contrastive unpaired translation
1.0.0

Nous fournissons notre mise en œuvre pytorch de la traduction d'image à image non appariée basée sur l'apprentissage contrastif patchwis et l'apprentissage adversaire. Aucune perte fabriquée à la main et réseau inverse n'est utilisé. Par rapport à Cyclegan, notre entraînement de modèle est plus rapide et moins à forte intensité de mémoire. De plus, notre méthode peut être étendue à la formation d'image unique, où chaque «domaine» n'est qu'une seule image.
Apprentissage contrastif pour la traduction d'image à image non appariée
Taesung Park, Alexei A. Efros, Richard Zhang, Jun-Yan Zhu
UC Berkeley et Adobe Research
Dans ECCV 2020

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020: Ajout de traduction à image unique.
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTInstallez Pytorch 1.1 et d'autres dépendances (par exemple, TorchVision, Visdom, dominer, gputil).
Pour les utilisateurs de PIP, veuillez saisir la commande pip install -r requirements.txt .
Pour les utilisateurs de conda, vous pouvez créer un nouvel environnement conda à l'aide conda env create -f environment.yml .
grumpifycat (Fig 8 du papier. Russian Blue -> Grumpy Cats) bash ./datasets/download_cut_dataset.sh grumpifycat L'ensemble de données est téléchargé et décompressé sur ./datasets/grumpifycat/ .
Pour voir les résultats de formation et les tracés de perte, exécutez python -m visdom.server et cliquez sur l'URL http: // localhost: 8097.
Former le modèle de coupe:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTOu entraîner le modèle Fastcut
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT Les points de contrôle seront stockés sur ./checkpoints/grumpycat_*/web .
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train Les résultats des tests seront enregistrés dans un fichier HTML ici: ./results/grumpifycat/latest_train/index.html .
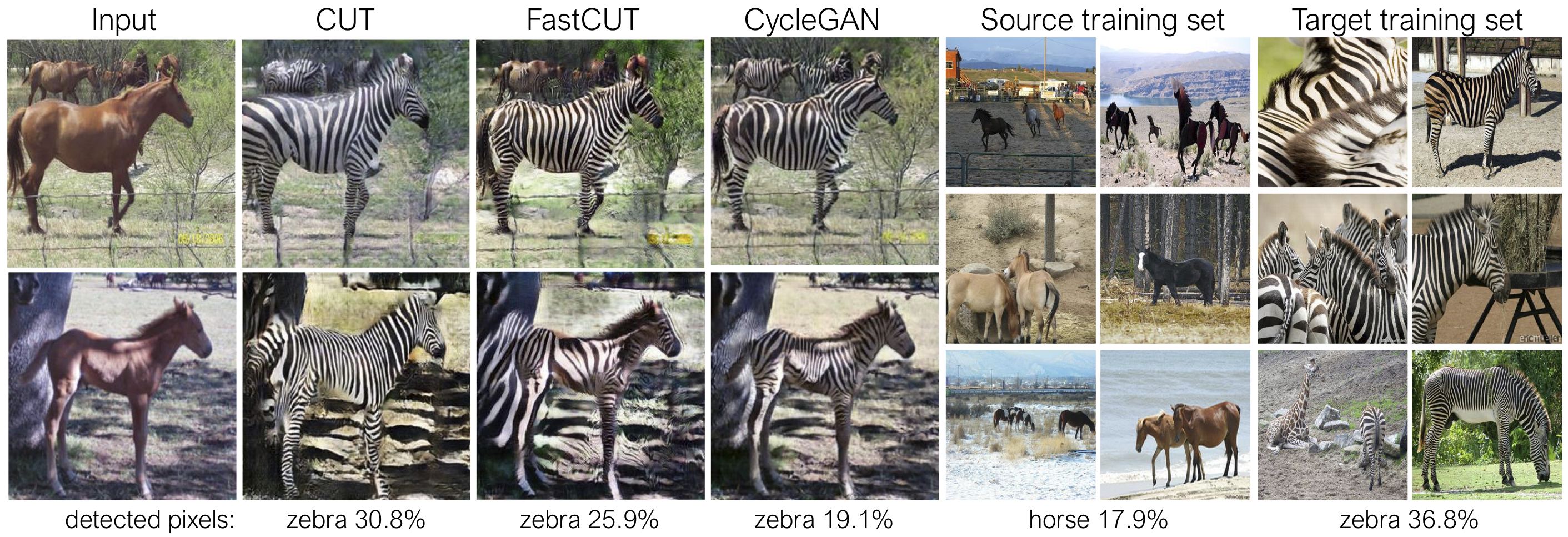
La coupe est formée avec la perte de préservation de l'identité et avec lambda_NCE=1 , tandis que Fastcut est formé sans la perte d'identité mais avec lambda_NCE=10.0 plus élevé. Par rapport à Cyclegan, Cut apprend à effectuer une correspondance de distribution plus puissante, tandis que Fastcut est conçu comme une alternative plus légère (moitié de la mémoire GPU, peut s'adapter à une image plus grande), et plus rapide (deux fois plus rapide pour former) une alternative à Cyclegan. Veuillez vous référer au journal pour plus de détails.
