contrastive unpaired translation
1.0.0

Wir bieten unsere Pytorch-Implementierung von ungepaarten Bild-zu-Image-Übersetzungen auf der Grundlage von Patchwise-kontrastivem Lernen und kontroversen Lernen. Es wird kein handgefertigter Verlust und ein inverses Netzwerk verwendet. Im Vergleich zu Cyclegan ist unser Modelltraining schneller und weniger speicherintensiv. Darüber hinaus kann unsere Methode auf ein einzelnes Bildtraining erweitert werden, wobei jede „Domäne“ nur ein einzelnes Bild ist.
Kontrastives Lernen für ungepaarte Bild-zu-Image-Übersetzung
Taesung Park, Alexei A. Efros, Richard Zhang, Jun-Yan Zhu
UC Berkeley und Adobe Research
In ECCV 2020

import torch
cross_entropy_loss = torch . nn . CrossEntropyLoss ()
# Input: f_q (BxCxS) and sampled features from H(G_enc(x))
# Input: f_k (BxCxS) are sampled features from H(G_enc(G(x))
# Input: tau is the temperature used in PatchNCE loss.
# Output: PatchNCE loss
def PatchNCELoss ( f_q , f_k , tau = 0.07 ):
# batch size, channel size, and number of sample locations
B , C , S = f_q . shape
# calculate v * v+: BxSx1
l_pos = ( f_k * f_q ). sum ( dim = 1 )[:, :, None ]
# calculate v * v-: BxSxS
l_neg = torch . bmm ( f_q . transpose ( 1 , 2 ), f_k )
# The diagonal entries are not negatives. Remove them.
identity_matrix = torch . eye ( S )[ None , :, :]
l_neg . masked_fill_ ( identity_matrix , - float ( 'inf' ))
# calculate logits: (B)x(S)x(S+1)
logits = torch . cat (( l_pos , l_neg ), dim = 2 ) / tau
# return PatchNCE loss
predictions = logits . flatten ( 0 , 1 )
targets = torch . zeros ( B * S , dtype = torch . long )
return cross_entropy_loss ( predictions , targets )



9/12/2020: Hinzufügen von Single-Image-Übersetzungen.
git clone https://github.com/taesungp/contrastive-unpaired-translation CUT
cd CUTInstallieren Sie Pytorch 1.1 und andere Abhängigkeiten (z. B. Torchvision, Visom, dominieren, gputil).
Für PIP -Benutzer geben Sie bitte die Befehls pip install -r requirements.txt ein.
Für Conda -Benutzer können Sie eine neue Conda -Umgebung mit conda env create -f environment.yml erstellen.
grumpifycat -Datensatz herunter (Abb. 8 des Papiers. Russischblau -> mürrische Katzen) bash ./datasets/download_cut_dataset.sh grumpifycat Der Datensatz wird heruntergeladen und entpackt unter ./datasets/grumpifycat/ .
Um Trainingsergebnisse und Verlustplots anzuzeigen, führen Sie python -m visdom.server aus und klicken Sie auf die URL http: // localhost: 8097.
Trainieren Sie das Schnittmodell:
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUTOder trainieren Sie das Fastcut -Modell
python train.py --dataroot ./datasets/grumpifycat --name grumpycat_FastCUT --CUT_mode FastCUT Die Kontrollpunkte werden unter ./checkpoints/grumpycat_*/web gespeichert.
python test.py --dataroot ./datasets/grumpifycat --name grumpycat_CUT --CUT_mode CUT --phase train Die Testergebnisse werden hier in einer HTML -Datei gespeichert: ./results/grumpifycat/latest_train/index.html .
