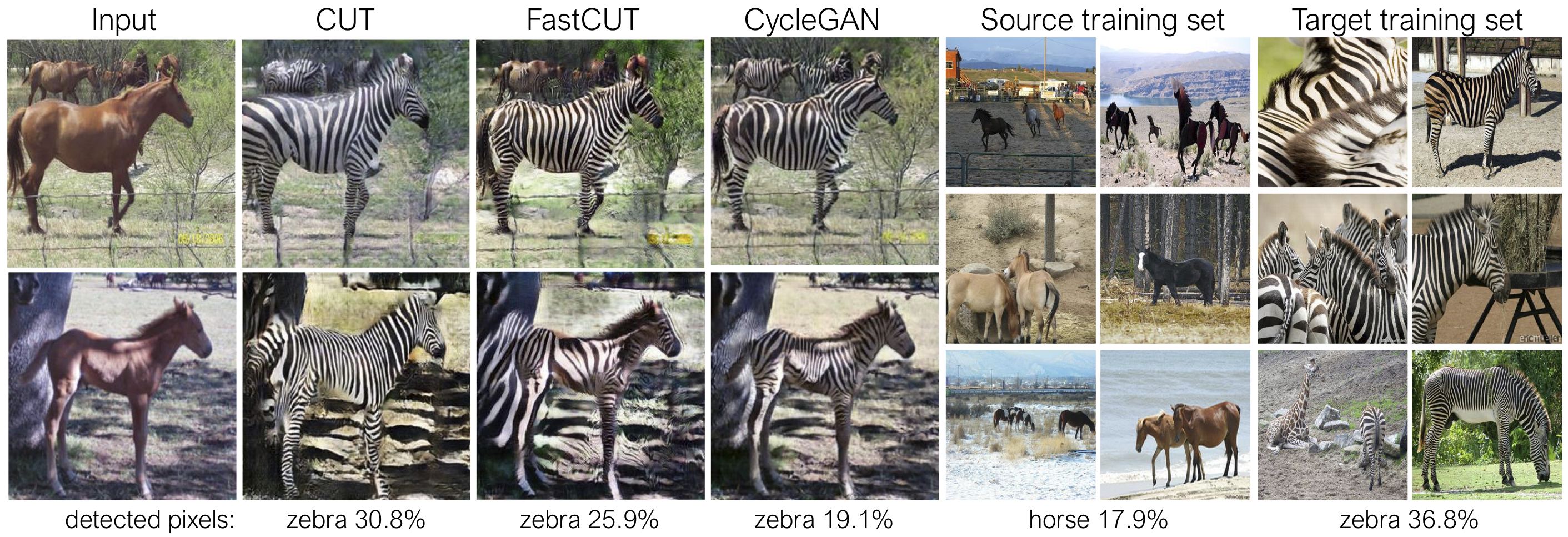
يتم تدريب القطع مع فقدان الحفاظ على الهوية ومع lambda_NCE=1 ، بينما يتم تدريب Fastcut دون فقدان الهوية ولكن مع lambda_NCE=10.0 . بالمقارنة مع Cyclegan ، يتعلم Cut أداء مطابقة توزيع أكثر قوة ، بينما تم تصميم FastCut كبديل أخف (نصف ذاكرة GPU ، يمكن أن يتناسب مع صورة أكبر) ، وبديل أسرع (أسرع مرتين للتدريب) لـ Cyclegan. يرجى الرجوع إلى الورقة لمزيد من التفاصيل.
في الشكل أعلاه ، نقوم بقياس النسبة المئوية للبكسلات التي تنتمي إلى أجسام الحصان/الحمار الوحشي ، وذلك باستخدام نموذج تجزئة دلالي مدرب مسبقًا. نجد عدم تطابق التوزيع بين أحجام الخيول وصور الحمار الوحوش - عادة ما يبدو الحمر الوحشية أكبر (36.8 ٪ مقابل 17.9 ٪). تتمتع Cut Cut Cut الكاملة بالمرونة لتكبير الخيول ، كوسيلة لمطابقة أفضل لإحصائيات التدريب من Cyclegan. يتصرف Fastcut بشكل أكثر تحفظًا مثل Cyclegan.
يرجى الاطلاع على experiments/grumpifycat_launcher.py التي تنشئ وسيطات سطر الأوامر أعلاه. تعتبر برامج النصوص المشغل مفيدة لتكوين وسيطات سطر الأوامر المعقدة إلى حد ما للتدريب والاختبار.
باستخدام القاذفة ، يقوم الأمر أدناه بإنشاء أمر التدريب الخاص بـ Cut و Fastcut.
