contrastive unpaired translation
1.0.0

Fornecemos nossa implementação de Pytorch de tradução não pareada de imagem para imagem com base no aprendizado contrastivo do Patchwise e no aprendizado adversário. Nenhuma perda artesanal e rede inversa são usadas. Comparado ao Cyclegan, nosso treinamento modelo é mais rápido e menos intensivo em memória. Além disso, nosso método pode ser estendido ao treinamento de imagem única, onde cada "domínio" é apenas uma única imagem.
Aprendizagem contrastante para tradução para imagem não pareada
Taesung Park, Alexei A. Efros, Richard Zhang, Jun-Yan Zhu
UC Berkeley e Adobe Research
No ECCV 2020

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020: Tradução adicionada de imagem única.
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTInstale o Pytorch 1.1 e outras dependências (por exemplo, Torchvision, Visdom, Dominate, Gputil).
Para usuários do PIP, digite o comando pip install -r requirements.txt .
Para os usuários do CONDA, você pode criar um novo ambiente do CONDA usando conda env create -f environment.yml .
grumpifycat (Fig. 8 do artigo. Azul russo -> Grumpy Cats) bash ./datasets/download_cut_dataset.sh grumpifycat O conjunto de dados é baixado e descompactado em ./datasets/grumpifycat/ .
Para visualizar os resultados do treinamento e as parcelas de perda, execute python -m visdom.server e clique no URL http: // localhost: 8097.
Treine o modelo de corte:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTOu treinar o modelo FastCut
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT Os pontos de verificação serão armazenados em ./checkpoints/grumpycat_*/web .
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train Os resultados do teste serão salvos em um arquivo html aqui: ./results/grumpifycat/latest_train/index.html .
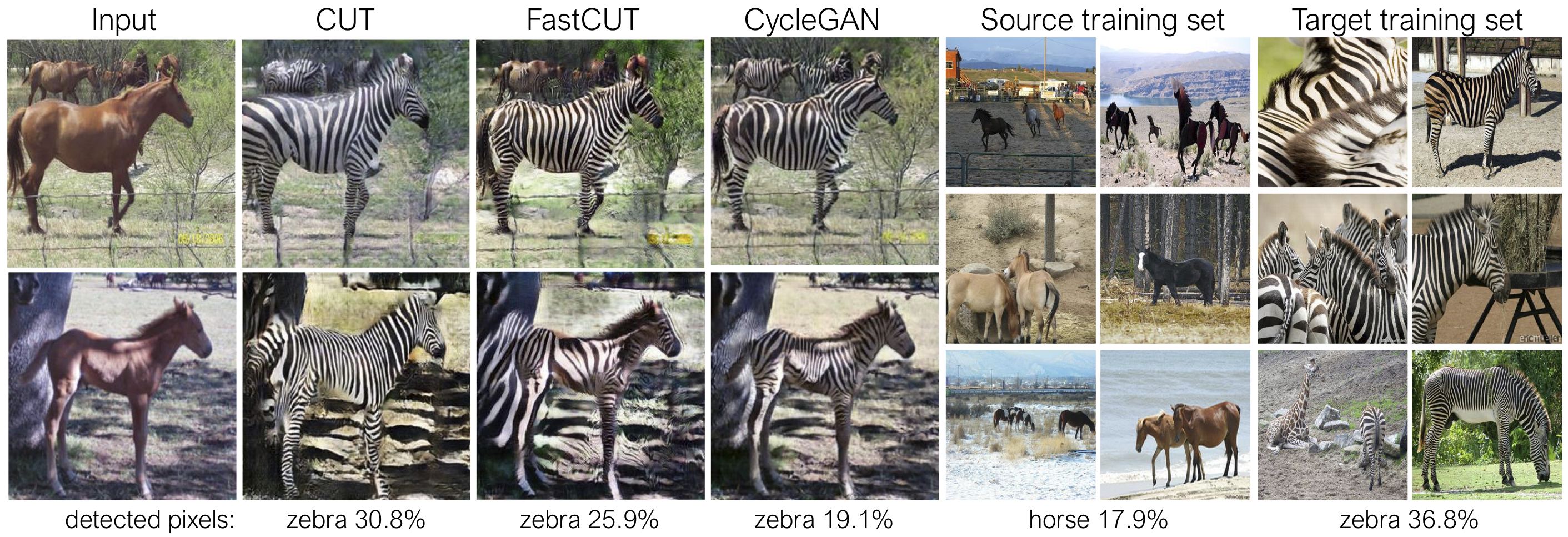
O corte é treinado com a perda de preservação da identidade e com lambda_NCE=1 , enquanto o FastCut é treinado sem a perda de identidade, mas com lambda_NCE=10.0 . Comparado ao Cyclegan, o Cut aprende a realizar uma distribuição mais poderosa correspondência, enquanto o FastCut é projetado como uma alternativa mais leve (metade da GPU, pode se encaixar em uma imagem maior) e mais rápida (duas vezes mais rápida para treinar) alternativa ao Cyclegan. Consulte o artigo para obter mais detalhes.
