contrastive unpaired translation
1.0.0

우리는 패치 와이 대비 학습 및 적대 학습을 기반으로 한 짝을 이루지 않은 이미지-이미지 번역의 Pytorch 구현을 제공합니다. 손으로 만들어진 손실과 역 네트워크가 사용되지 않습니다. Cyclegan과 비교할 때 모델 교육은 더 빠르고 메모리 집약적입니다. 또한, 우리의 방법은 단일 이미지 훈련으로 확장 될 수 있으며, 여기서 각 "도메인"은 단일 이미지 일뿐입니다.
짝을 이루지 않은 이미지-이미지 번역에 대한 대조적 인 학습
Taesung Park, Alexei A. Efros, Richard Zhang, Jun-yan Zhu
UC Berkeley 및 Adobe Research
ECCV 2020에서

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020 : 단일 이미지 번역이 추가되었습니다.
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTPytorch 1.1 및 기타 종속성 (예 : Torchvision, Visdom, Domination, Gputil)을 설치하십시오.
PIP 사용자의 경우 명령 pip install -r requirements.txt 입력하십시오.
Conda 사용자의 경우 conda env create -f environment.yml 사용하여 새로운 Conda 환경을 만들 수 있습니다.
grumpifycat 데이터 세트를 다운로드하십시오 (논문의 그림 8. Russian Blue-> Grumpy Cats) bash ./datasets/download_cut_dataset.sh grumpifycat 데이터 세트는 ./datasets/grumpifycat/ 에서 다운로드 및 압축을 풀었다.
교육 결과 및 손실 플롯을 보려면 python -m visdom.server 실행하고 URL http : // localhost : 8097을 클릭하십시오.
컷 모델 훈련 :
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT또는 Fastcut 모델을 훈련시킵니다
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT 체크 포인트는 ./checkpoints/grumpycat_*/web 에 저장됩니다.
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train 테스트 결과는 여기에서 html 파일에 저장됩니다 : ./results/grumpifycat/latest_train/index.html .
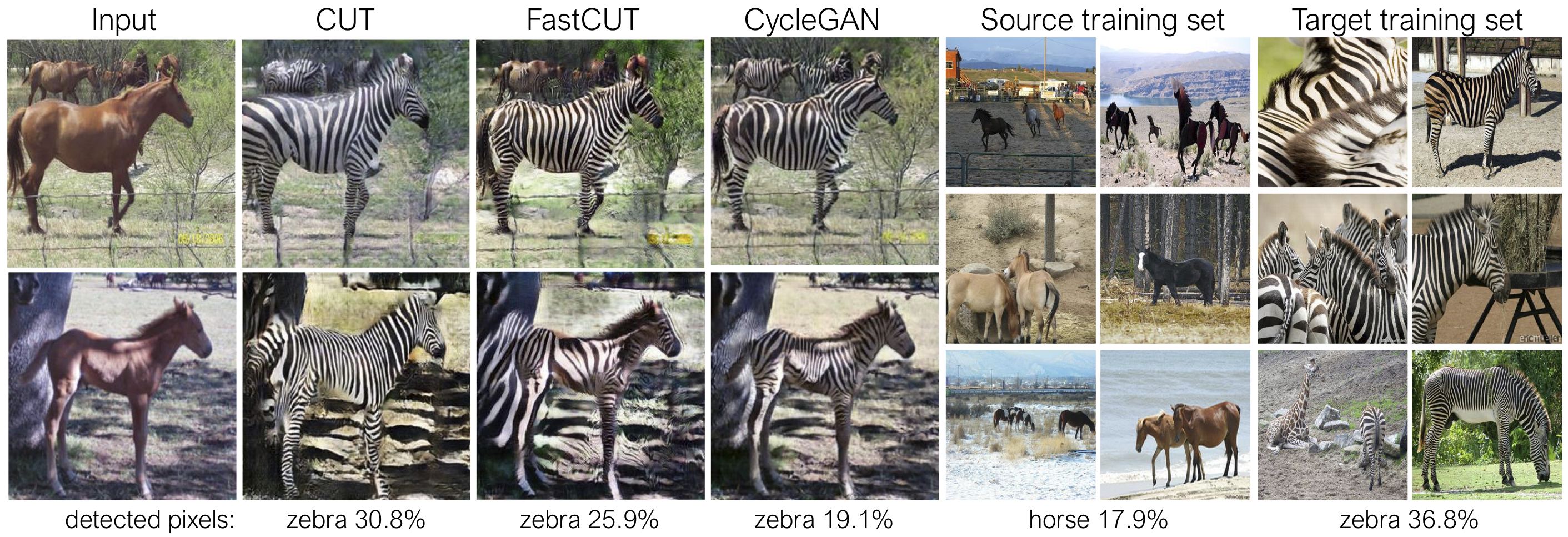
컷은 신원 보존 손실과 lambda_NCE=1 으로 훈련 된 반면, FastCut은 신원 손실 없이도 더 높은 lambda_NCE=10.0 으로 훈련됩니다. Clightgan과 비교할 때 Cut은보다 강력한 분배 일치를 수행하는 법을 배웁니다. FastCut은 더 가벼운 (GPU 메모리의 절반, 더 큰 이미지에 맞는)로 설계되었으며 Cyclegan에 대한 더 빠르고 (2 배 더 빠르게 훈련하는) 대안으로 설계되었습니다. 자세한 내용은 논문을 참조하십시오.
