contrastive unpaired translation
1.0.0

Мы предоставляем нашу реализацию непарного перевода с изображением к изображению на основе патчззного контрастного обучения и состязательного обучения. Потеря ручной работы и обратная сеть не используется. По сравнению с Cyclegan наше модельное обучение более быстрее и менее интенсивно интенсивно. Кроме того, наш метод может быть распространен на однократное обучение изображения, где каждый «домен» представляет собой только одно изображение.
Контрастное обучение непарного перевода с изображением к изображению
Парк Тэснг, Алексей А. Эфрос, Ричард Чжан, Джун-Янь Чжу
UC Berkeley и Adobe Research
В ECCV 2020

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



12.09.2020: добавлено однократное перевод.
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTУстановите Pytorch 1.1 и другие зависимости (например, Tochvision, Visdom, доминирование, Gputil).
Для пользователей PIP, пожалуйста, введите команду pip install -r requirements.txt .
Для пользователей Conda вы можете создать новую среду Conda, используя conda env create -f environment.yml .
grumpifycat (рис. 8 статьи. Русский синий -> сварливые кошки) bash ./datasets/download_cut_dataset.sh grumpifycat Набор данных загружается и рассеян по адресу ./datasets/grumpifycat/ .
Чтобы просмотреть результаты обучения и графики потерь, запустите python -m visdom.server и нажмите на URL http: // localhost: 8097.
Обучить модель среза:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTИли тренировать модель Fastcut
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT Контрольные точки будут храниться по адресу ./checkpoints/grumpycat_*/web .
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train Результаты теста будут сохранены в HTML -файле здесь: ./results/grumpifycat/latest_train/index.html .
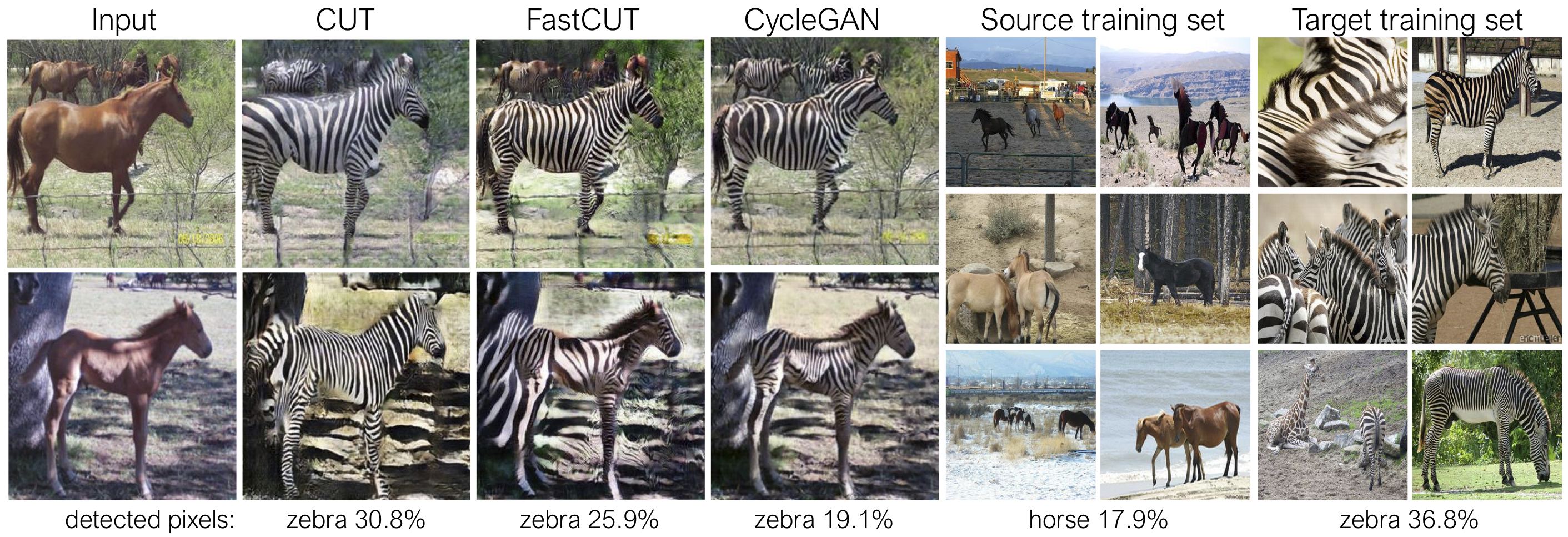
Выреж обучается потерей сохранения идентификации и с lambda_NCE=1 , в то время как FastCut обучается без потери идентичности, но с более высокой lambda_NCE=10.0 . По сравнению с Cyclegan, Cut учится выполнять более мощное сопоставление распределения, в то время как FastCut разработан как более легкая (половина памяти графического процессора, может соответствовать большему изображению) и более быстрее (дважды быстрее для обучения) альтернативы Cyclegan. Пожалуйста, обратитесь к газете для получения более подробной информации.
На приведенном выше рисунке мы измеряем процент пикселей, принадлежащих к телам лошади/зебры, используя предварительно обученную модель семантической сегментации. Мы находим несоответствие распределения между размерами лошадей и изображений зебр - зебры обычно кажутся больше (36,8% против 17,9%). Наш полный метод вырезает гибкость для увеличения лошадей, как средство лучшего сопоставления статистики обучения, чем Cyclegan. Fastcut ведет себя более консервативно, как Cyclegan.
Пожалуйста, смотрите experiments/grumpifycat_launcher.py , который генерирует приведенные выше аргументы командной строки. Сценарии запуска полезны для настройки довольно сложных аргументов командной строки в области обучения и тестирования.
Используя пусковую установку, команда ниже генерирует команду обучения Cut и Fastcut.
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTЧтобы проверить, используя пусковую установку,
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT Возможные команды выполняются, Run_test, запуск, закрыть и так далее. Пожалуйста, смотрите experiments/__main__.py для всех команд. Пусковая установка проста и быстро определить и использовать. Например, пусковая установка GrumpifyCat определяется в нескольких строках:
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]Чтобы запустить предварительные модели, запустите следующее.