Na figura acima, medimos a porcentagem de pixels pertencentes aos corpos de cavalo/zebra, usando um modelo de segmentação semântica pré-treinado. Encontramos uma incompatibilidade de distribuição entre tamanhos de cavalos e imagens de zebras - as zebras geralmente parecem maiores (36,8% vs. 17,9%). Nosso corte completo de método tem a flexibilidade de ampliar os cavalos, como um meio de correspondência melhor das estatísticas de treinamento do que o Cyclegan. O FastCut se comporta de maneira mais conservadora como o Cyclegan.
Consulte experiments/grumpifycat_launcher.py que gera os argumentos da linha de comando acima. Os scripts do lançador são úteis para configurar argumentos de linha de comando bastante complicados de treinamento e teste.
Usando o lançador, o comando abaixo gera o comando de treinamento de corte e fastcut.
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTPara testar usando o lançador,
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT Os comandos possíveis são executados, run_test, lançar, fechar e assim por diante. Consulte experiments/__main__.py para todos os comandos. O Launcher é fácil e rápido de definir e usar. Por exemplo, o lançador GrumpifyCat é definido em algumas linhas:
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]Para executar os modelos pré -treinados, execute o seguinte.
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
NOTA: O modelo de paisagens da cidade foi treinado e avaliado em uma versão redimensionada e compactada JPEG do conjunto de dados originais da Cityscapes. Para executar a avaliação, faça o download deste conjunto de validação e execute a avaliação.
Para treinar Sincut (tradução de imagem única, mostrada nas Fig 9, 13 e 14 do artigo), você precisa
--model como --model sincut , que invoca a configuração e os códigos em ./models/sincut_model.py e./datasets/single_image_monet_etretat/ .Por exemplo, para treinar um modelo para o penhasco Etretat (primeira imagem da Figura 13), use o seguinte comando.
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatou usando o script de lançador do Experiment,
python -m experiments singleimage run 0 Para tradução de imagem única, adotamos componentes arquitetônicos de rede do Stylegan2, bem como a perda de preservação da identidade do pixel usada no DTN e Cyclegan. Em particular, adotamos o código de rosinalidade, que existe no models/stylegan_networks.py .
O treinamento leva várias horas. Para gerar a imagem final usando o ponto de verificação,
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatou simplesmente
python -m experiments singleimage run_test 0Baixar conjuntos de dados Cut/Cyclegan/Pix2pix. Por exemplo,
bash datasets/download_cut_datasets.sh horse2zebra O conjunto de dados CAT2DOG é preparado no conjunto de dados AFHQ. Visite https://github.com/clovaai/stargan-v2 e faça o download do conjunto de dados AFHQ por bash download.sh afhq-dataset do Repo Github. Em seguida, reorganize os diretórios da seguinte maneira.
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog O conjunto de dados da CityScapes pode ser baixado em https://cityscapes-dataset.com. Depois disso, use o script ./datasets/prepare_cityscapes_dataset.py para preparar o conjunto de dados.
O pré -processamento das imagens de entrada, como redimensionamento ou corte aleatório, é controlado pela opção --preprocess , --load_size e --crop_size . O uso segue o repo Cyclegan/Pix2pix.
Por exemplo, a configuração padrão --preprocess resize_and_crop --load_size 286 --crop_size 256 redimensiona a imagem de entrada para 286x286 e, em seguida, faz uma colheita aleatória do tamanho 256x256 como uma maneira de executar o aumento de dados. Existem outras opções de pré -processamento que podem ser especificadas e são especificadas em base_dataset.py. Abaixo estão algumas opções de exemplo.
--preprocess none : não executa nenhum pré-processamento. Observe que o tamanho da imagem ainda está escalado para ser um múltiplo mais próximo de 4, porque o gerador convolucional não pode manter o mesmo tamanho de imagem.--preprocess scale_width --load_size 768 : Escala a largura da imagem para ser do tamanho 768.--preprocess scale_shortside_and_crop : Escala a proporção de preservação da imagem para que o lado curto seja load_size e, em seguida, execute o corte aleatório do tamanho da janela crop_size . Mais opções de pré -processamento podem ser adicionadas modificando get_transform() de base_dataset.py .
Se você usar este código para sua pesquisa, cite nosso artigo.
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
Se você usar o modelo PIX2PIX e Cyclegan original incluído neste repositório, cite os seguintes trabalhos
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
Agradecemos a Allan Jabri e Phillip Isola pela discussão e feedback úteis. Nosso código é desenvolvido com base no pytorch-cyclegan e pix2pix. Agradecemos também a Pytorch-FID pela computação FID, DRN pela computação MIOU e Stylegan2-Pytorch pela implementação de Pytorch de Stylegan2 usada em nossa configuração de tradução de imagem única.