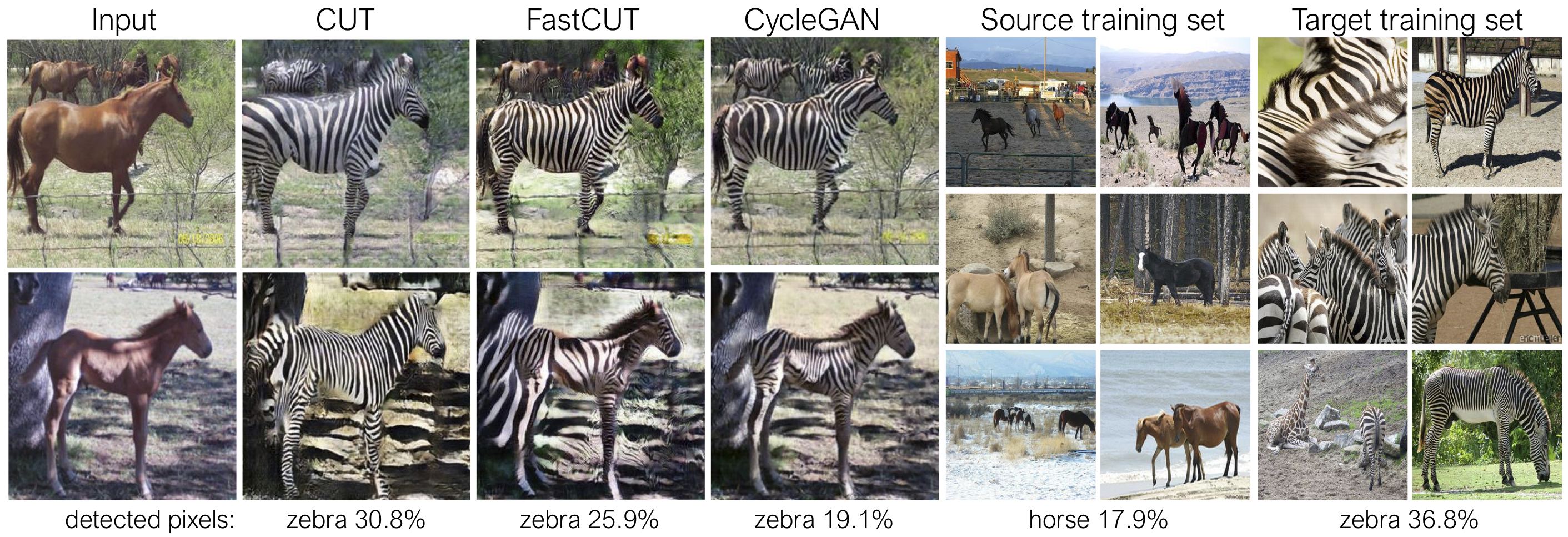
Schnitt wird mit dem Identitäts -Erhaltungsverlust und mit lambda_NCE=1 ausgebildet, während Fastcut ohne den Identitätsverlust trainiert wird, jedoch mit höherem lambda_NCE=10.0 . Im Vergleich zu Cyclegan lernt Cut, leistungsfähigere Verteilungsanpassungen durchzuführen, während Fastcut als leichter (die Hälfte des GPU -Speichers, ein größeres Bild passen kann) und schneller (zweimal schneller zu trainieren) Alternative zu Cyclegan. Weitere Informationen finden Sie in der Zeitung.
In der obigen Abbildung messen wir den Prozentsatz der Pixel, die zu den Pferd/Zebra-Körpern gehören, unter Verwendung eines vorgebildeten semantischen Segmentierungsmodells. Wir finden eine Verteilungsfehlanpassung zwischen Pferdegrößen und Zebrasbildern - Zebras erscheinen normalerweise größer (36,8% gegenüber 17,9%). Unsere vollständige Methode hat die Flexibilität, die Pferde zu vergrößern, um eine bessere Übereinstimmung der Trainingsstatistiken als Cyclegan zu vermitteln. Fastcut verhält sich konservativer wie Cyclegan.
Siehe experiments/grumpifycat_launcher.py die die oben genannten Befehlszeilenargumente generiert. Die Launcher-Skripte sind nützlich, um ziemlich komplizierte Befehlszeilenargumente für Schulungen und Tests zu konfigurieren.