위의 그림에서, 우리는 미리 훈련 된 시맨틱 세분화 모델을 사용하여 말/얼룩말 바디에 속하는 픽셀의 백분율을 측정합니다. 우리는 말과 얼룩말 이미지 사이의 분포 불일치를 발견합니다. 얼룩말은 일반적으로 더 크게 나타납니다 (36.8% 대 17.9%). 우리의 전체 방법 컷은 Cyclegan보다 훈련 통계와 더 잘 일치하는 수단으로 말을 확대 할 수있는 유연성을 가지고 있습니다. Fastcut은 Cyclegan처럼 보수적으로 행동합니다.
위의 명령 줄 인수를 생성하는 experiments/grumpifycat_launcher.py 참조하십시오. 런처 스크립트는 교육 및 테스트에 대한 복잡한 명령 줄 인수를 구성하는 데 유용합니다.
런처를 사용하여 아래 명령은 Cut and Fastcut의 교육 명령을 생성합니다.
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUT런처를 사용하여 테스트하려면
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT 가능한 명령이 실행, run_test, 런치, 닫기 등을 실행합니다. 모든 명령에 대해서는 experiments/__main__.py 참조하십시오. 발사기는 쉽고 신속하고 정의하고 사용합니다. 예를 들어 GrumpifyCat 런처는 몇 줄로 정의됩니다.
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]사전 모델을 실행하려면 다음을 실행하십시오.
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
참고 : CityScapes 사전 관리 모델은 원래 CityScapes 데이터 세트의 크기가 크고 JPEG 압축 버전에서 교육 및 평가되었습니다. 평가를 수행하려면이 검증 세트를 다운로드하고 평가를 수행하십시오.
Sincut (용지의 그림 9, 13 및 14에 표시된 단일 이미지 변환)을 훈련하려면
--model 옵션을 --model sincut 로 설정하여 ./models/sincut_model.py 에서 구성 및 코드를 호출하고, 그리고./datasets/single_image_monet_etretat/ 에 포함 된 예제 데이터 세트와 같은 각 도메인에서 하나의 이미지의 데이터 세트 디렉토리를 지정하십시오.예를 들어, Etretat Cliff (그림 13의 첫 번째 이미지)에 대한 모델을 훈련 시키려면 다음 명령을 사용하십시오.
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretat또는 실험 런처 스크립트를 사용하여
python -m experiments singleimage run 0 단일 이미지 변환의 경우, 우리는 Stylegan2의 네트워크 아키텍처 구성 요소와 DTN 및 Cyclgan에 사용되는 픽셀 아이덴티티 보존 손실을 채택합니다. 특히, 우리는 models/stylegan_networks.py 에 존재하는 Rosinality 코드를 채택했습니다.
훈련에는 몇 시간이 걸립니다. 체크 포인트를 사용하여 최종 이미지를 생성하려면
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretat또는 간단히
python -m experiments singleimage run_test 0Cut/Cyclegan/Pix2Pix 데이터 세트를 다운로드하십시오. 예를 들어,
bash datasets/download_cut_datasets.sh horse2zebra CAT2DOG 데이터 세트는 AFHQ 데이터 세트에서 준비됩니다. https://github.com/clovaai/stargan-v2를 방문하여 Github Repo의 bash download.sh afhq-dataset 에서 Afhq 데이터 세트를 다운로드하십시오. 그런 다음 다음과 같이 디렉토리를 재구성하십시오.
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog CityScapes 데이터 세트는 https://cityscapes-dataset.com에서 다운로드 할 수 있습니다. 그런 다음 스크립트 ./datasets/prepare_cityscapes_dataset.py 를 사용하여 데이터 세트를 준비하십시오.
크기 조정 또는 임의의 자르기와 같은 입력 이미지의 전처리는 옵션 --preprocess , --load_size 및 --crop_size 옵션으로 제어됩니다. 사용법은 Cyclegan/Pix2pix Repo를 따릅니다.
예를 들어, 기본 설정 --preprocess resize_and_crop --load_size 286 --crop_size 256 입력 이미지를 286x286 으로 크기로 바꾸고 데이터 증강을 수행하는 방법으로 256x256 크기의 임의의 작물을 만듭니다. 지정할 수있는 다른 전처리 옵션이 있으며 base_dataset.py에 지정됩니다. 다음은 몇 가지 예 옵션입니다.
--preprocess none : 전처리를 수행하지 않습니다. 컨볼 루션 생성기는 동일한 이미지 크기를 달리 유지할 수 없기 때문에 이미지 크기는 여전히 4의 가장 가까운 배수로 스케일링됩니다.--preprocess scale_width --load_size 768 : 이미지의 너비를 크기 768로 스케일링합니다.--preprocess scale_shortside_and_crop : 측면이 load_size 가되도록 이미지 보존 종횡비를 조정 한 다음 Window Size crop_size 의 임의의 자르기를 수행합니다. base_dataset.py 의 get_transform() 수정하여 더 많은 전처리 옵션을 추가 할 수 있습니다.
이 코드를 연구에 사용하는 경우 논문을 인용하십시오.
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
이 저장소에 포함 된 원본 Pix2Pix 및 CycleGan 모델을 사용하는 경우 다음 논문을 인용하십시오.
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
유용한 토론과 피드백에 대해 Allan Jabri와 Phillip Isola에게 감사드립니다. 우리의 코드는 Pytorch-Cyclegan 및 Pix2Pix를 기반으로 개발되었습니다. 또한 FID 계산에 대한 Pytorch-Fid, MIOU 계산 용 DRN 및 단일 이미지 번역 설정에 사용되는 StyleGan2의 Pytorch 구현을위한 StyleGan2-Pytorch에게 감사드립니다.