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
ПРИМЕЧАНИЕ. Предварительная модель CityScapes была обучена и оценена по измененной и JPEG-сжатой версии оригинального набора данных CityScapes. Чтобы выполнить оценку, пожалуйста, загрузите этот набор проверки и выполните оценку.
Чтобы обучить Синкут (перевод с одним изображением, показанный на рис. 9, 13 и 14 статьи), вам нужно
--model как --model sincut , который вызывает конфигурацию и коды по адресу ./models/sincut_model.py , и./datasets/single_image_monet_etretat/ .Например, для обучения модели для Etretat Cliff (первое изображение рисунка 13), пожалуйста, используйте следующую команду.
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatили с помощью скрипта запуска эксперимента,
python -m experiments singleimage run 0 Для перевода с одним изображением мы принимаем сетевые архитектурные компоненты Stylegan2, а также потерю сохранения пикселей, используемые в DTN и Cyclegan. В частности, мы приняли Кодекс измены, который существует на models/stylegan_networks.py .
Обучение занимает несколько часов. Чтобы сгенерировать конечное изображение, используя контрольную точку,
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatили просто
python -m experiments singleimage run_test 0Скачать наборы данных COLT/CYCLAN/PIX2PIX. Например,
bash datasets/download_cut_datasets.sh horse2zebra Набор данных CAT2DOG подготовлен из набора данных AFHQ. Пожалуйста, посетите https://github.com/clovaai/stargan-v2 и загрузите набор данных AFHQ Bash bash download.sh afhq-dataset of the Github Repo. Затем реорганизуйте каталоги следующим образом.
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog Набор данных CityScapes можно загрузить с https://cityscapes-dataset.com. После этого используйте скрипт ./datasets/prepare_cityscapes_dataset.py чтобы подготовить набор данных.
Предварительная обработка входных изображений, таких как изменение размера или случайное обрезку, контролируется опцией --preprocess , --load_size и --crop_size . Использование следует за репозитором Cyclegan/Pix2pix.
Например, настройка по умолчанию --preprocess resize_and_crop --load_size 286 --crop_size 256 Изменения входного изображения до 286x286 , а затем производит случайный культуру размера 256x256 как способ для увеличения данных. Существуют другие параметры предварительной обработки, которые могут быть указаны, и они указаны в base_dataset.py. Ниже приведены некоторые примеры параметров.
--preprocess none : не выполняет никакой предварительной обработки. Обратите внимание, что размер изображения по -прежнему масштабируется, чтобы быть самым близким из 4, потому что в противном случае сверточный генератор не может поддерживать один и тот же размер изображения.--preprocess scale_width --load_size 768 : масштабирует ширину изображения размером 768.--preprocess scale_shortside_and_crop : масштабирует соотношение сторон, сохраняющего изображение, так что короткая сторона была load_size , а затем выполняет случайную обрезку размера окна crop_size . Больше параметров предварительной обработки можно добавить путем изменения get_transform() base_dataset.py .
Если вы используете этот код для своего исследования, пожалуйста, укажите нашу статью.
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
Если вы используете оригинальную модель Pix2pix и Cyclegan, включенную в эту репо, указать следующие документы
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
Мы благодарим Аллана Джабри и Филиппа Изола за полезное обсуждение и отзывы. Наш код разработан на основе Pytorch-Cyclegan-and-Pix2pix. Мы также благодарим Pytorch-Fid за вычисление FID, DRN для вычислений MIO и Stylegan2-Pytorch за реализацию Pytorch of Stylegan2, используемой в нашей настройке перевода с одним изображением.


