knn search algorithm comparison
1.0.0
อัลกอริทึมเพื่อนบ้าน K-Nearest (K-NN) ซึ่งเปิดตัวในปี 1951 ได้ถูกนำมาใช้อย่างกว้างขวางสำหรับการจำแนกประเภทและงานการถดถอย แนวคิดหลักเกี่ยวข้องกับการระบุอินสแตนซ์ที่คล้ายกันมากที่สุด K (เพื่อนบ้าน) ไปยังจุดค้นหาที่กำหนดภายในชุดข้อมูลและการใช้เพื่อนบ้านเหล่านี้เพื่อทำการคาดการณ์หรือการจำแนกประเภท ในช่วงไม่กี่ปีที่ผ่านมาความสำคัญของฐานข้อมูลเวกเตอร์และดัชนีเวกเตอร์ได้เพิ่มขึ้นโดยเฉพาะอย่างยิ่งสำหรับการดึงข้อมูลเพื่อรองรับแบบจำลองภาษาขนาดใหญ่ (LLMS) ในการประมวลผลชุดข้อมูลที่กว้างขวางของข้อความและข้อมูลอื่น ๆ ตัวอย่างที่โดดเด่นของแอปพลิเคชันนี้คือการเรียกคืนการเพิ่มขึ้น (RAG)
โครงการนี้เปรียบเทียบประสิทธิภาพของอัลกอริทึมการค้นหา K-NN ที่แตกต่างกันในขนาดและขนาดชุดข้อมูลต่างๆ อัลกอริทึมที่เปรียบเทียบคือ:
KD-Tree (K-dimensional Tree):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
คะแนน: A (1,3), B (3,1), C (4,3), D (3,3) โครงสร้างต้นไม้: รูท (x = 2) -> ซ้าย (y = 2) -> ขวา (x = 3)
ต้นไม้บอล:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
วงกลมด้านนอกมีทุกจุดวงกลมด้านในแบ่งส่วนย่อย
เต็ม knn (กองกำลังดุร้าย):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
คำนวณระยะทาง: QA = 1.41, QB = 1, QC = 2.24, QD = 1.41 ผลลัพธ์: เพื่อนบ้านที่ใกล้ที่สุด 2 คนคือ B และ A (หรือ D)
HNSW (โลกขนาดเล็กที่นำทางได้ตามลำดับชั้น):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
การค้นหาเริ่มต้นที่จุดสุ่มในชั้นบนสุดและลงมาสำรวจเพื่อนบ้านในแต่ละระดับจนกระทั่งถึงด้านล่าง
ตัวเลือกระหว่างอัลกอริทึมเหล่านี้ขึ้นอยู่กับขนาดชุดข้อมูลมิติความแม่นยำที่ต้องการและความเร็วในการสืบค้น KD-Tree และ Ball Tree ให้ผลลัพธ์ที่แน่นอนและมีประสิทธิภาพสำหรับมิติต่ำถึงปานกลาง Full KNN นั้นง่าย แต่ช้าสำหรับชุดข้อมูลขนาดใหญ่ HNSW นำเสนอความสมดุลที่ดีระหว่างความเร็วและความแม่นยำโดยเฉพาะอย่างยิ่งสำหรับข้อมูลมิติสูงหรือชุดข้อมูลขนาดใหญ่
โคลนที่เก็บนี้:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
