knn search algorithm comparison
1.0.0
Алгоритм K-ближайших соседей (K-NN), введенный в 1951 году, широко использовался как для задач классификации, так и для регрессии. Основная концепция включает в себя идентификацию k наиболее похожих экземпляров (соседей) до заданной точки запроса в наборе данных и использование этих соседей для прогнозирования или классификаций. В последние годы важность векторных баз данных и векторных индексов выросла, особенно для поиска информации для поддержки моделей крупных языков (LLMS) в обработке обширных наборов данных текста и других данных. Выдающимся примером этого приложения является поколение поиска (RAG).
Этот проект сравнивает производительность различных алгоритмов поиска K-NN в различных размерах и размерах набора данных. Сравненные алгоритмы:
KD-Tree (k-мерное дерево):
y
|
4 | C
| A D
2 | B
|___________
0 2 4 x
Точки: A (1,3), B (3,1), C (4,3), D (3,3) Структура дерева: корень (x = 2) -> слева (y = 2) -> справа (x = 3)
Мяч дерево:
y
|
4 | (C)
| (A) (D)
2 | (B)
|___________
0 2 4 x
Внешний круг содержит все точки, внутренние круги делят подмножества.
Full Knn (грубая сила):
y
|
4 | C
| A D
2 |----Q--B
|___________
0 2 4 x
Рассчитайте расстояния: QA = 1,41, QB = 1, QC = 2,24, QD = 1,41 Результат: ближайшие 2 соседи - B и A (или D)
HNSW (иерархический судоходный маленький мир):
Layer 2: A --- C
|
Layer 1: A --- B --- C
| | |
Layer 0: A --- B --- C --- D --- E
Поиск начинается в случайной точке в верхнем слое и спускается, исследуя соседей на каждом уровне до достижения дна.
Выбор между этими алгоритмами зависит от размера набора данных, размерности, необходимой точности и скорости запроса. KD-дерево и шаровое дерево обеспечивают точные результаты и эффективны для размеров низкого и умеренного. Полный KNN прост, но становится медленным для больших наборов данных. HNSW предлагает хороший баланс между скоростью и точностью, особенно для высокомерных данных или больших наборов данных.
Клонировать это хранилище:
git clone https://github.com/yourusername/knn-search-comparison.git
cd knn-search-comparison
Создайте виртуальную среду (необязательно, но рекомендуется):
python -m venv venv
source venv/bin/activate # On Windows, use `venvScriptsactivate`
Установите требуемые зависимости:
pip install -r requirements.txt
Это установит все необходимые пакеты, перечисленные в файле requirements.txt , включая Numpy, Scipy, Scikit-Learn, Hnswlib, Tabulate и TQDM.
Чтобы запустить сравнительные тесты с параметрами по умолчанию:
python app.py
Вы также можете настроить параметры тестирования, используя аргументы командной строки:
python app.py --vectors 1000 10000 100000 --dimensions 4 16 256 --num-tests 5 --k 5
Доступные аргументы:
--vectors : список векторных подсчетов для тестирования (по умолчанию: 1000, 2000, 5000, 10000, 20000, 50000, 100000, 200000)--dimensions : список измерений для тестирования (по умолчанию: 4 16 256 1024)--num-tests : количество тестов для выполнения для каждой комбинации (по умолчанию: 10)--k : количество ближайших соседей для поиска (по умолчанию: 10)Сценарий будет отображать панель хода хода выполнения во время исполнения, давая вам оценку оставшегося времени.
Сценарий может быть прерван в любое время, нажав Ctrl+c. Он попытается выйти изящно, даже во время трудоемких операций, таких как создание индекса HNSW.
Сценарий будет отображать прогресс и приведет к консоли. После завершения вы увидите:
Пример вывода для одной комбинации:
Results for 10000 vectors with 256 dimensions:
KD-Tree build time: 0.123456 seconds
Ball Tree build time: 0.234567 seconds
HNSW build time: 0.345678 seconds
KD-Tree search time: 0.001234 seconds
Ball Tree search time: 0.002345 seconds
Brute Force search time: 0.012345 seconds
HNSW search time: 0.000123 seconds
Окончательная таблица результатов и файл CSV будут включать как время сборки, так и время поиска для каждого алгоритма, что позволяет провести всестороннее сравнение производительности по различным векторным количествам и размерам.