Dans le chiffre ci-dessus, nous mesurons le pourcentage de pixels appartenant aux corps de cheval / zèbre, en utilisant un modèle de segmentation sémantique pré-formé. Nous trouvons un décalage de distribution entre les tailles de chevaux et les images de zèbres - les zèbres semblent généralement plus grandes (36,8% contre 17,9%). Notre coupe de méthode complète a la flexibilité d'élargir les chevaux, comme moyen de mieux faire correspondre les statistiques d'entraînement que Cyclegan. Fastcut se comporte plus conservateur comme Cyclegan.
Veuillez consulter experiments/grumpifycat_launcher.py qui génère les arguments de ligne de commande ci-dessus. Les scripts de lanceur sont utiles pour configurer des arguments de ligne de commande assez compliqués de formation et de tests.
En utilisant le lanceur, la commande ci-dessous génère la commande d'entraînement de Cut et Fastcut.
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTPour tester à l'aide du lanceur,
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT Les commandes possibles sont exécutées, run_test, lancement, fermer, etc. Veuillez consulter experiments/__main__.py pour toutes les commandes. Le lanceur est facile et rapide à définir et à utiliser. Par exemple, le lanceur GrumpifyCat est défini en quelques lignes:
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]Pour exécuter les modèles pré-entraînés, exécutez ce qui suit.
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
Remarque: Le modèle pré-entraîné des paysages urbains a été formé et évalué sur une version redimensionnée et compressée par JPEG de l'ensemble de données Cityscapes d'origine. Pour effectuer une évaluation, veuillez télécharger cet ensemble de validation et effectuer une évaluation.
Pour entraîner Sincut (traduction à image unique, montrée sur les figures 9, 13 et 14 du papier), vous devez
--model en --model sincut , qui invoque la configuration et les codes sur ./models/sincut_model.py , et./datasets/single_image_monet_etretat/ .Par exemple, pour former un modèle pour la falaise de l'Etdreat (première image de la figure 13), veuillez utiliser la commande suivante.
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatou en utilisant le script de lanceur d'expérience,
python -m experiments singleimage run 0 Pour la traduction d'image unique, nous adoptons des composants architecturaux de réseau de Stylegan2, ainsi que la perte de préservation de l'identité des pixels utilisée dans DTN et Cyclegan. En particulier, nous avons adopté le code de rosinalité, qui existe sur models/stylegan_networks.py .
La formation prend plusieurs heures. Pour générer l'image finale en utilisant le point de contrôle,
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatou tout simplement
python -m experiments singleimage run_test 0Téléchargez les ensembles de données Cut / Cyclegan / Pix2Pix. Par exemple,
bash datasets/download_cut_datasets.sh horse2zebra L'ensemble de données CAT2DOG est préparé à partir de l'ensemble de données AFHQ. Veuillez visiter https://github.com/clovaai/stargan-v2 et télécharger l'ensemble de données AFHQ par bash download.sh afhq-dataset du repos github. Ensuite réorganiser les répertoires comme suit.
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog L'ensemble de données Cityscapes peut être téléchargé à partir de https://cityscapes-dataset.com. Après cela, utilisez le script ./datasets/prepare_cityscapes_dataset.py pour préparer l'ensemble de données.
Le prétraitement des images d'entrée, tel que le redimensionnement ou la culture aléatoire, est contrôlé par l'option --preprocess , --load_size et --crop_size . L'utilisation suit le repo Cyclegan / Pix2Pix.
Par exemple, le paramètre par défaut --preprocess resize_and_crop --load_size 286 --crop_size 256 redimensionne l'image d'entrée à 286x286 , puis fait une récolte aléatoire de taille 256x256 comme moyen d'effectuer l'augmentation des données. Il existe d'autres options de prétraitement qui peuvent être spécifiées, et elles sont spécifiées dans base_dataset.py. Vous trouverez ci-dessous quelques exemples d'options.
--preprocess none : n'effectue aucun prétraitement. Notez que la taille de l'image est toujours mise à l'échelle pour être un multiple le plus proche de 4, car le générateur convolutionnel ne peut pas maintenir la même taille d'image autrement.--preprocess scale_width --load_size 768 : Échelle la largeur de l'image à la taille 768.--preprocess scale_shortside_and_crop : Échelle le rapport d'aspect de préservation de l'image de sorte que le côté court est load_size , puis effectue un recadrage aléatoire de la taille de la fenêtre crop_size . Plus d'options de prétraitement peuvent être ajoutées en modifiant get_transform() de base_dataset.py .
Si vous utilisez ce code pour vos recherches, veuillez citer notre article.
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
Si vous utilisez le modèle PIX2PIX et Cyclegan d'origine inclus dans ce dépôt, veuillez citer les articles suivants
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
Nous remercions Allan Jabri et Phillip Isola pour les discussions et les commentaires utiles. Notre code est développé sur la base de Pytorch-Cyclegan et-Pix2Pix. Nous remercions également Pytorch-Fid pour le calcul du FID, DRN pour MIOU Calcul et Stylegan2-Pytorch pour la mise en œuvre de Pytorch de Stylegan2 utilisé dans notre paramètre de traduction à image unique.