สร้างสภาพแวดล้อมเสมือนจริง (เป็นทางเลือก แต่แนะนำ):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
ติดตั้งการพึ่งพาที่ต้องการ:
pip install -r requirements.txt
สิ่งนี้จะติดตั้งแพ็คเกจที่จำเป็นทั้งหมดที่ระบุไว้ในไฟล์ requirements.txt txt รวมถึง numpy, scipy, scikit-learn, hnswlib, tabulate และ tqdm
ในการเรียกใช้การทดสอบเปรียบเทียบกับพารามิเตอร์เริ่มต้น:
python app.py
นอกจากนี้คุณยังสามารถปรับแต่งพารามิเตอร์ทดสอบโดยใช้อาร์กิวเมนต์บรรทัดคำสั่ง:
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
ข้อโต้แย้งที่มีอยู่:
--vectors : รายการของเวกเตอร์นับเพื่อทดสอบ (ค่าเริ่มต้น: 1,000, 2000, 5000, 10,000, 100000, 20000, 50000, 100000, 200000)--dimensions : รายการมิติที่จะทดสอบ (ค่าเริ่มต้น: 4 16 256 1024)--num-tests : จำนวนการทดสอบที่จะเรียกใช้สำหรับแต่ละชุดค่าผสม (ค่าเริ่มต้น: 10)--k : จำนวนเพื่อนบ้านที่ใกล้ที่สุดในการค้นหา (ค่าเริ่มต้น: 10)สคริปต์จะแสดงแถบความคืบหน้าในระหว่างการดำเนินการเพื่อให้คุณประมาณเวลาที่เหลือ
สคริปต์สามารถถูกขัดจังหวะได้ตลอดเวลาโดยกด Ctrl+c มันจะพยายามที่จะออกอย่างสง่างามแม้ในระหว่างการดำเนินงานที่ใช้เวลานานเช่นการสร้างดัชนี HNSW
สคริปต์จะแสดงความคืบหน้าและผลลัพธ์ในคอนโซล หลังจากเสร็จสิ้นคุณจะเห็น:
ตัวอย่างเอาต์พุตสำหรับชุดรวมเดียว:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
ตารางผลลัพธ์สุดท้ายและไฟล์ CSV จะรวมทั้งเวลาสร้างและเวลาการค้นหาสำหรับแต่ละอัลกอริทึมเพื่อให้สามารถเปรียบเทียบประสิทธิภาพที่ครอบคลุมในการนับและมิติที่แตกต่างกัน
คุณสามารถแก้ไขตัวแปรต่อไปนี้ใน app.py เพื่อปรับพารามิเตอร์ทดสอบ:
NUM_VECTORS_LIST : รายการของเวกเตอร์นับเป็นทดสอบNUM_DIMENSIONS_LIST : รายการมิติที่จะทดสอบNUM_TESTS : จำนวนการทดสอบที่จะทำงานสำหรับแต่ละชุดค่าผสมK : จำนวนเพื่อนบ้านที่ใกล้ที่สุดในการค้นหา ยินดีต้อนรับ! โปรดส่งคำขอดึง
โครงการนี้เป็นโอเพ่นซอร์สและมีอยู่ภายใต้ใบอนุญาต MIT
ด้านล่างเป็นแผนภูมิที่แสดงผลการค้นหา KNN:
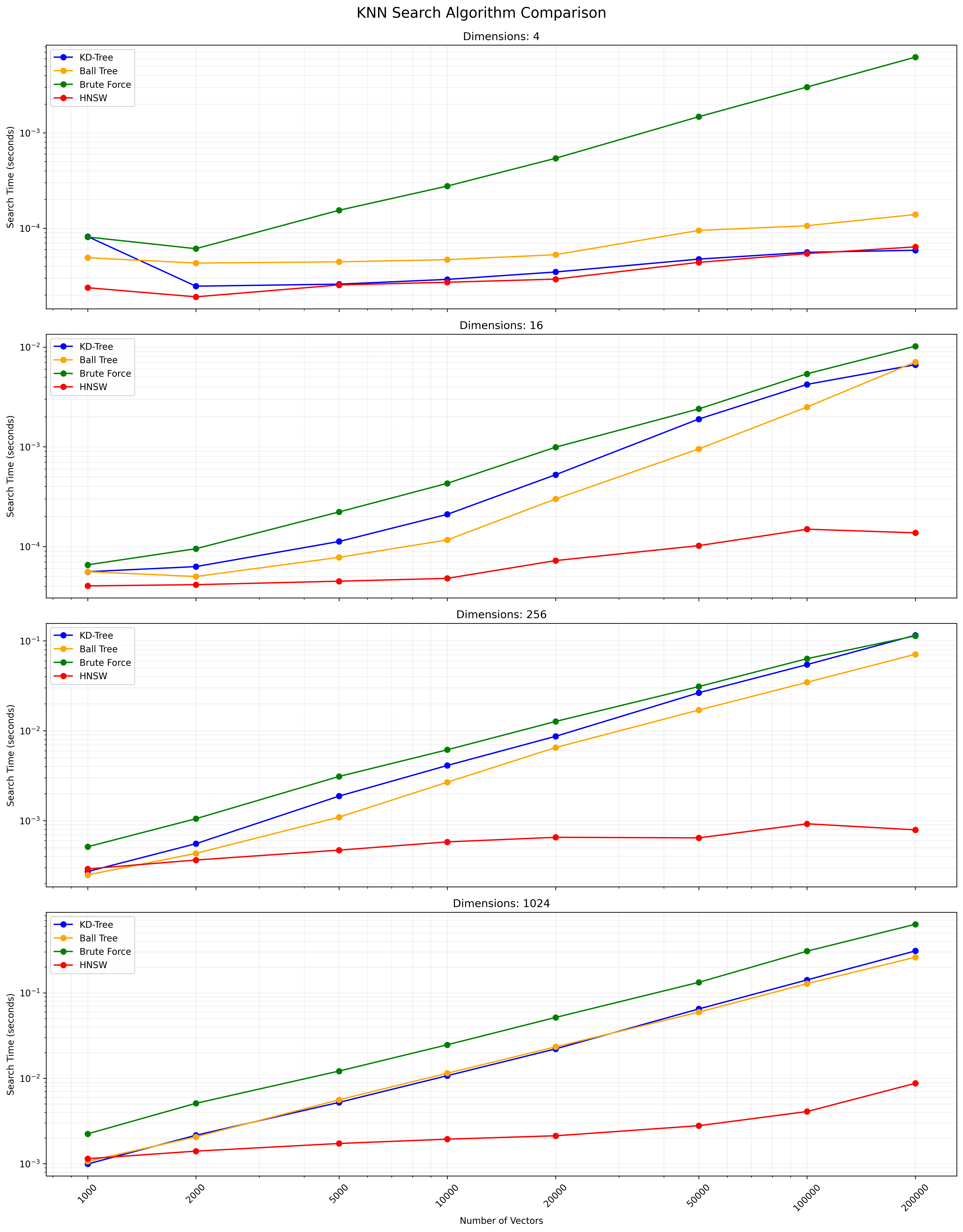
ไฟล์ CSV ที่มีผลลัพธ์โดยละเอียดมีอยู่ที่นี่