Mit dem Launcher erzeugt der folgende Befehl den Trainingsbefehl von Cut und Fastcut.
python -m experiments grumpifycat train 0 # CUT
python -m experiments grumpifycat train 1 # FastCUTMit dem Launcher zu testen,
python -m experiments grumpifycat test 0 # CUT
python -m experiments grumpifycat test 1 # FastCUT Mögliche Befehle werden ausgeführt, run_test, starten, schließen und so weiter. Bitte beachten Sie experiments/__main__.py für alle Befehle. Der Launcher ist einfach und schnell zu definieren und zu verwenden. Zum Beispiel ist der GrumpifyCat -Launcher in einigen Zeilen definiert:
from . tmux_launcher import Options , TmuxLauncher
class Launcher ( TmuxLauncher ):
def common_options ( self ):
return [
Options ( # Command 0
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_CUT" ,
CUT_mode = "CUT"
),
Options ( # Command 1
dataroot = "./datasets/grumpifycat" ,
name = "grumpifycat_FastCUT" ,
CUT_mode = "FastCUT" ,
)
]
def commands ( self ):
return [ "python train.py " + str ( opt ) for opt in self . common_options ()]
def test_commands ( self ):
# Russian Blue -> Grumpy Cats dataset does not have test split.
# Therefore, let's set the test split to be the "train" set.
return [ "python test.py " + str ( opt . set ( phase = 'train' )) for opt in self . common_options ()]Um die vorbereiteten Modelle auszuführen, führen Sie Folgendes aus.
# Download and unzip the pretrained models. The weights should be located at
# checkpoints/horse2zebra_cut_pretrained/latest_net_G.pth, for example.
wget http://efrosgans.eecs.berkeley.edu/CUT/pretrained_models.tar
tar -xf pretrained_models.tar
# Generate outputs. The dataset paths might need to be adjusted.
# To do this, modify the lines of experiments/pretrained_launcher.py
# [id] corresponds to the respective commands defined in pretrained_launcher.py
# 0 - CUT on Cityscapes
# 1 - FastCUT on Cityscapes
# 2 - CUT on Horse2Zebra
# 3 - FastCUT on Horse2Zebra
# 4 - CUT on Cat2Dog
# 5 - FastCUT on Cat2Dog
python -m experiments pretrained run_test [id]
# Evaluate FID. To do this, first install pytorch-fid of https://github.com/mseitzer/pytorch-fid
# pip install pytorch-fid
# For example, to evaluate horse2zebra FID of CUT,
# python -m pytorch_fid ./datasets/horse2zebra/testB/ results/horse2zebra_cut_pretrained/test_latest/images/fake_B/
# To evaluate Cityscapes FID of FastCUT,
# python -m pytorch_fid ./datasets/cityscapes/valA/ ~/projects/contrastive-unpaired-translation/results/cityscapes_fastcut_pretrained/test_latest/images/fake_B/
# Note that a special dataset needs to be used for the Cityscapes model. Please read below.
python -m pytorch_fid [path to real test images] [path to generated images]
HINWEIS: Das vorgezogene Modell von Cityscapes wurde geschult und in einer geeigneten und von JPEG-komprimierten Version des ursprünglichen Cityscapes-Datensatzes ausgewertet. Um die Bewertung durchzuführen, laden Sie bitte diesen Validierungssatz herunter und führen Sie die Bewertung durch.
Um Sincut zu trainieren (Ein-Image-Translation, in Abb. 9, 13 und 14 des Papiers gezeigt), müssen Sie
--model als --model sincut fest, der die Konfiguration und Codes unter ./models/sincut_model.py und aufrufen, und./datasets/single_image_monet_etretat/ .Um beispielsweise ein Modell für die ETRETAT -Klippe zu trainieren (erste Bild von Abbildung 13), verwenden Sie bitte den folgenden Befehl.
python train.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatoder durch Verwendung des Experiment -Launcher -Skripts,
python -m experiments singleimage run 0 Für die Übersetzung von Einzelbildnetzwerken übernehmen wir Netzwerkarchitekturkomponenten von Stylegan2 sowie den in DTN und Cyclegan verwendeten Pixel-Identitäts-Erhaltungsverlust. Insbesondere haben wir den Code of Rosinalität übernommen, der bei models/stylegan_networks.py vorhanden ist.