Вы можете изменить следующие переменные в app.py , чтобы настроить параметры тестирования:
NUM_VECTORS_LIST : список векторных счетов для тестированияNUM_DIMENSIONS_LIST : список измерений для тестированияNUM_TESTS : количество тестов для выполнения для каждой комбинацииK : Количество ближайших соседей для поиска Взносы приветствуются! Пожалуйста, не стесняйтесь отправить запрос на привлечение.
Этот проект является открытым исходным кодом и доступен по лицензии MIT.
Ниже приведена диаграмма, показывающая результаты поиска KNN:
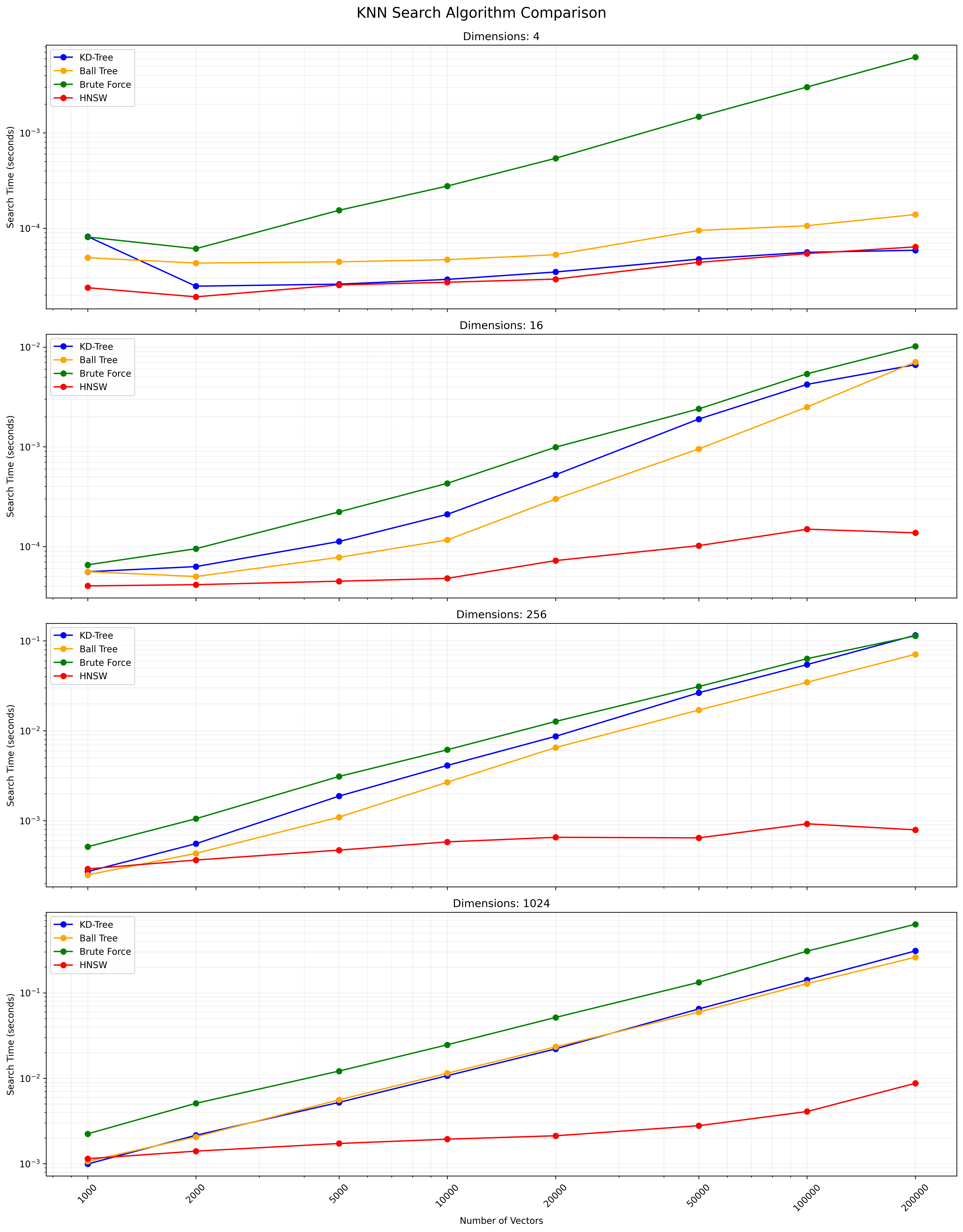
Файл CSV, содержащий подробные результаты, доступен здесь.