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTلاختبار استخدام المشغل ،
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT يتم تشغيل الأوامر الممكنة ، Run_test ، الإطلاق ، إغلاق ، وهلم جرا. يرجى الاطلاع على experiments/__main__.py لجميع الأوامر. قاذفة سهلة وسريعة لتحديد واستخدام. على سبيل المثال ، يتم تعريف قاذفة GrumpifyCat في بضعة أسطر:
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]لتشغيل النماذج المسبقة ، قم بتشغيل ما يلي.
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
ملاحظة: تم تدريب نموذج City Cscapes PretRained وتقييمه على نسخة مصدقة ومضغوطة JPEG من مجموعة بيانات City Scapes الأصلية. لإجراء التقييم ، يرجى تنزيل مجموعة التحقق من الصحة هذه وإجراء التقييم.
لتدريب SINCUT (ترجمة صورة واحدة ، كما هو موضح في الشكل 9 و 13 و 14 من الورقة) ، تحتاج إلى ذلك
--model كـ --model sincut ، والذي يستدعي التكوين والرموز على ./models/sincut_model.py ، و./datasets/single_image_monet_etretat/ .على سبيل المثال ، لتدريب نموذج لـ Etretat Cliff (الصورة الأولى للشكل 13) ، يرجى استخدام الأمر التالي.
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatأو باستخدام البرنامج النصي لقاذفة التجربة ،
python -m experiments singleimage run 0 بالنسبة للترجمة ذات الصورة الواحدة ، نعتمد المكونات المعمارية للشبكة لـ Stylegan2 ، وكذلك فقدان الحفاظ على هوية البكسل المستخدمة في DTN و Cyclegan. على وجه الخصوص ، اعتمدنا مدونة الورد ، الموجودة في models/stylegan_networks.py .
يستغرق التدريب عدة ساعات. لإنشاء الصورة النهائية باستخدام نقطة التفتيش ،
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatأو ببساطة
python -m experiments singleimage run_test 0قم بتنزيل مجموعات بيانات CUT/CYCLEGAN/PIX2PIX. على سبيل المثال،
bash datasets/download_cut_datasets.sh horse2zebra يتم إعداد مجموعة بيانات CAT2DOG من مجموعة بيانات AFHQ. يرجى زيارة https://github.com/clovaai/stargan-v2 وتنزيل مجموعة بيانات AFHQ بواسطة bash download.sh afhq-dataset of github repo. ثم إعادة تنظيم الدلائل على النحو التالي.
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog يمكن تنزيل مجموعة بيانات CityScapes من https://cityscapes-dataset.com. بعد ذلك ، استخدم البرنامج النصي ./datasets/prepare_cityscapes_dataset.py لإعداد مجموعة البيانات.
يتم التحكم في المعالجة المسبقة لصور الإدخال ، مثل تغيير حجم المحاصيل أو المحاصيل العشوائية ، بواسطة الخيار --preprocess ، --load_size ، و --crop_size . يتبع الاستخدام ريبو Cyclegan/PIX2PIX.
على سبيل المثال ، فإن الإعداد الافتراضي --preprocess resize_and_crop --load_size 286 --crop_size 256 يقيم صورة الإدخال إلى 286x286 ، ثم يجعل محصولًا عشوائيًا بحجم 256x256 كوسيلة لأداء زيادة البيانات. هناك خيارات أخرى قبل المعالجة التي يمكن تحديدها ، ويتم تحديدها في base_dataset.py. فيما يلي بعض خيارات المثال.
--preprocess none : لا تؤدي أي معالجة مسبقة. لاحظ أن حجم الصورة لا يزال يتم قياسه ليكون أقرب مضاعف من 4 ، لأن المولد التلافيفي لا يمكنه الحفاظ على نفس حجم الصورة خلاف ذلك.--preprocess scale_width --load_size 768 : موسع عرض الصورة ليكون بحجم 768.--preprocess scale_shortside_and_crop : قم بتوسيع نطاق نسبة العرض إلى الحفاظ على الصورة بحيث يتم load_size الجانب القصير ، ثم يؤدي إلى زراعة crop_size لحجم النافذة. يمكن إضافة المزيد من خيارات المعالجة المسبقة عن طريق تعديل get_transform() من base_dataset.py .
إذا كنت تستخدم هذا الرمز لبحثك ، فيرجى الاستشهاد بالورقة.
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
إذا كنت تستخدم نموذج PIX2PIX الأصلي ونموذج Cyclegan في هذا الريبو ، فيرجى الاستشهاد بالأوراق التالية
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
نشكر ألان جابري وفيليب إيسولا على مناقشة وردود فعل مفيدة. تم تطوير الكود الخاص بنا على أساس Pytorch-cyclegan و pix2pix. نشكر أيضًا Pytorch-FID على حساب FID ، و DRN لحساب MIOU ، و Stylegan2-Pytorch لتطبيق Pytorch لـ StyleGan2 المستخدم في إعداد الترجمة أحادية الصورة.