Das Training dauert mehrere Stunden. Um das endgültige Bild mit dem Checkpoint zu generieren,
python test.py --model sincut --name singleimage_monet_etretat --dataroot ./datasets/single_image_monet_etretatoder einfach
python -m experiments singleimage run_test 0Laden Sie Cut/Cyclegan/PIX2Pix -Datensätze herunter. Zum Beispiel,
bash datasets/download_cut_datasets.sh horse2zebra Der CAT2DOG -Datensatz wird aus dem AFHQ -Datensatz erstellt. Bitte besuchen Sie https://github.com/clovaai/stargan-v2 und laden Sie den AFHQ-Datensatz von bash download.sh afhq-dataset des github repo herunter. Dann organisieren Sie Verzeichnisse wie folgt.
mkdir datasets/cat2dog
ln -s datasets/cat2dog/trainA [path_to_afhq]/train/cat
ln -s datasets/cat2dog/trainB [path_to_afhq]/train/dog
ln -s datasets/cat2dog/testA [path_to_afhq]/test/cat
ln -s datasets/cat2dog/testB [path_to_afhq]/test/dog Der CityScapes-Datensatz kann von https://cityscapes-dataset.com heruntergeladen werden. Verwenden Sie danach das Skript ./datasets/prepare_cityscapes_dataset.py um den Datensatz vorzubereiten.
Die Vorverarbeitung der Eingabebilder wie die Größe oder das zufällige Zuschneiden wird durch die Option gesteuert --preprocess , --load_size und --crop_size . Die Verwendung folgt dem Cyclegan/PIX2PIX -Repo.
Beispielsweise ist die Standardeinstellung --preprocess resize_and_crop --load_size 286 --crop_size 256 Das Eingabebild auf 286x286 und dann eine zufällige Ernte von Größe 256x256 als eine Möglichkeit zur Durchführung von Datenvergrößerung heran. Es gibt andere Vorverarbeitungsoptionen, die angegeben werden können, und sie werden in Base_dataset.py angegeben. Im Folgenden finden Sie einige Beispieloptionen.
--preprocess none : Führen Sie keine Vorverarbeitung durch. Beachten Sie, dass die Bildgröße immer noch zu einem nächstgelegenen Mehrfachen von 4 skaliert ist, da der Faltungsgenerator sonst nicht die gleiche Bildgröße beibehalten kann.--preprocess scale_width --load_size 768 : Skaliert die Breite des Bildes, die von Größe 768 beträgt.--preprocess scale_shortside_and_crop : Skaliert das Bildunterhaltungsverhältnis, so dass die kurze Seite load_size ist und dann zufällige Anbaus der crop_size durchführt. Weitere Vorverarbeitungsoptionen können hinzugefügt werden, indem get_transform() von base_dataset.py geändert wird.
Wenn Sie diesen Code für Ihre Forschung verwenden, zitieren Sie bitte unser Papier.
@inproceedings{park2020cut,
title={Contrastive Learning for Unpaired Image-to-Image Translation},
author={Taesung Park and Alexei A. Efros and Richard Zhang and Jun-Yan Zhu},
booktitle={European Conference on Computer Vision},
year={2020}
}
Wenn Sie das in diesem Repo enthaltene Original -PIX2PIX- und Cyclegan -Modell verwenden, zitieren Sie bitte die folgenden Papiere
@inproceedings{CycleGAN2017,
title={Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks},
author={Zhu, Jun-Yan and Park, Taesung and Isola, Phillip and Efros, Alexei A},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2017}
}
@inproceedings{isola2017image,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}
Wir danken Allan Jabri und Phillip Isola für hilfreiche Diskussionen und Feedback. Unser Code basiert auf Pytorch-Cyclegan-and-Pix2Pix. Wir danken auch Pytorch-Fid für FID-Berechnung, DRN für die Miou-Berechnung und Stylegan2-Pytorch für die Pytorch-Implementierung von Stylegan2, die in unserer Einstellung zur Übersetzung von Single-Image verwendet wird.


